-
-

Goals for the day
-

Mapping out productionization
-

Ajmal lending his expertise with the Iress engineers
-

About 8pm on day 1
-
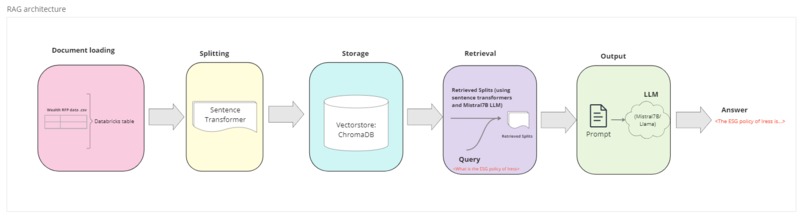
RAG architecture
-
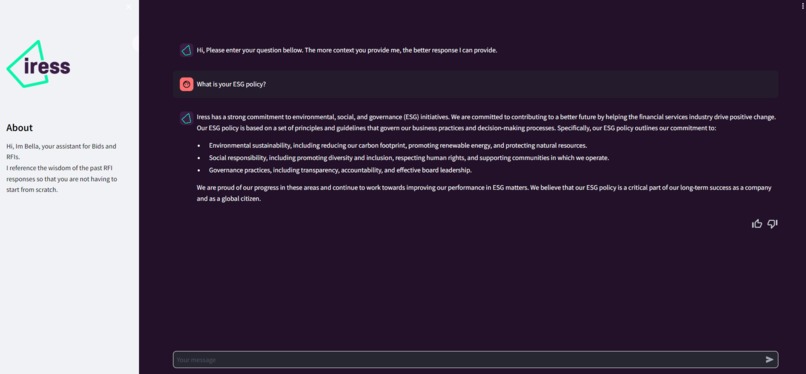
Bella UI






Inspiration
We wanted to show the broader business that we can build useful generative AI applications within our own environment. We did some POCs using OpenAI however there were concerns around security and privacy for our customers and staff. We brainstormed between the Head of Business Intelligence, Head of Data Science and our Databricks solution architects what project we could tackle. A theme that kept coming up from our business units was allowing an LLM to provide better baseline RFP responses. This satisfied the criteria of being feasible (there already are RAG patterns we could use) and high value (as it will be useful to senior stakeholders in the business).
After our people conference where people came together from all over APAC we coordinated to do a 2 day hackathon. We prepped by collecting the sample data and set up the environments to get hacking between Wednesday 1st of December and Thursday the 2nd of December.
We developed the following solution guidelines for the chatbot development:
- To build an LLM to simplify and speed up the RFP process for Iress, by producing professional, accurate outputs of defined length and tone.
- To ensure no data leaves our ecosystem.
- To utilize Databricks platform for data governance and AWS resources to store raw data.
- For each output to reference the source of data it utilized.
- To be able to quickly assess the accuracy of the outputs and provide feedback to the model.
Additional goals
- Create a pattern architecture we could re-use for other implementations.
- Create a cost to serve dashboard to help inform the business of the cost of hosting this model.
- Increase collaboration between business units.
- Improve baseline understanding of generative AI from participants and key stakeholders.
What it does
Bella is a chatbot that takes in RFP questions and provides an answer from Iress. A RAG pattern is used to retrieve relevant responses from previous RFPs and then parse it through a prompt that then uses the context to provide an answer. There is also an endpoint that is provided. This can be used when you want to provide answers at scale, say create a draft response over a whole documents questions.
How we built it
We had 3 engineers and we got invaluable help from Ajmal at Databricks as well. We split the team into the ingestion, chunking/model and UI parts. We had one engineer also build out a cost to serve dashboard.
We all got together on day 1 and spent the first morning understanding the problem and defining goals. We brought people from the commercial team in to give more insight and they were helpful to give context and refine the prompt we used in the model.
For data we got over 6000 Q&A pairs of historical RFP questions. The 6000 rows of raw data exists in a csv file and consists of former responses to RFP questions. The file contains data on client name, question, date of RFP, short answer, comments (long answer). We ingested the question and answer pair into a Databricks table which is accessed by a Sentence Transformer to chunk and then create embeddings for the data.
For the prototype RFP LLM we used Mistral-7B-Instruct. The Mistral-7B-Instruct-v0.1 Large Language Model (LLM) is a instruct fine-tuned version of the Mistral-7B-v0.1 generative text model using a variety of publicly available conversation datasets. The alternative LLMs suitable for developing the RFP LLM are the Falcon and the LLaMa-7B (built by Meta AI). We added a Lambda function to enable us to switch easily between models. We ended up hosting endpoints of both the Mistral and Llama-7B models.
Our intention was to use Databricks for enablement and governance, and AWS for storage and compute. The data and model operates in a closed environment meaning no data is available externally.
We used streamlit as a lightweight UI. We did some work after the initial hackathon to host this in our environment on AWS. The model ingests the prompt via the UI and the ‘chunked’ data is received from a Chroma Vector DB.
Challenges we ran into
- Creating a vectorDB. We had ingestion issues and had to switch our approach.
- To enable us to reference the source data in the UI we needed to re-architect the model.
- The streamlit UI is hosted externally. To complete our goals we wanted to host the end-to-end project internally.
Accomplishments that we're proud of
It's fully hosted in our environment. This includes the streamlit app. We got it working with very low baseline knowledge of open-source models and how to use it within Databricks. It was a team effort across many internal teams but also made possible with the support of Databricks.
What we learned
There is a lot more thought that needs to be put into an open-source model's design and thinking through the design trade-offs before you want to make it available to users - as compared to proprietary models. We want to build our people's capabilities in this space to enable the business to create more useful applications that are secure. We'd like to do more within Databricks to host secure and private chatbots.
What's next for Bella: A LLM for responding to RFPs
The next steps needed are:
- Finalising the metrics and documentation
- Further testing including on a recently received RFP
- Running a retro of the experiment
- Grooming the backlog/roadmap to production readiness.
- More investigations into the benefits of using proprietary models like those provided by OpenAI on Databricks.
What an incredible achievement in such a short space of time, proving what can be accomplished when a talented group of people collaborate and get laser-focused on a problem to solve. Well done to the team involved, who all played a part in getting to the end goal.
Built With
- amazon-web-services
- chroma
- databricks
- falcon
- lambda
- llama-7b
- mistral
- python
- sentence-transformers
- streamlit


Log in or sign up for Devpost to join the conversation.