-
-
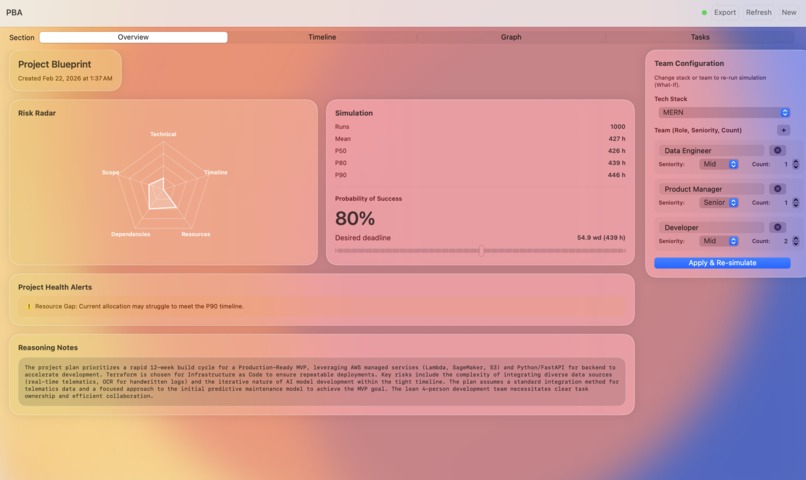
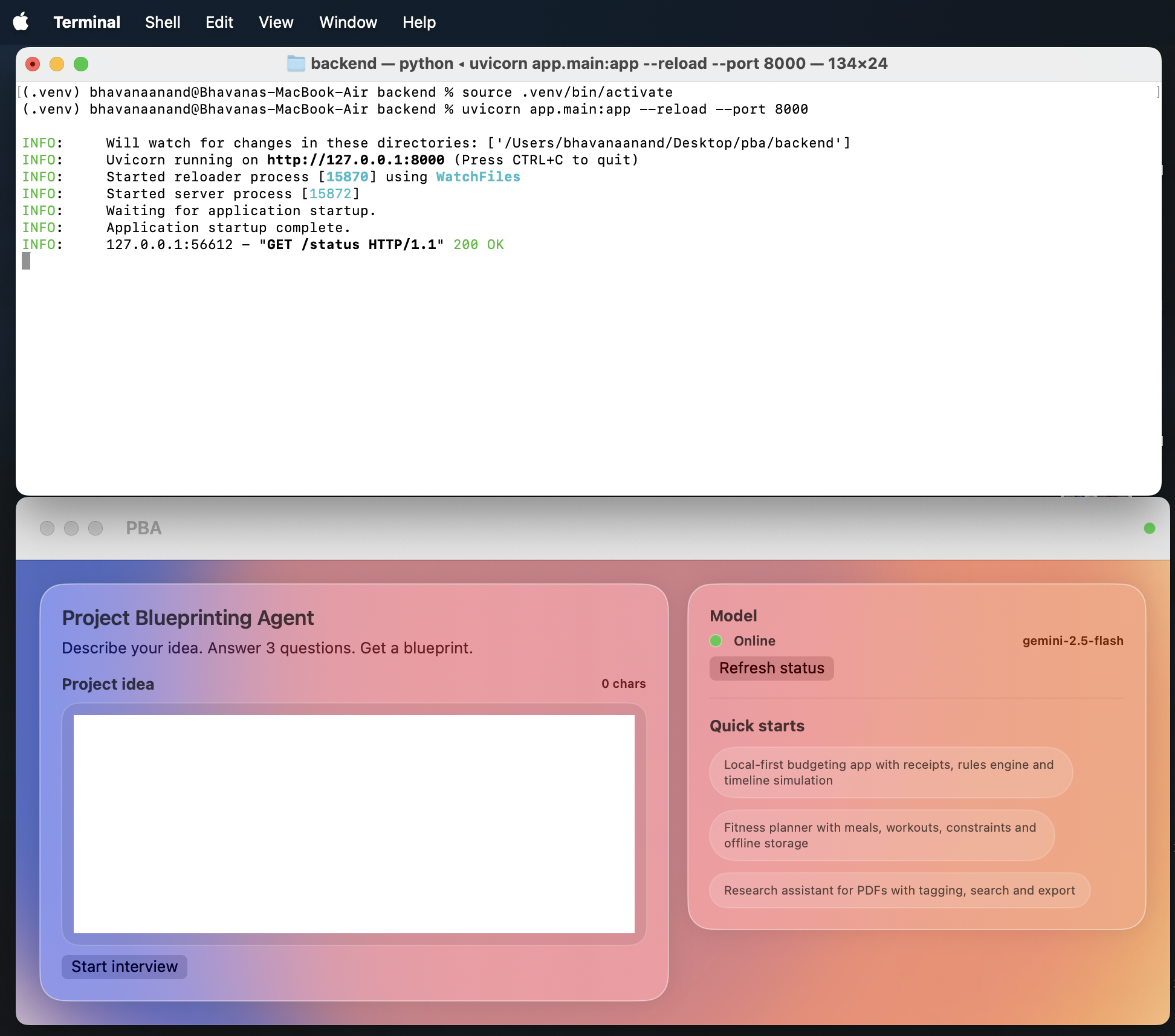
Blueprint Dashboard Page
-
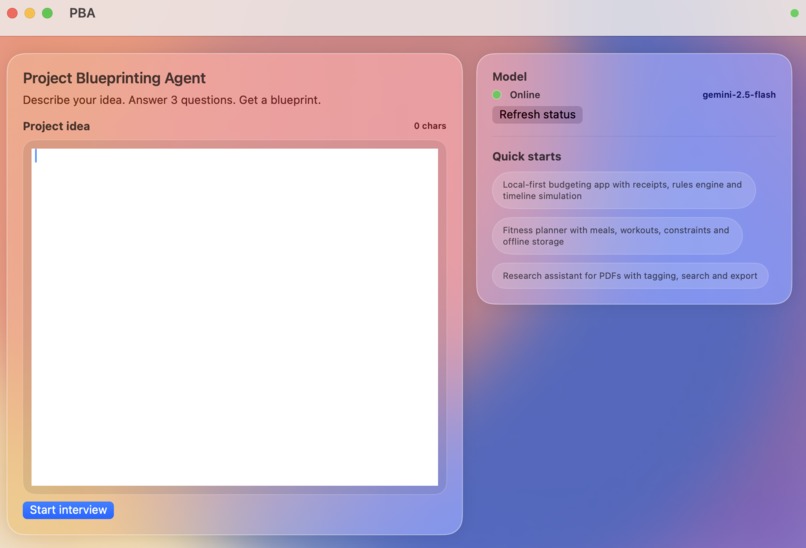
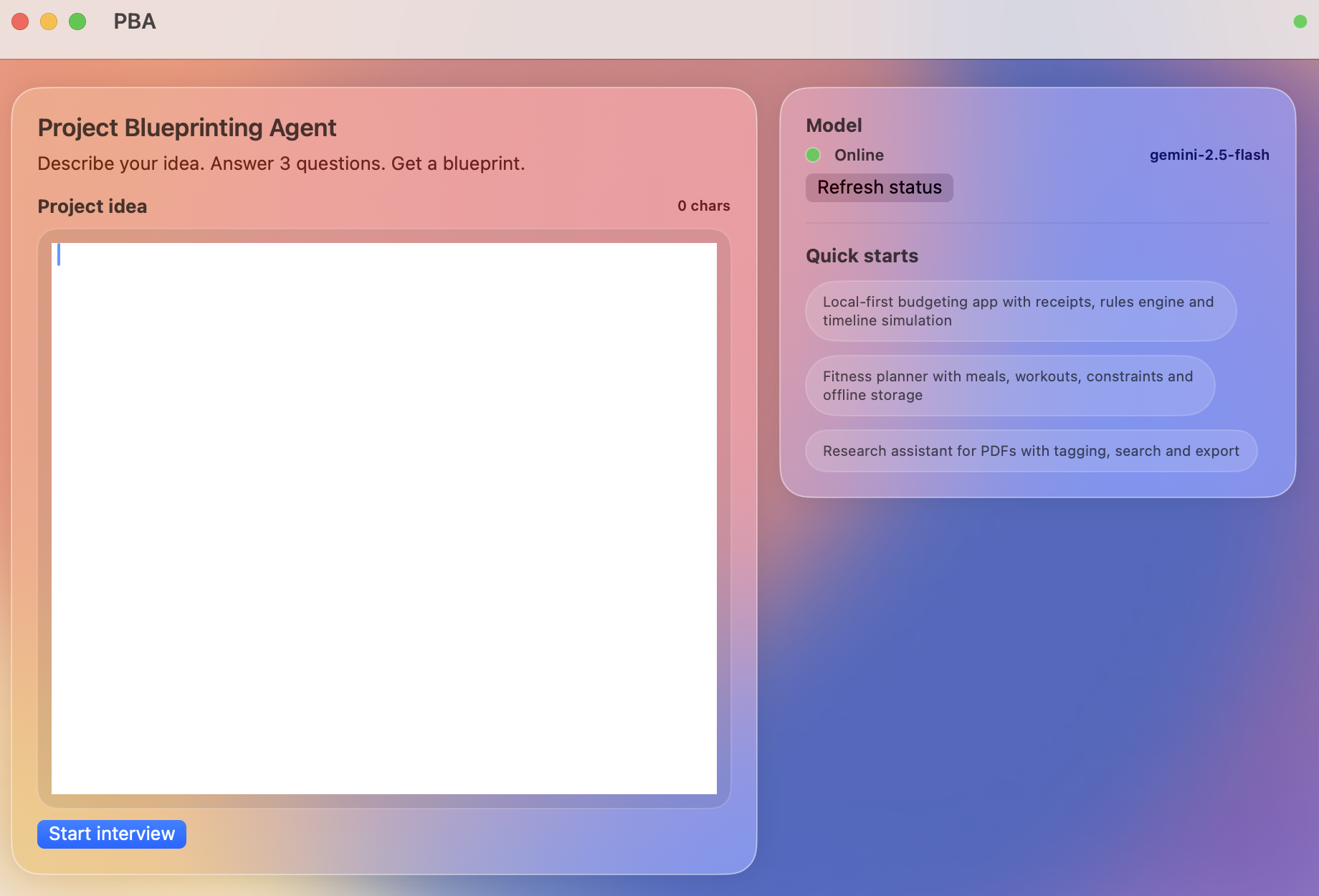
Landing Page
-
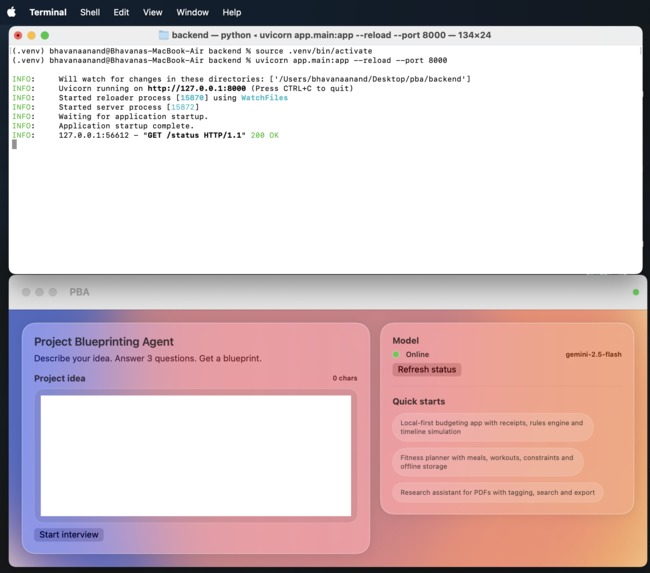
Frontend + Backend Integrated
-
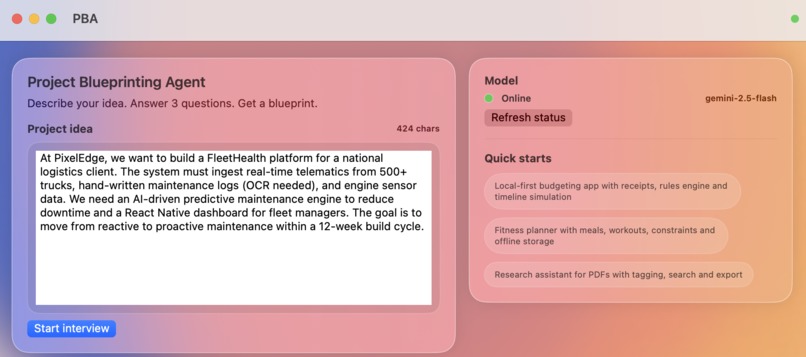
Test Case Demo
-
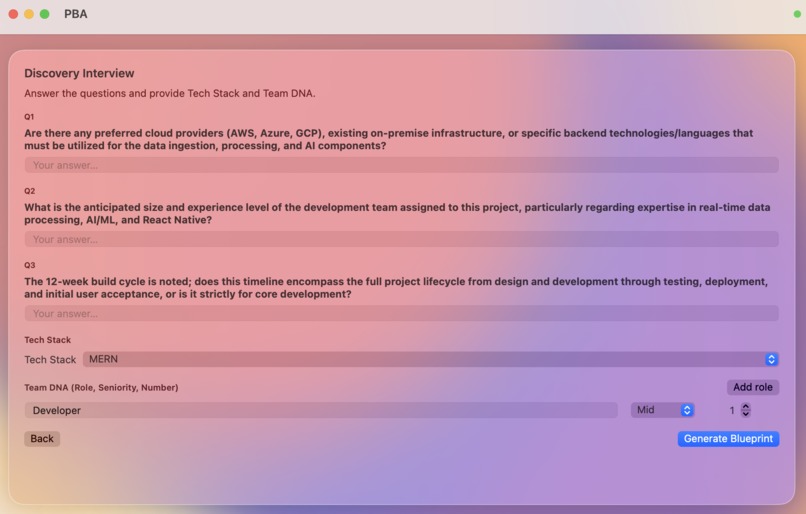
Project-based QA page
-
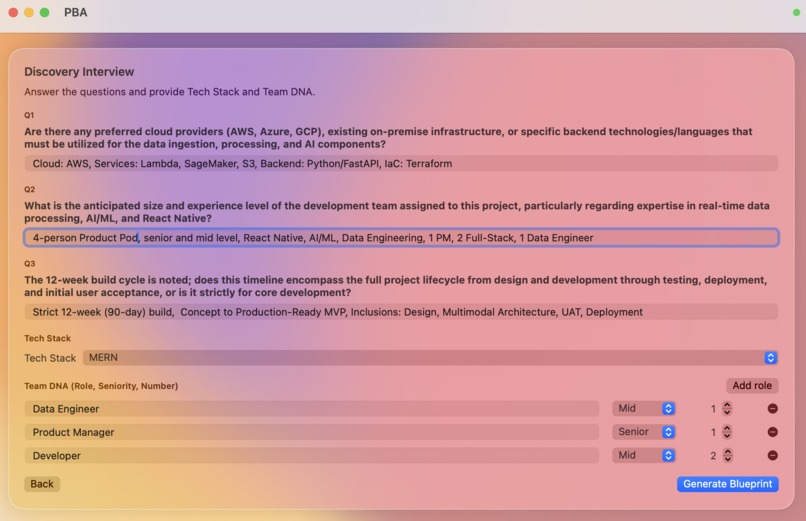
Test case based Gemini generated QA
-
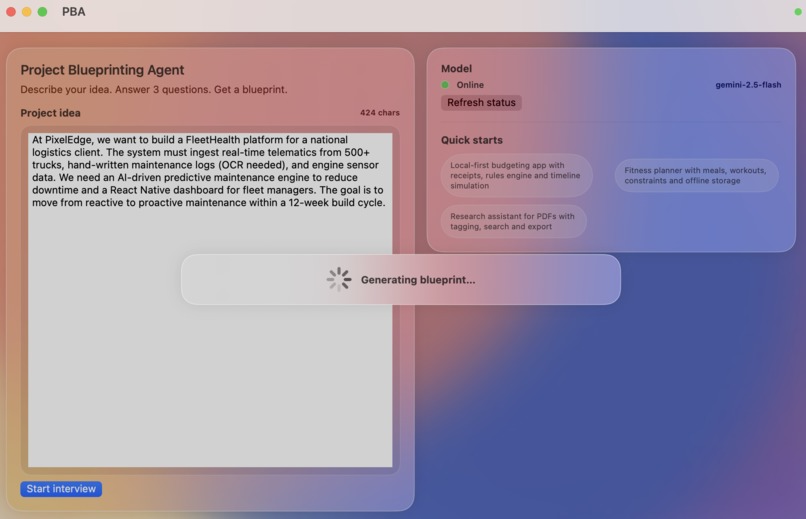
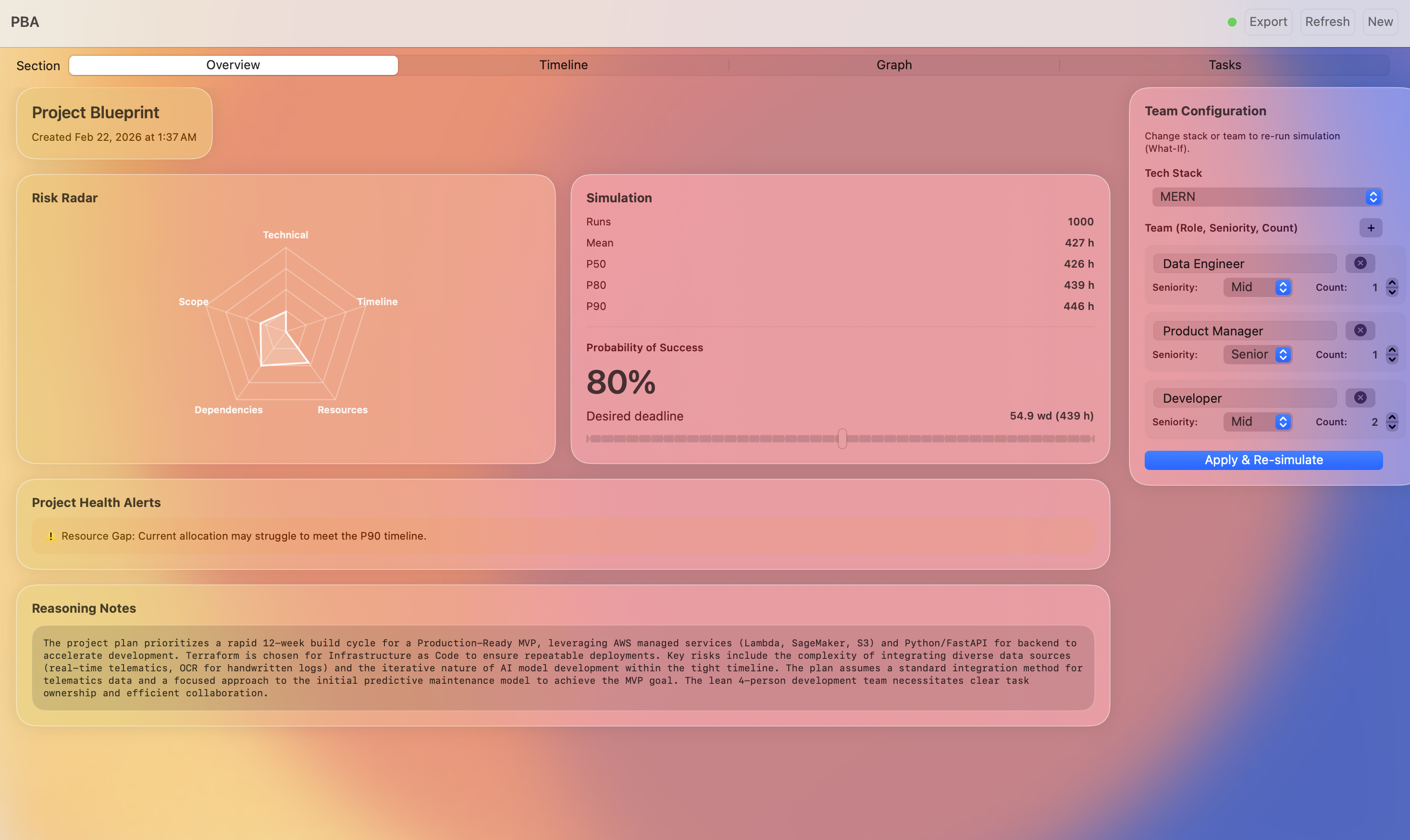
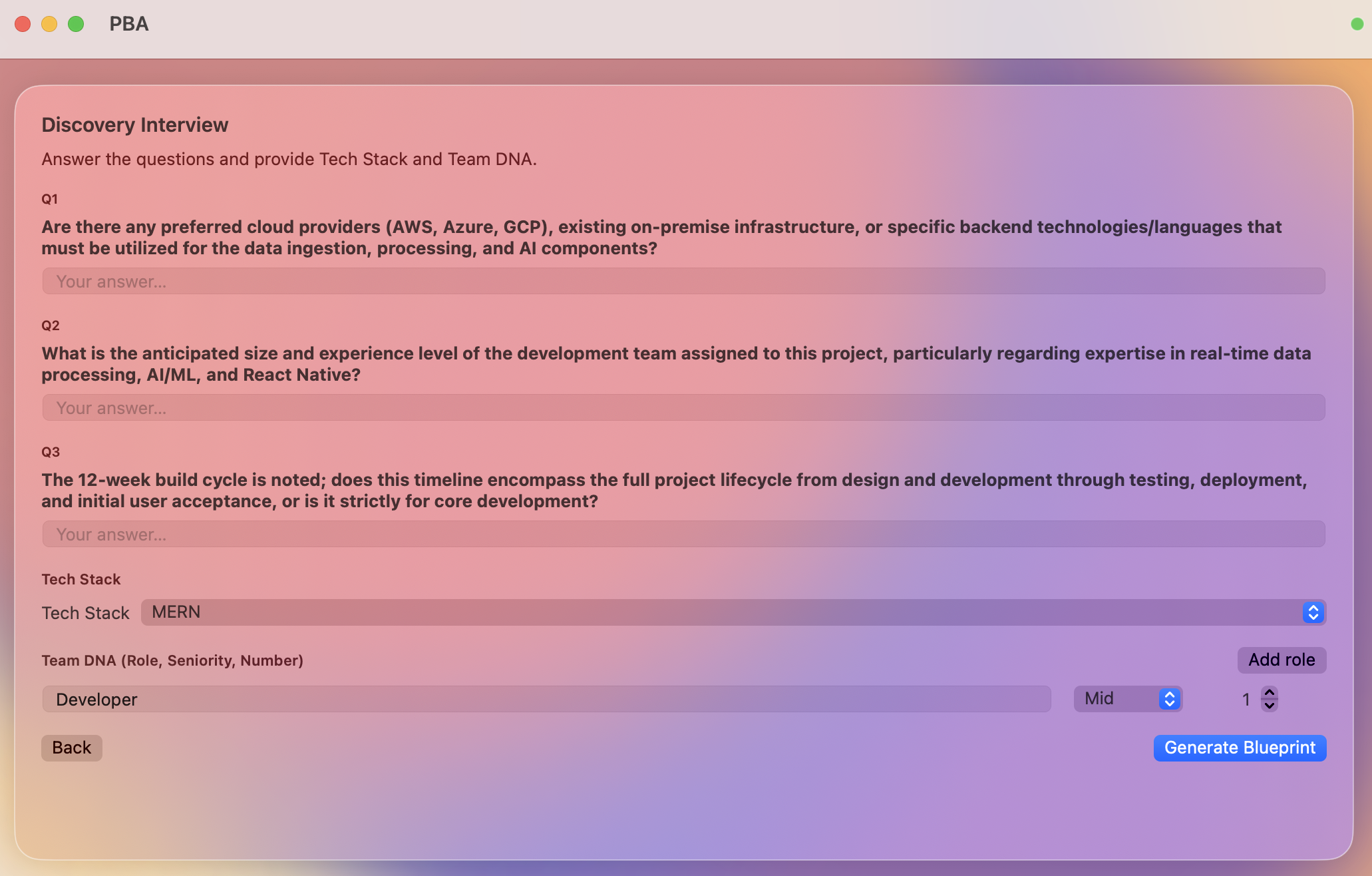
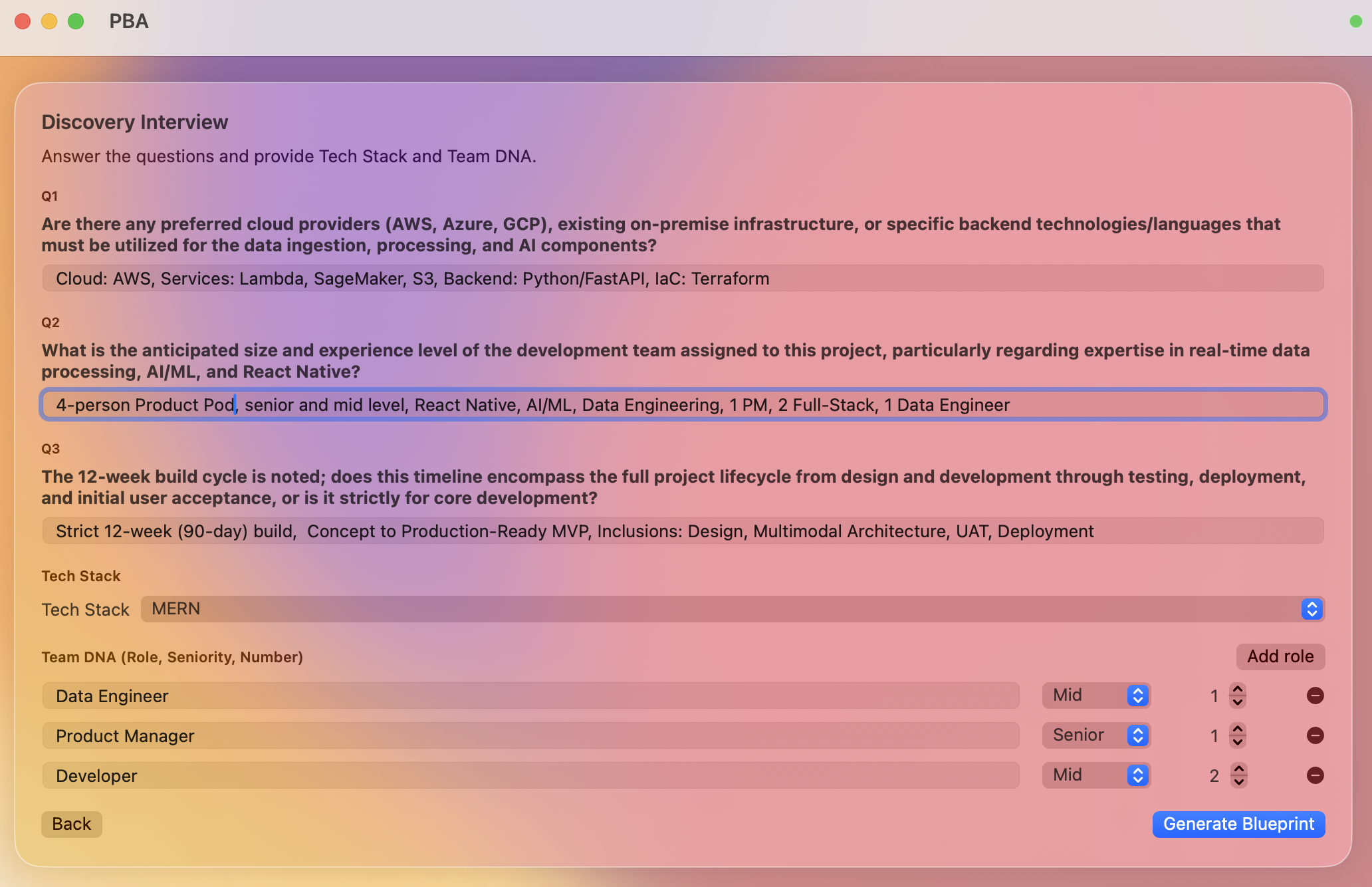
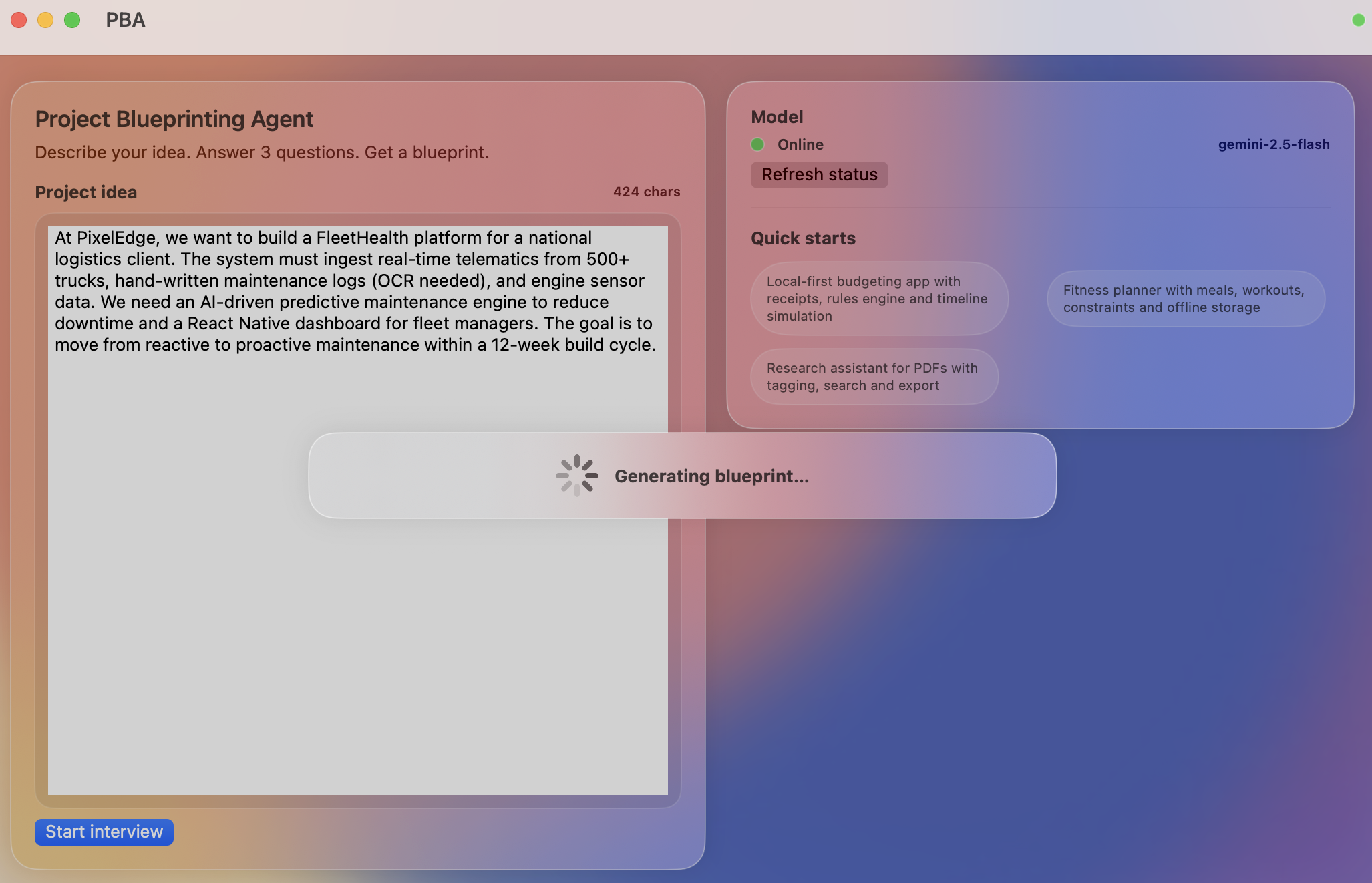
Blueprint generation
-
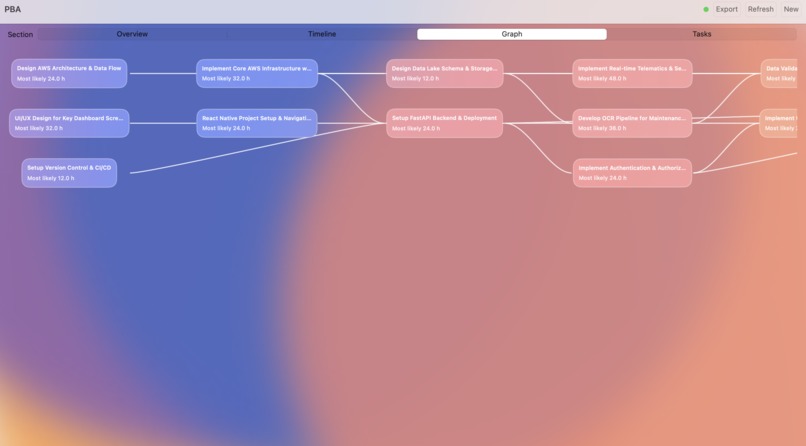
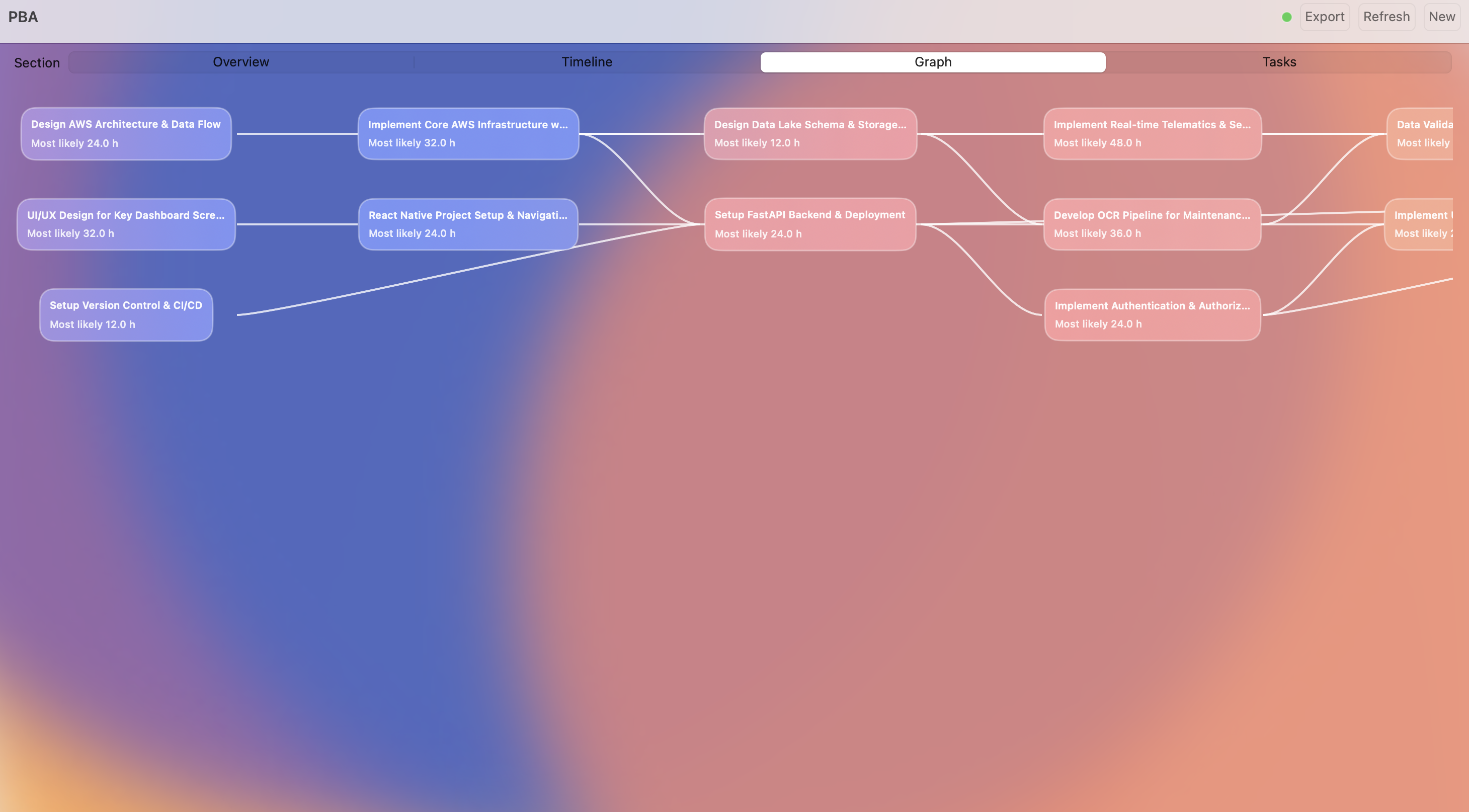
Directed Acyclic Graph for Task execution
-
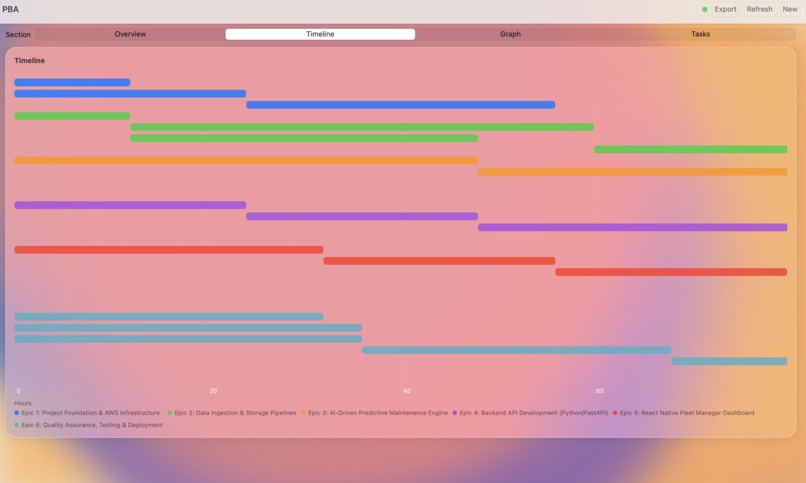
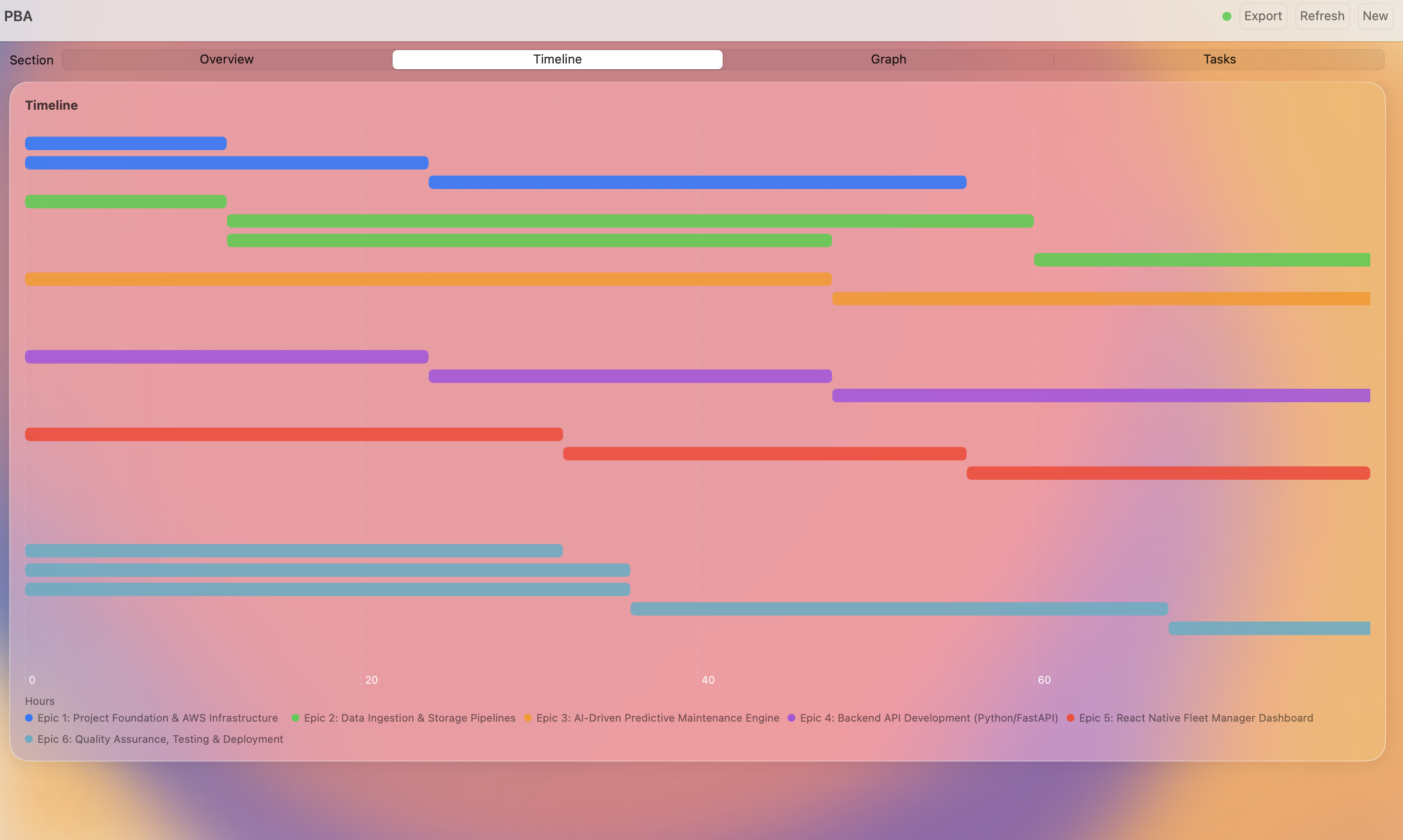
Blueprint based task Gantt Chart
-
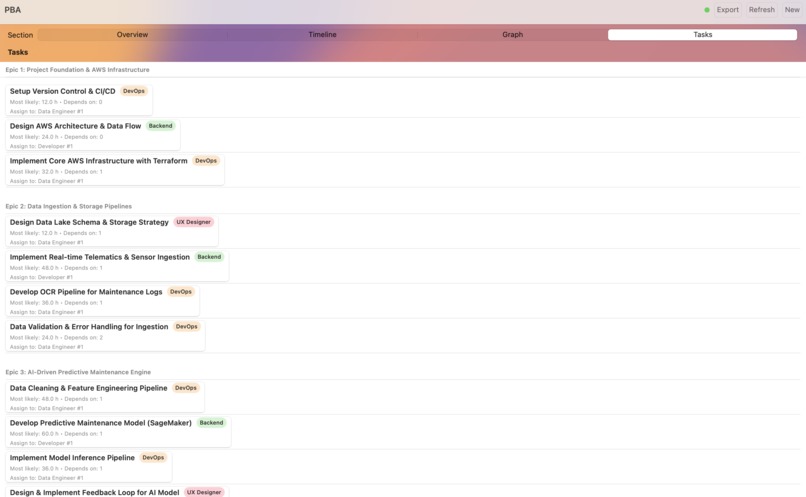
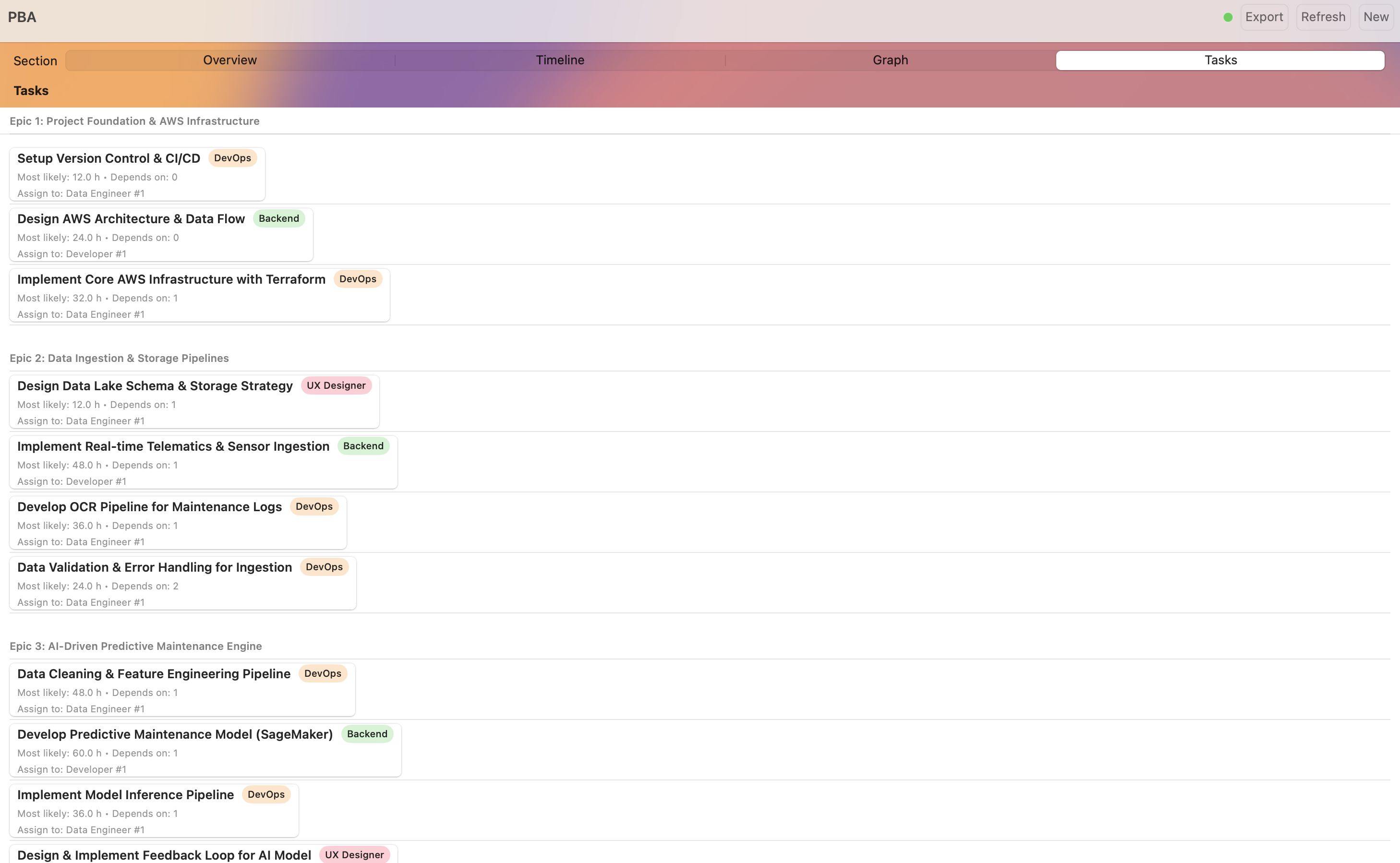
Tasks Assignment

Inspiration
Software delivery is currently plagued by "gut-feeling" estimations that lead to 70% of project delays. We noticed that most teams rely on manual spreadsheets that fail to account for technical debt, team velocity, or complex stack integrations. We built Beeprint to replace this guesswork with a rigorous, predictive engine that treats project requirements as digital DNA.
What it does
Beeprint is a mission control system for project scoping. It starts with an Intelligent Intake where an AI agent interviews the user to clarify scope. It then generates a full Task Directed Acyclic Graph (DAG) with automated role allocation. The core engine runs 1,000 Monte Carlo simulations using Beta-PERT distributions to provide P50 and P90 confidence intervals. Users can utilize a "What-If" simulator to see how shifting team seniority or tech stacks impacts the critical path in real time.
How we built it
We developed a native macOS application using SwiftUI for a high-performance, reactive user interface featuring liquid glass components. The backend is powered by FastAPI, which handles the statistical simulation logic and persistence via SQLite. We integrated the Google Gemini API to handle the heavy lifting of turning ambiguous human ideas into structured, machine-readable JSON. Our estimation logic uses a deterministic engine that scales critical path hours against team seniority and stack complexity multipliers.
Challenges we ran into
Bridging the gap between unstructured AI responses and structured engineering data was our biggest hurdle. We had to enforce strict Pydantic schema validation to ensure the AI-generated task graphs never broke the simulation engine. On the frontend, optimizing the Monte Carlo loops to run instantly as the user moves "What-If" sliders required careful state management and performance tuning to avoid UI freezes. We also navigated complex macOS networking sandboxing to ensure secure communication between our SwiftUI view and the FastAPI local server.
Accomplishments that we're proud of
We successfully hit almost every core and bonus requirement of the challenge. We are particularly proud of our Risk Profiler, which calculates technical debt and bottleneck depth to produce "Red Zone" alerts. Seeing the system autonomously decompose a vague idea into a professional work breakdown with dependencies and role assignments feels like magic. We also achieved a seamless, real-time update loop where manual task edits immediately trigger a re-simulation of the entire project health.
What we learned
We learned that the most effective way to use LLMs in engineering is not for guessing numbers, but for extracting structure. By using Gemini to build the backbone and a statistical engine to handle the math, we created a system that is both creative and mathematically sound. We also gained deep experience in building 'Monorepo' architectures that bridge Python-based data science with native Apple ecosystem development.
What's next for Beeprint
The final frontier is Historical Calibration. We plan to allow teams to upload CSV data from past projects so the engine can learn their specific velocity and Bayesian-tune future estimates. We also want to expand our Smart Allocation to support more granular roles like Security Engineers and Site Reliability Engineers, making Beeprint the gold standard for autonomous project planning.


Log in or sign up for Devpost to join the conversation.