-
-

Semantic graph of research papers. Orange circles are current gaps in research: our target.
-
Side by side: Selected void on the left, Cross-pollination on the right
-

beehyv
-
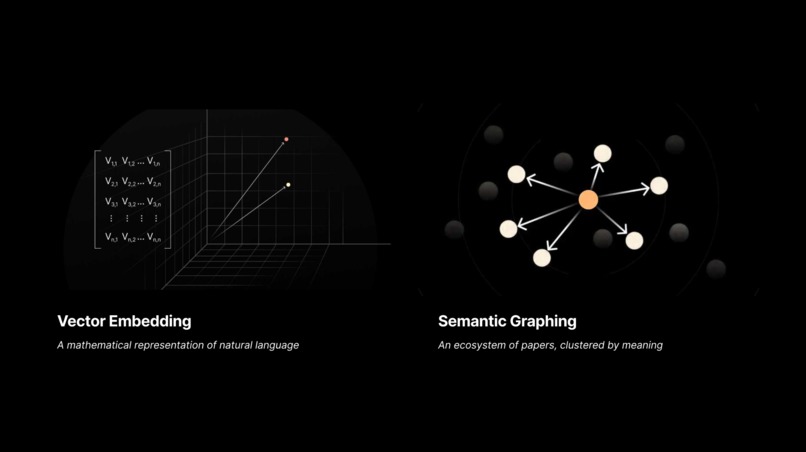
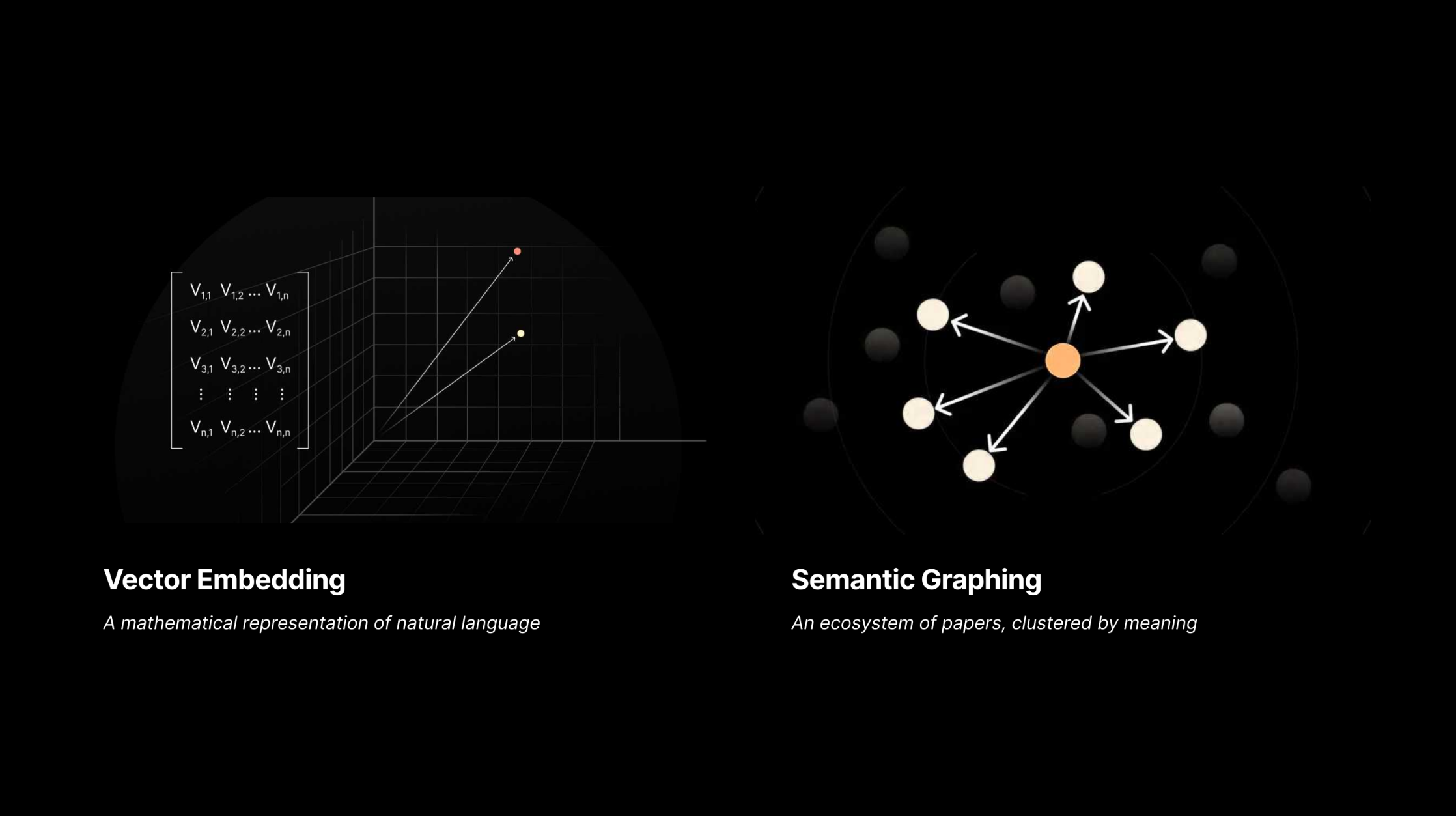
Vector embedding + Semantic Graphing: The Basics
-

Super-simplified architecture
-
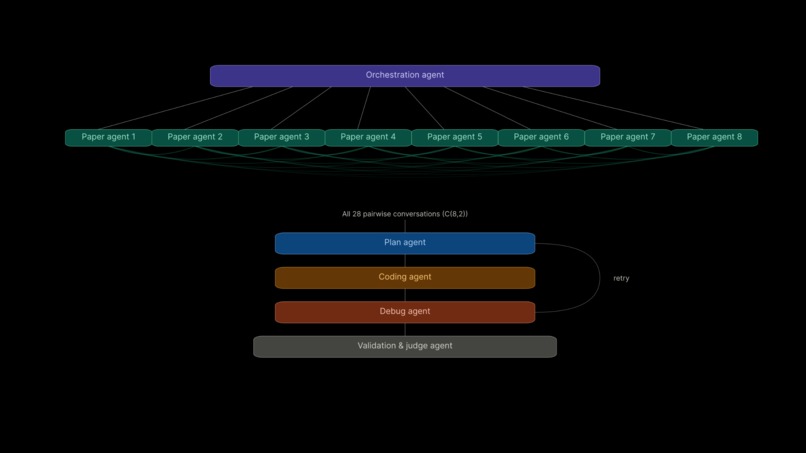
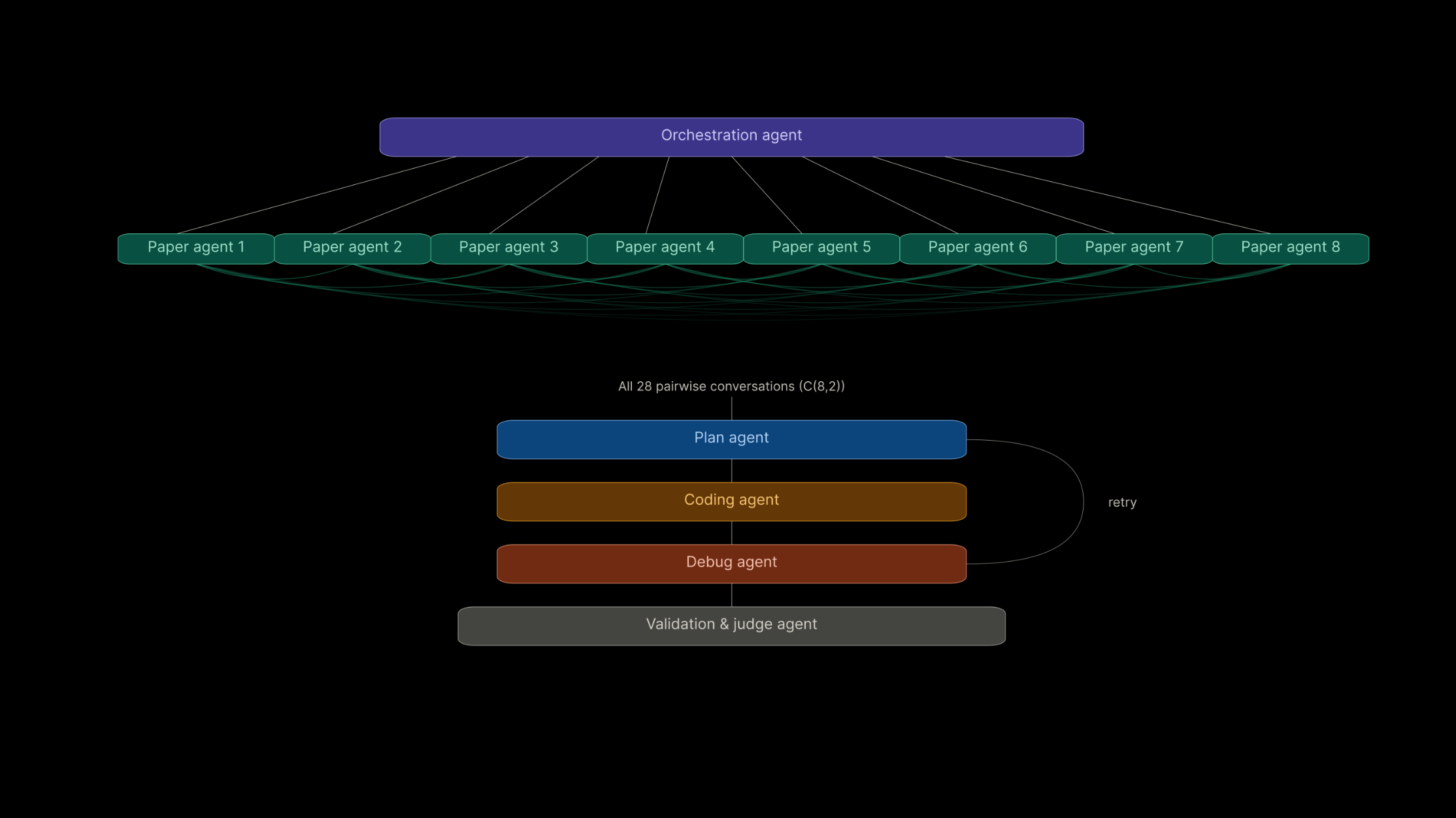
Cross-Pollination Architecture
-




Inspiration
Hallucinations, AI jargon, non-replicable codebases: the current artificial intelligence research landscape is a rapidly expanding field with superficiality seeping into every corner of its domain. As model research steers more accessible, both the direction and execution of AI research need to be carefully vetted and tested to ensure misinformation does not become widespread in higher academia.
In this light, a few questions arose: is it possible to automate the peer-review process of traditional research with LLM orchestration, how preventable are hallucinations in this context, and how far could we really break the boundaries of sustainable, verifiable academia today?
What it does
Full version: https://docs.google.com/document/d/1TvfBW-2dD5CeIcvyE9a_shxq8ZP6b6_vjYrXE6rB5t0
TL;DR:
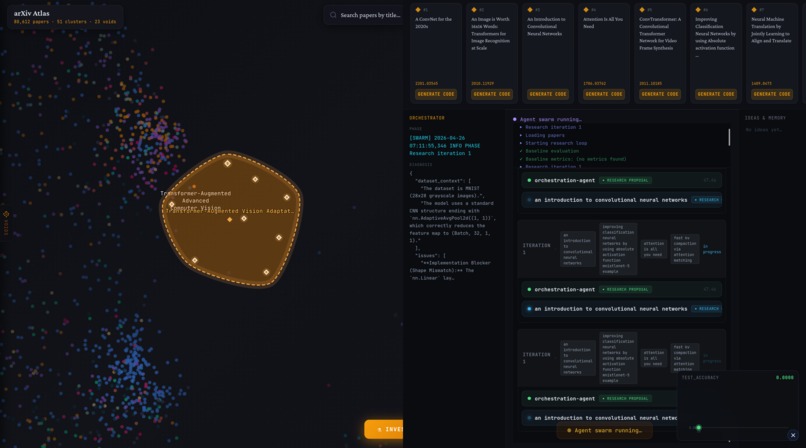
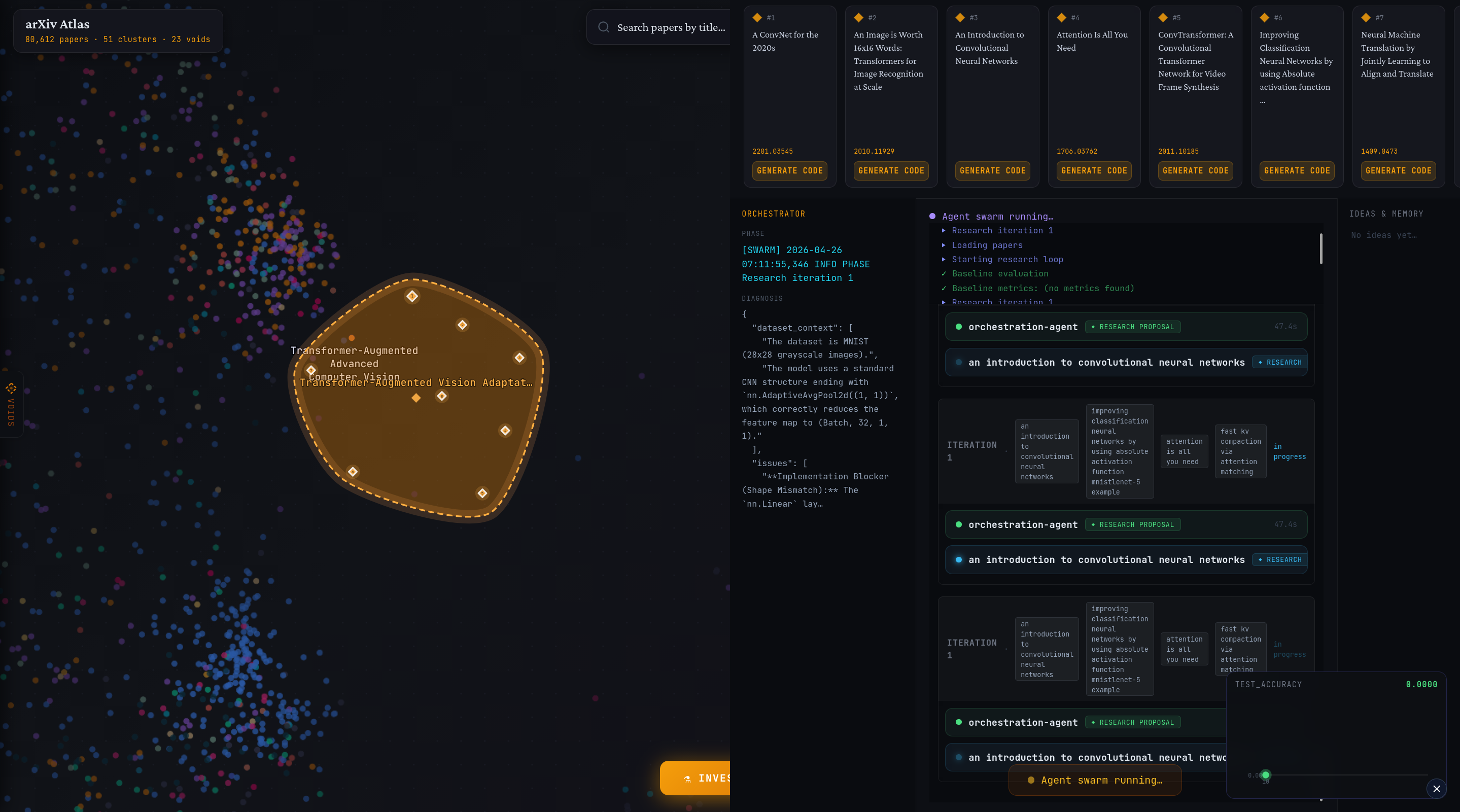
Semantic Graph Generation: Builds a focused sample of ~100k arXiv papers (research paper repository). It uses MiniBatchKMeans (clustering algorithm) on precomputed vector embeddings (numerical text representations) to generate paper clusters, an LLM (AI text model) to create cluster titles, and UMAP (dimensionality reduction) to flatten the embeddings to a 2D visualization space, where the coordinates of any given paper represent its natural-language meaning.
Void Discovery: Identifies research gaps by computing a Voronoi diagram (space partitioning) and an alpha shape (boundary detection) to find maximal empty circles (voids): regions in the scatterplot with low research density. Candidates are filtered by angular coverage (ensuring interior placement) to keep only true voids. The top voids are selected, and an LLM is used to name the missing region.
Paper Selection: Border papers surrounding each void are enriched with credibility-based metadata (mainly from OpenAlex) and scored using citation + recency. Eight diverse papers per void are selected using angular bucketing (diversity) and score-based filling (quality), with the top 8 moving to the next stage.
Cross Pollination Model Synthesis: This is an iterative cycle where a research problem is given to an orchestration agent (central controller): the Queen Bee. Individual paper agents (Worker Bees) provide proposals (idea, rationale, predicted effect, code changes). Worker Bees are paired to generate hybrid ideas. A planning agent creates a code plan, a coding agent implements it, and a judge agent tests results, feeding them back to the orchestration agent until target accuracy is reached, producing our new model, our larvae!
For a much more in-depth description of what went on behind this project, please see the link above.
How we built it
For our agent research swarm, we used Python with Pytorch for local model development. For LLM inference, we used OpenRouter’s Nemotron 3 Super and our ASUS GX10 AI Supercomputer with Gemma4:Latest. We used SQL and FastMCP to create MCP for our research agents.
For our website and frontend, we used Typescript with React and WebGL.
Challenges we ran into
Our largest challenge was LLM inference speed. Because we had to make the service responsive and interactive for users, we could not run very large LLMs with high reasoning levels. We started off using Nemotron 3 Super because it was cloud hosted by OpenRouter and a very powerful coding model. We also tried inclusionAI’s Ling-2.6-1T before obtaining an ASUS GX10 where we could comfortably run Gemma4:Latest with just a few seconds of delay.
Accomplishments that we're proud of
We are proud of assembling such a complex and well-organized agentic AI workflow for research. We had to manage the communication, memory, and context between over 6 agents across the entire research iteration process. This meant building a robust MCP for our agents to categorize and store information in. We also had several levels of agentic management using orchestration and feedback agents that would organize and direct the research of the sub-agents.
What we learned
We learned about the entire LLM agent orchestration process. Reliable research and development with AI agents is not as simple as just typing a prompt into one agent! To fully utilize the power of agentic development, we learned to manage and oversee agents as a large research team, with each agent being assigned a specialization and focus. This was our first time working with MCP at this scale and also doing inference at this scale and speed.
What's next for beehyv
Using more compute, we hope to increase the quantity of research output. We will be able to run larger state-of-the-art models that can produce more modern and accurate code.


Log in or sign up for Devpost to join the conversation.