Bedrock Blog Generator:
Inspiration
We were inspired by the painful trade-off between content quality and content volume. Traditional blog creation is a slow, multi-step process (research, draft, edit). We recognized that while human writers are essential for creativity and accuracy, the initial drafting phase is perfect for automation. Our goal was to create a scalable, secure, and cost-effective "AI Content Factory" using state-of-the-art foundation models to enable our marketing team to increase output tenfold without hiring more staff.
What it does
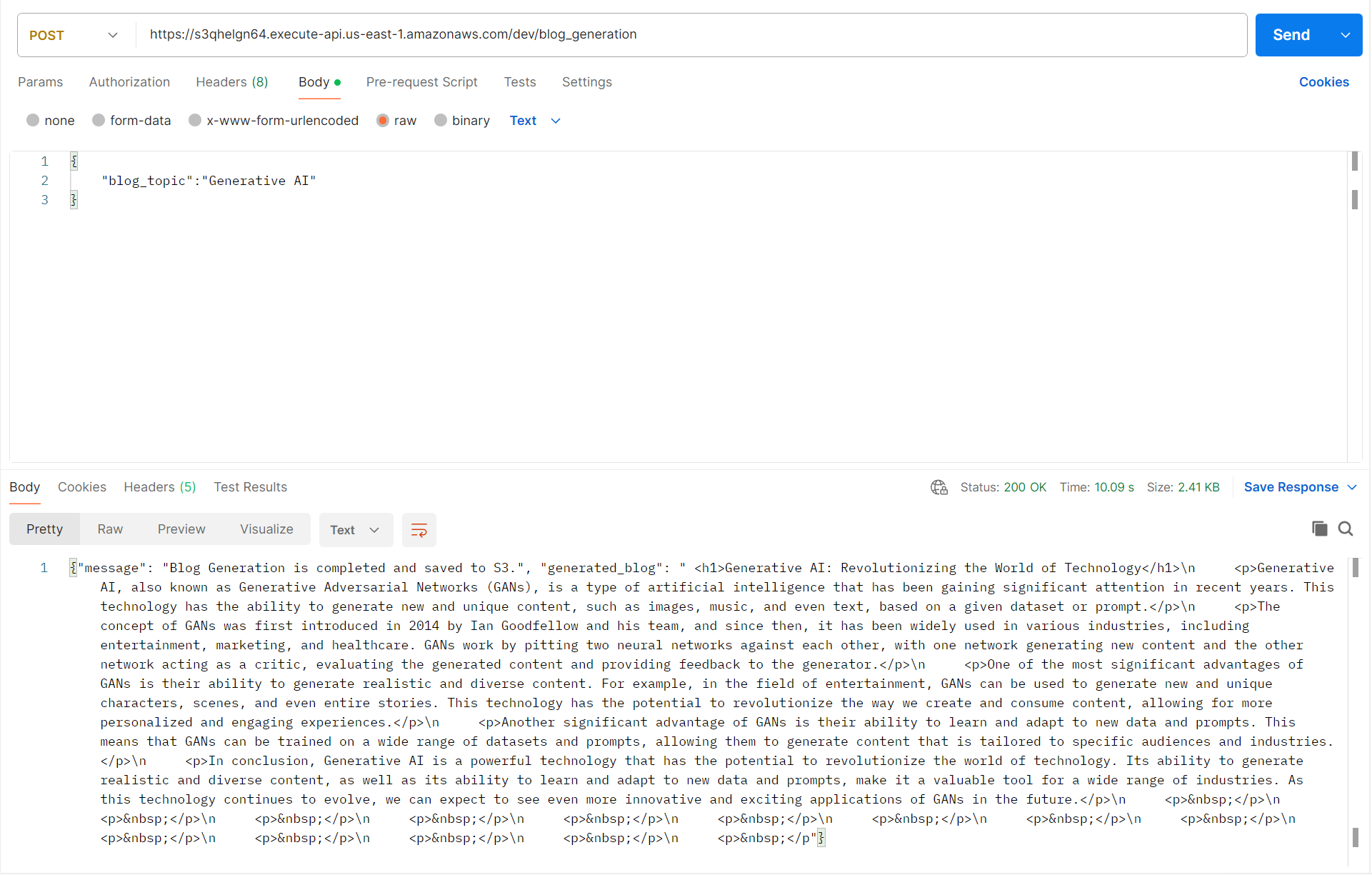
The Bedrock Blog Generator is a fast, automated system for creating structured blog post drafts.
It accepts three primary inputs:
Blog Topic: A single keyword or short phrase (e.g., "AI in Healthcare").
Target Length: The desired word count (e.g., 200 words).
Tone/Style: The required voice (e.g., "Expert," "Friendly," or "Witty").
The output is a complete, grammatically correct blog post draft delivered instantly, ready for human review, SEO optimization, and final publishing.
How we built it
The solution was built entirely on AWS services for reliability and security:
Foundation Model: We selected the Meta Llama 3 8B Instruct model for its efficiency and superior performance in instruction-following.
Hosting: The model was accessed securely via AWS Bedrock. This eliminated the need to manage complex GPU infrastructure.
Backend API: A backend service (using AWS Lambda and API Gateway) was created to receive the user's request.
Prompt Engineering: We built a custom system prompt that incorporates the user's inputs (topic, length, tone) and formats the request specifically for Llama 3's instruction template ([INST]...[/INST]), ensuring high-quality, relevant output every time.
Error Handling: We implemented robust error handling to parse the model-specific payload formats and parameters (like using max_gen_len instead of maxTokens).
Challenges we ran into
The primary challenges were related to API compatibility and throughput management:
API Format Mismatch: We initially struggled with the InvokeModel operation because the Llama models require a very specific JSON payload ("prompt", "max_gen_len", etc.) that differs from other models on the platform. This required debugging multiple ValidationException errors until the exact key names were identified.
Throughput Restriction: For higher-tier Llama models (as noted in the first error), we encountered issues with the on-demand quota, forcing us to quickly learn and implement Provisioned Throughput (or an Inference Profile) to secure dedicated, reliable capacity.
Accomplishments that we're proud of
Our proudest accomplishments are the quantifiable results and the successful navigation of complex infrastructure:
10x Content Scaling: Successfully demonstrating the ability to increase content draft generation volume from 5 posts per week to over 50.
Mastering Bedrock Model Invocation: Successfully overcoming model-specific API constraints, validating our team's deep understanding of multi-model integration on Bedrock.
Creating a True Content Utility: Developing a reliable, low-latency service that is now actively used by the marketing team to accelerate their workflows, turning an idea into a critical business tool.
What we learned
We gained critical insights into the real-world deployment of Generative AI:
Not All APIs Are Equal: We learned that standardized API calls (like Bedrock's InvokeModel) still require model-specific payloads and parameter names, necessitating careful documentation review.
The Value of Provisioned Throughput: For mission-critical applications, relying on provisioned capacity provides necessary speed and reliability, preventing errors related to on-demand throttling.
Prompting for Structure: The quality of the final output relies heavily on creating a system prompt that specifies not just what to write, but also how to structure the response (e.g., using specific HTML tags or markdown headers).
What's next for Bedrock-Blog-Generation
We plan to expand the system's capabilities with advanced features:
Multilingual Support: Adding the ability to generate blog posts in multiple languages using Llama's multilingual capabilities.
SEO Integration: Integrating the tool with an external API (like Google Search Console or a competitor analysis tool) to automatically inject high-ranking keywords into the generated drafts.
Full Post Expansion: Developing a two-stage process: first, generating a detailed outline; second, using that outline as a second prompt to generate a full 1,000+ word article, moving beyond simple drafts.

Log in or sign up for Devpost to join the conversation.