-
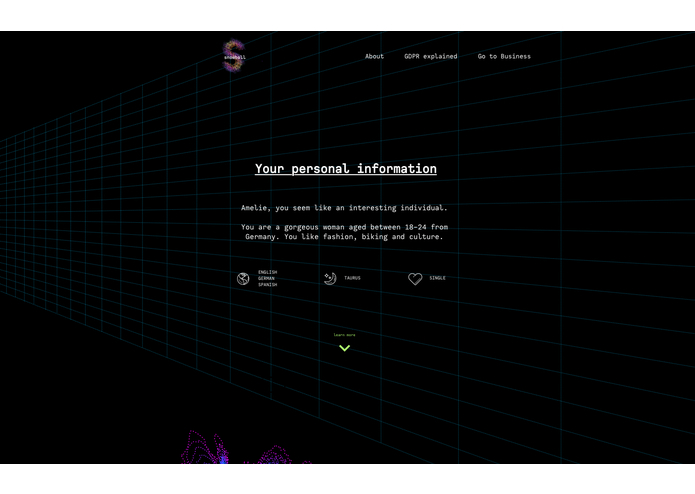
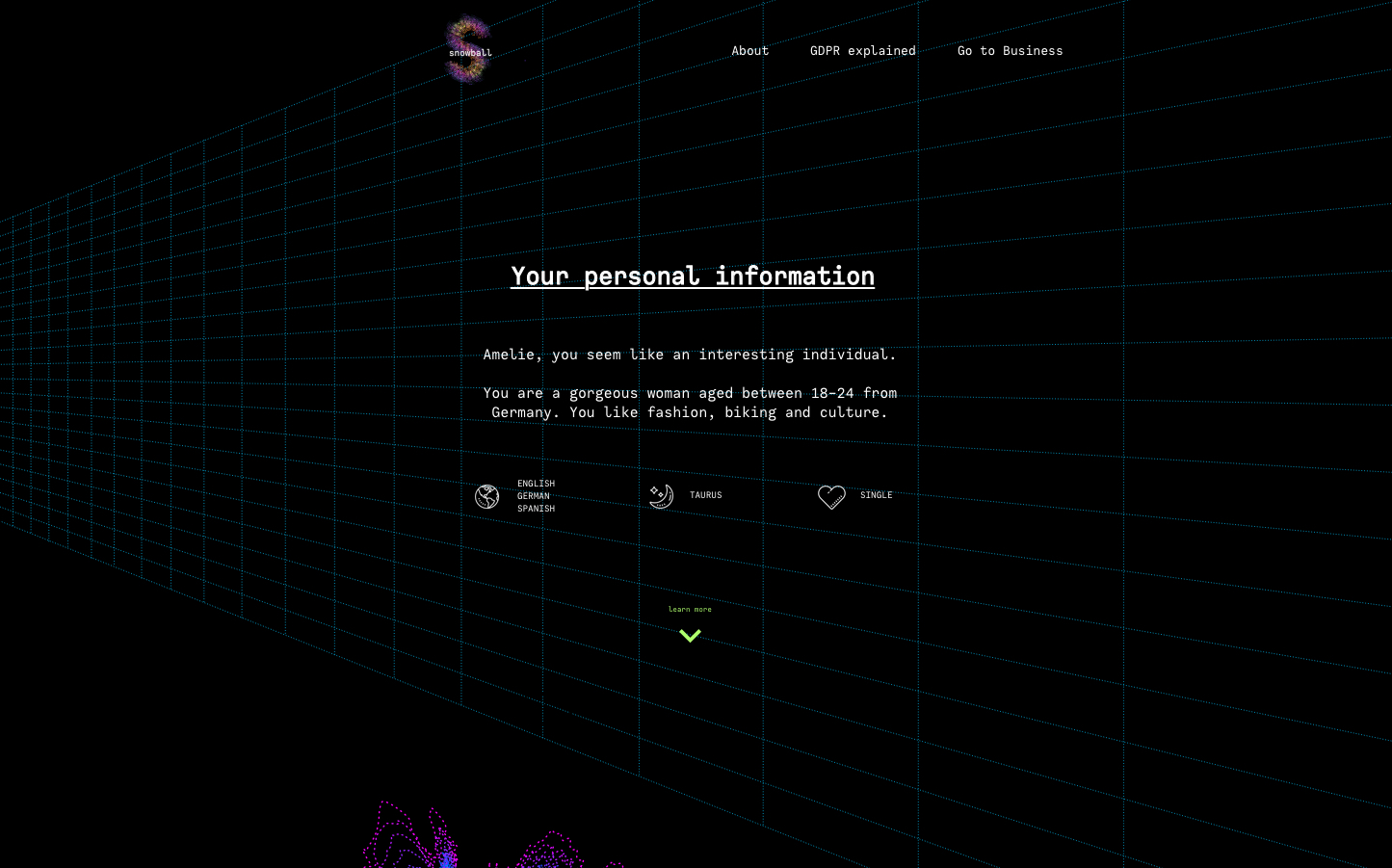
landing page
-
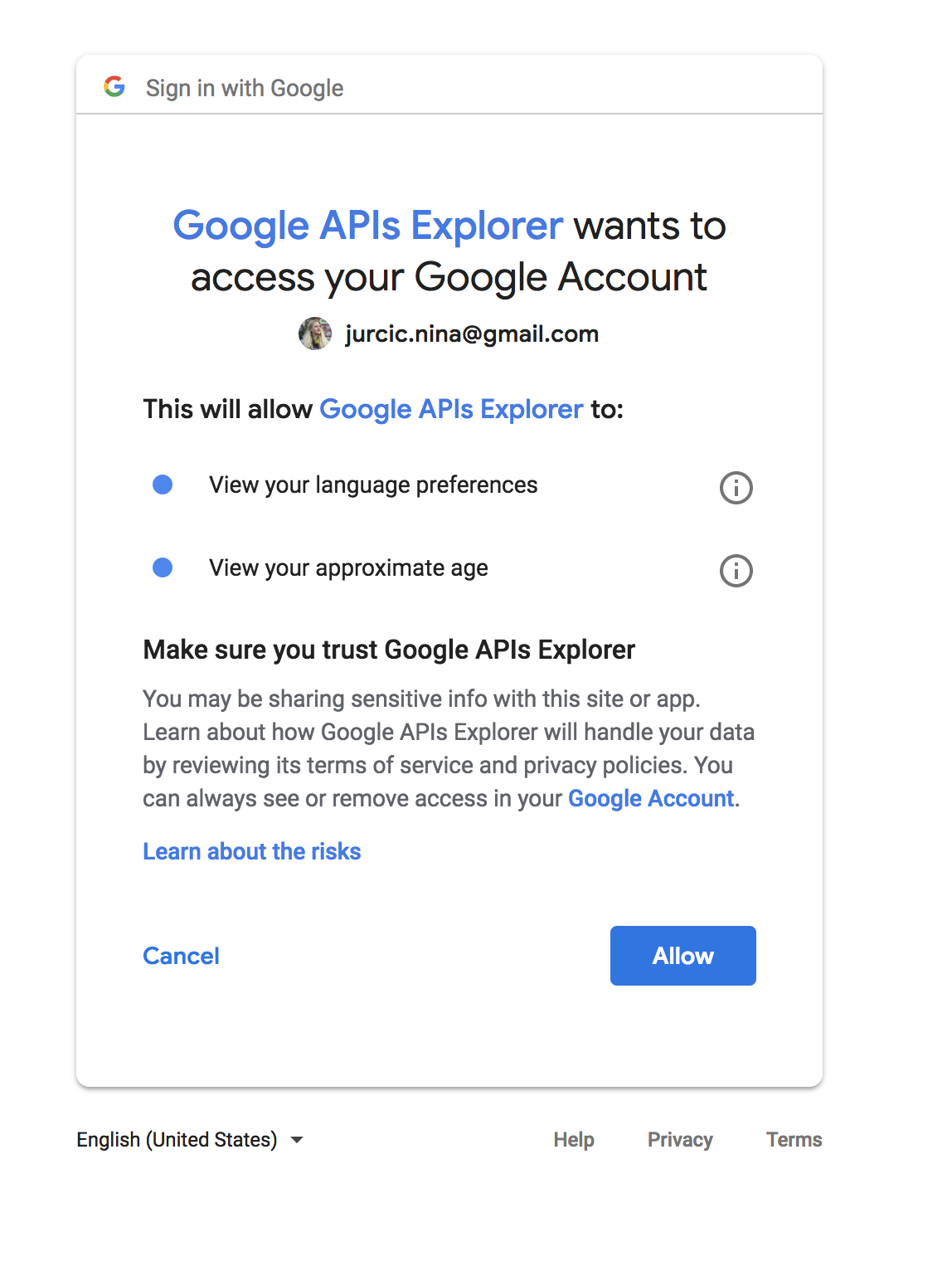
google API - select an email account
-
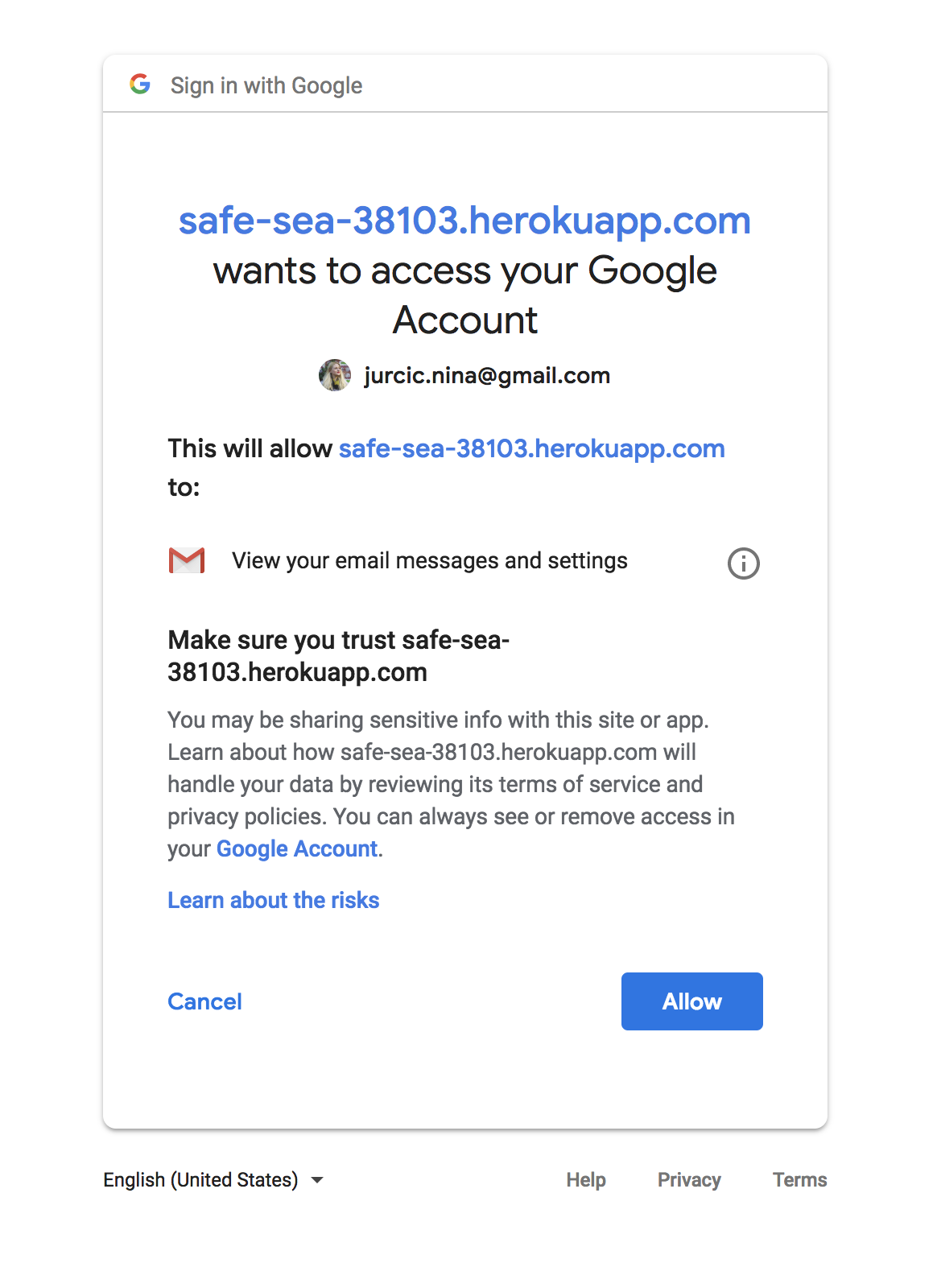
google API - access request to view data
-
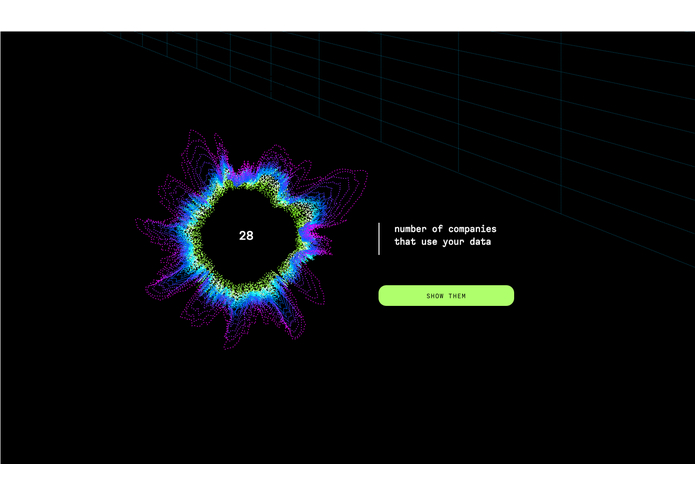
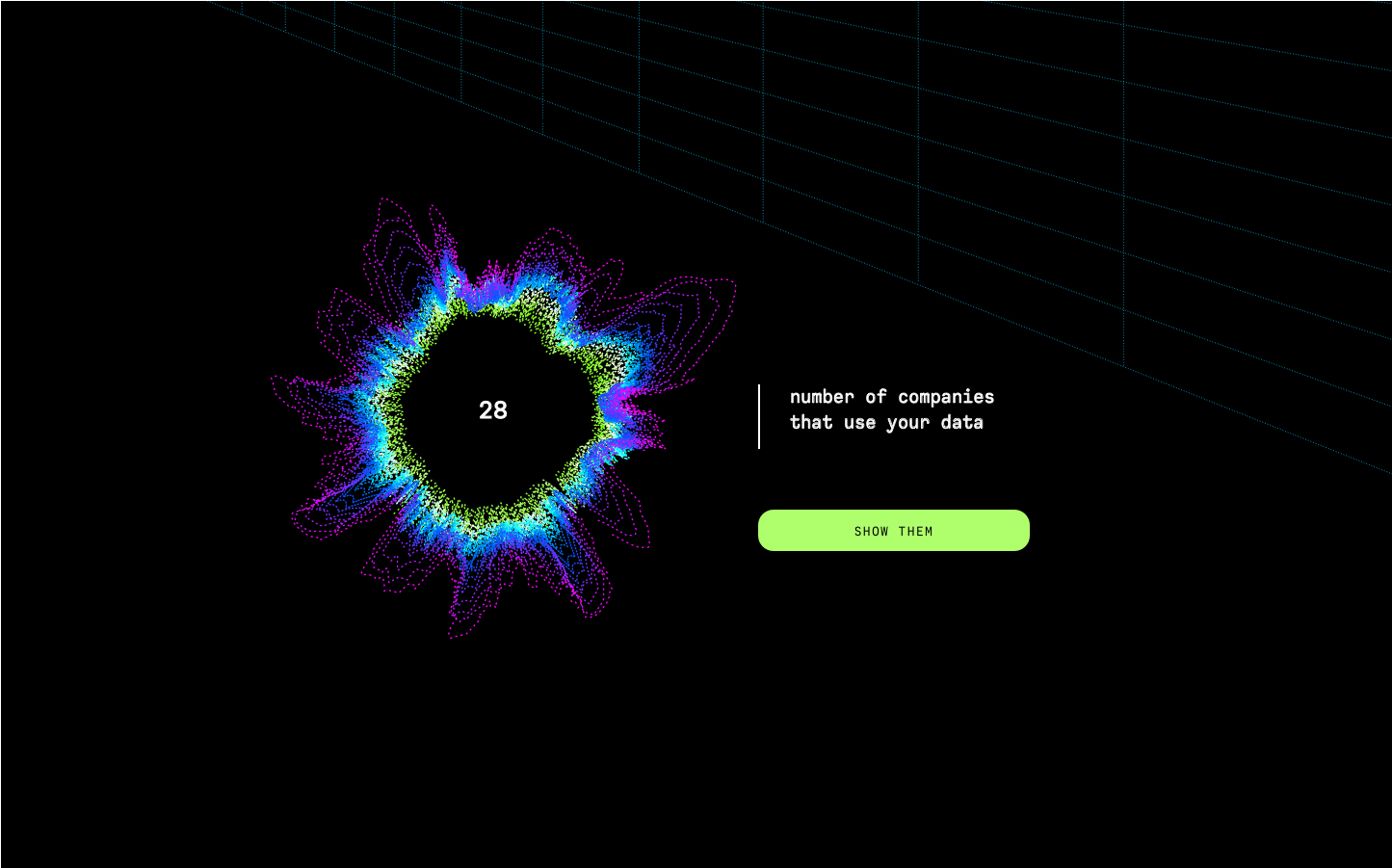
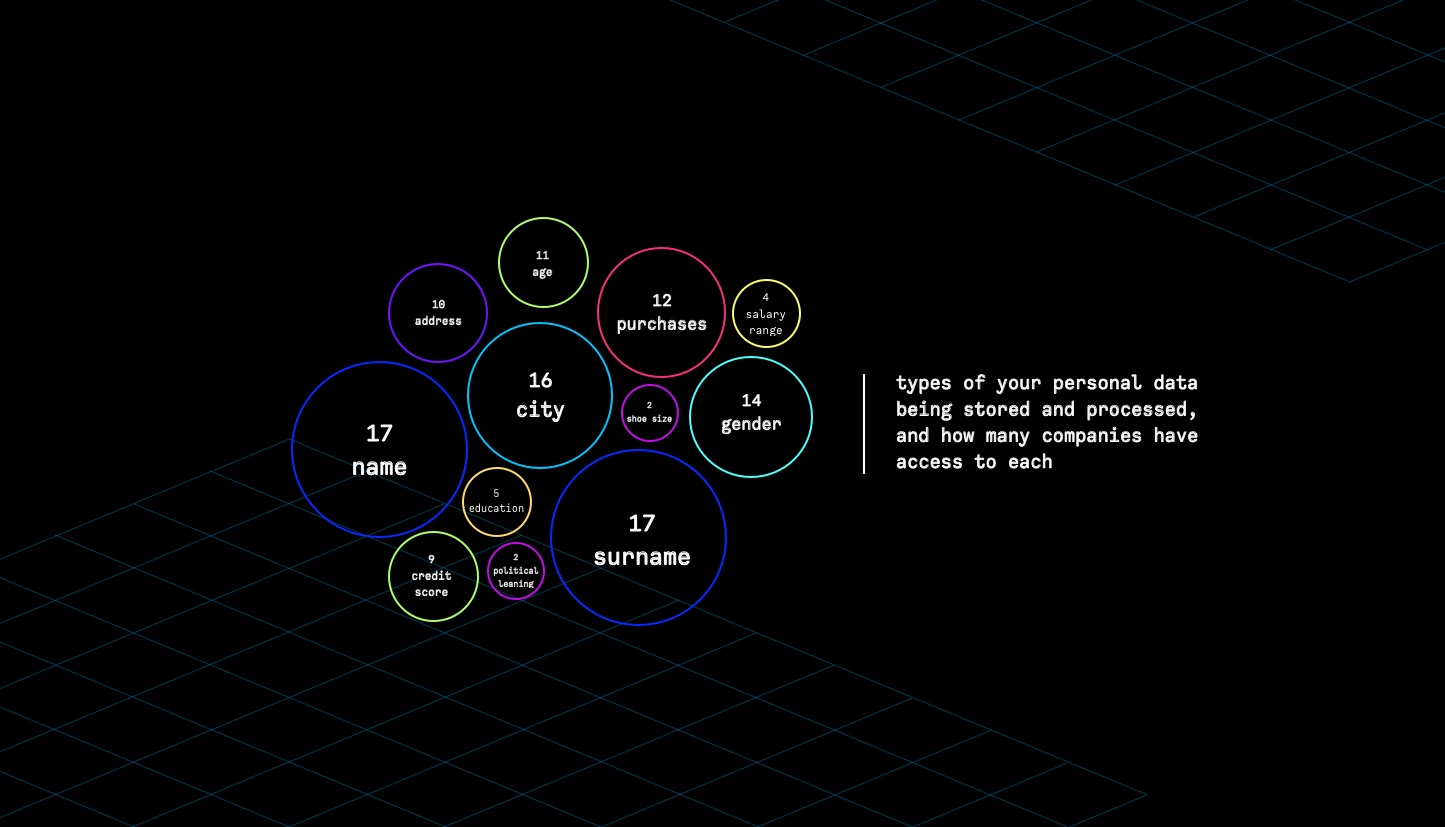
no. of companies that can access your data
-

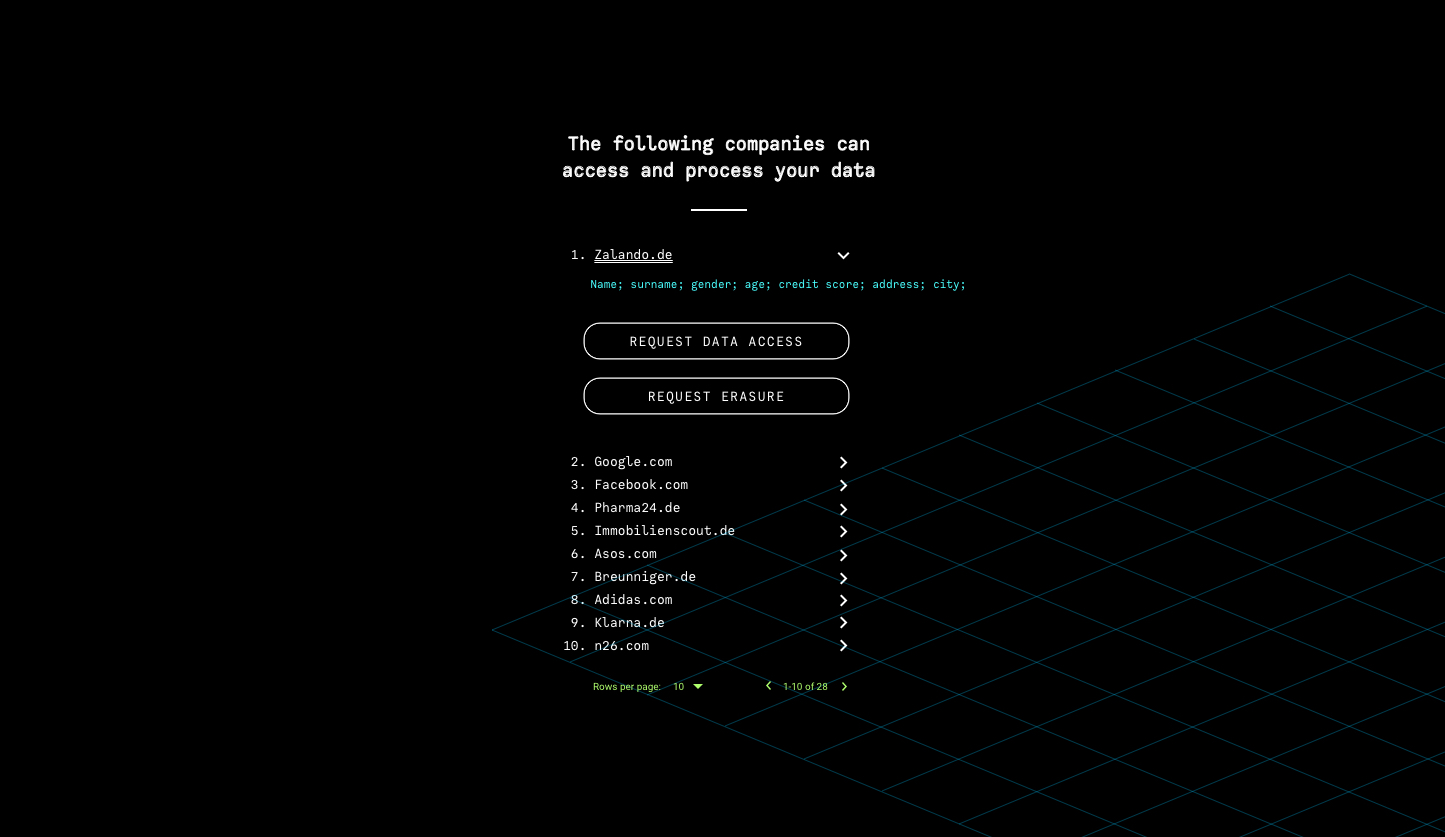
list of companies that can access your data
-
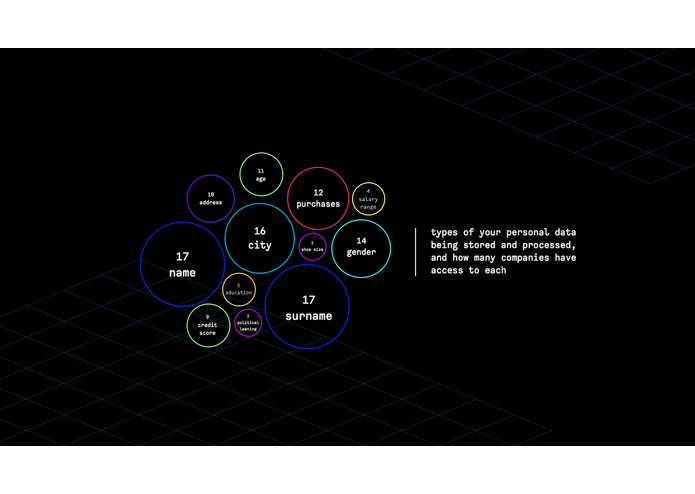
data cloud
-
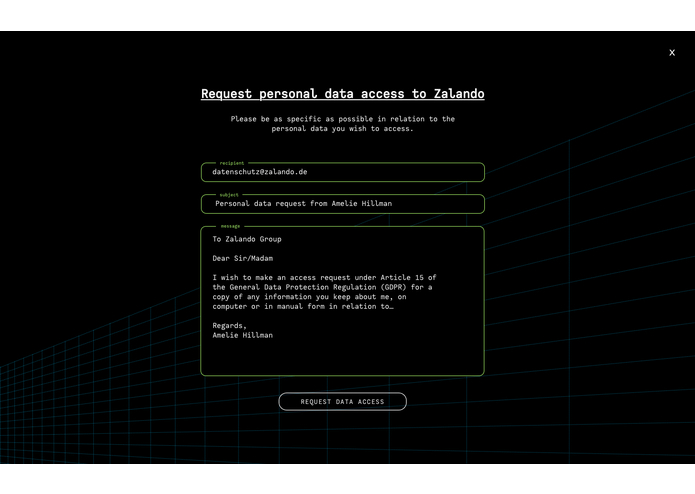
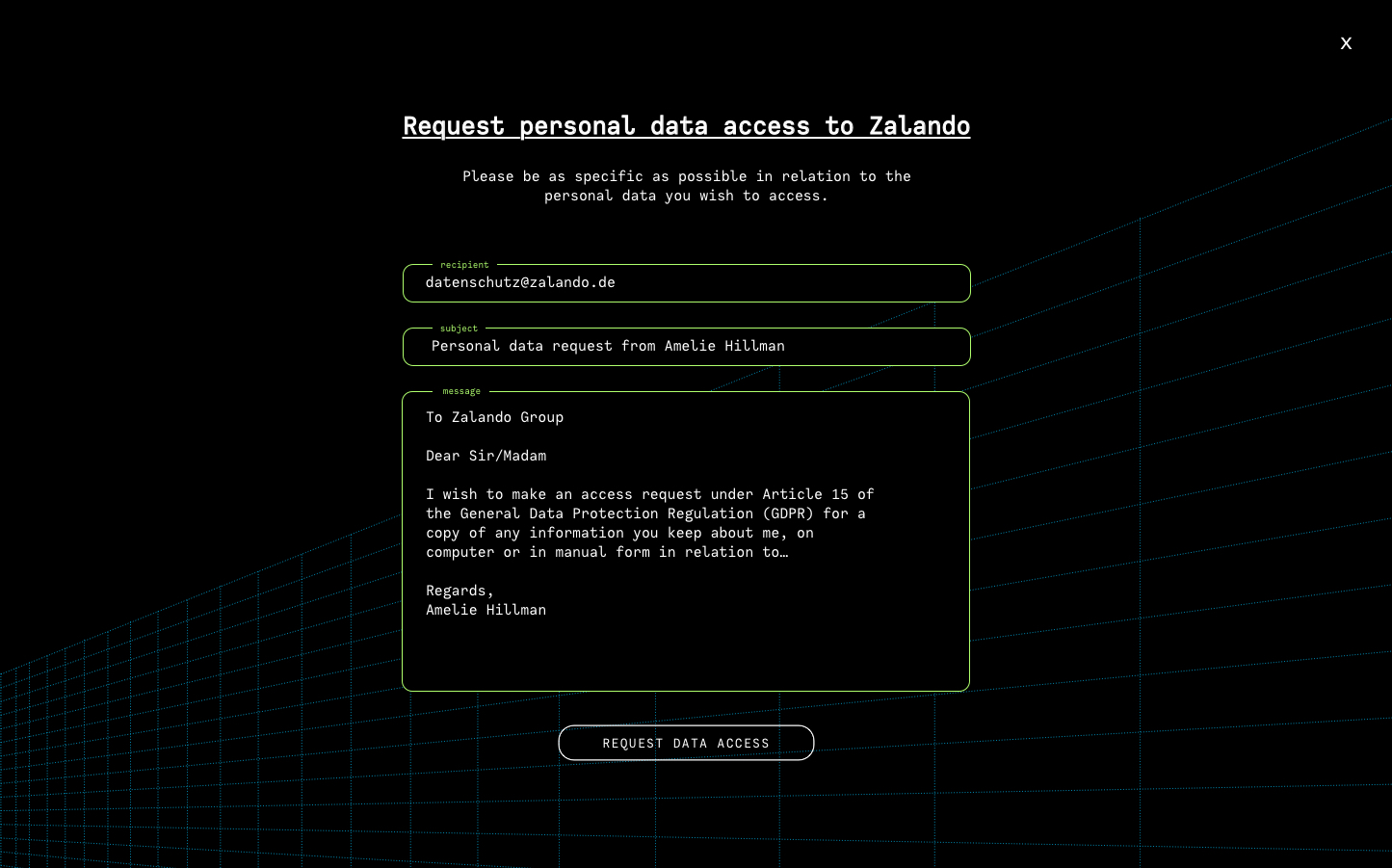
Request to access the information
-
What's next
Inspiration
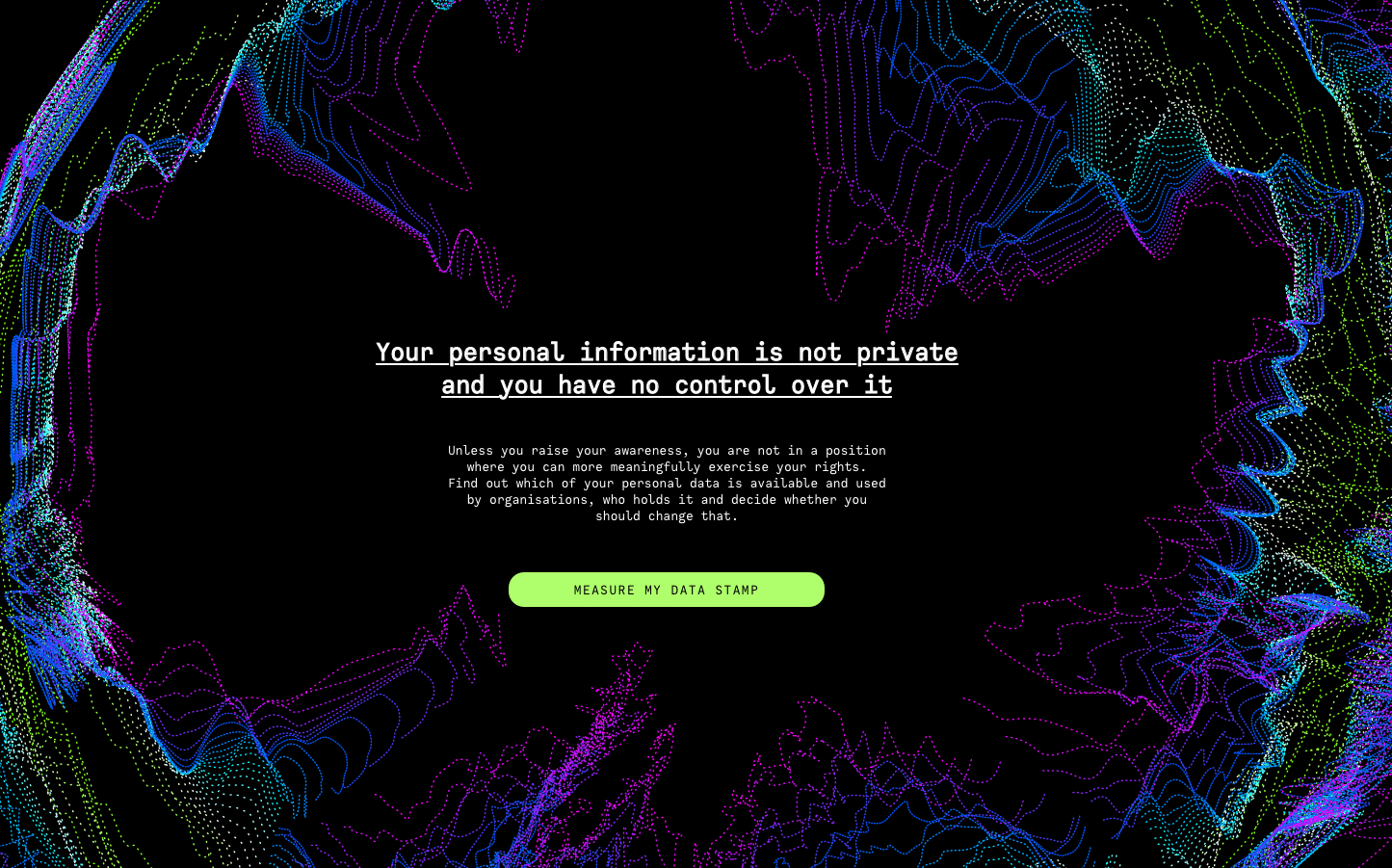
Data is the currency of future, yet not everyone has equal part in that exchange. By using different online services we oversee how much of our personal information is being stored, processed, redistributed and sold.
We believe everyone should be in control over their personal information instead of being ignorant and indifferent. We believe some things should not be compromised. We don't give our address and salary range to a stranger on the street. Why would we give it to other strangers hiding behind the large brands so they can use it for their profit?
By making internet consumers more aware, we can empower them and encourage change. We aim to create a snowball effect, to make sure large companies who mostly profit from user data, take GDPR very seriously and strictly comply to it.
We can do so only if we stop taking our personal information for granted and become aware of how crucial it is to have control over our personal digital assets.
While our data could be stripped down to numbers and statistics, we should not. We are individuals, not numbers.
What it does
A website that helps individuals to raise awareness and gain control over usage of their personal information by fetching and visualising who can access and process their data, what kind of their personal data of per company (entity) is being used, how many companies hold each piece of information and what to do about it. User can to request data access or eradication from any company on the list retrieved. We are also encouraging them to make themself familiar with GDPR.
How we built it
We used Google person APIs and fetched data by reading contents of gmail (user granted permission). We were looking into emails that contain information related to creating an account at various service providers, what kind of transactions occurred (e.g. online purchase, newsletter subscription, signing the online petition etc). That data gave us an insight on which companies have access to specific parts of our data, and by knowing what kind of data they collect we can show such results to the user and make him more aware of e.g. how many companies have information about his eye colour, location history etc.
Demo website was built with angular.js and HTML and data collected and analysed with Python.
Challenges we ran into
- Accessing information of what exact data values companies have stored per user
- crawling / automatically fetching what exact type of data each company is storing and using
- checking whether the company is GDPR compliant (matching data types that they store with contents of their respective privacy policy / terms & conditions could be partially done through NLP but there are far more aspects in regards it would be determined to which extent is the company GDPR compliant. it is also hard to determine universal range; for this compliance scoring system should be built
- reading in which levels companies are using the data or is it just being stored (should also include scraping / crawling)
Accomplishments that we are proud of
We tackled very important privacy questions and managed to fetch, analize and visualise the most common data taken for granted.
What we learned
We learned we should take our own data more seriously and that we have the power and tools not only to be in control, but to also raise awareness and spread the word.
What's next for GDPR snowball
We are keen on taking this concept further and build an actual website that can fetch way more information, present it nicely in form of dynamic / animated visualisations and see which new conclusions we can draw from the various type of information combined. We hope the snowball effect will manifest in form of thousands of email requests sent to companies, that will make them actually comply to the GDPR more strictly, resulting in less effort needed from the side of law companies specialised in data protection.
Built With
- angular.js
- google-people
- python



Log in or sign up for Devpost to join the conversation.