-
-
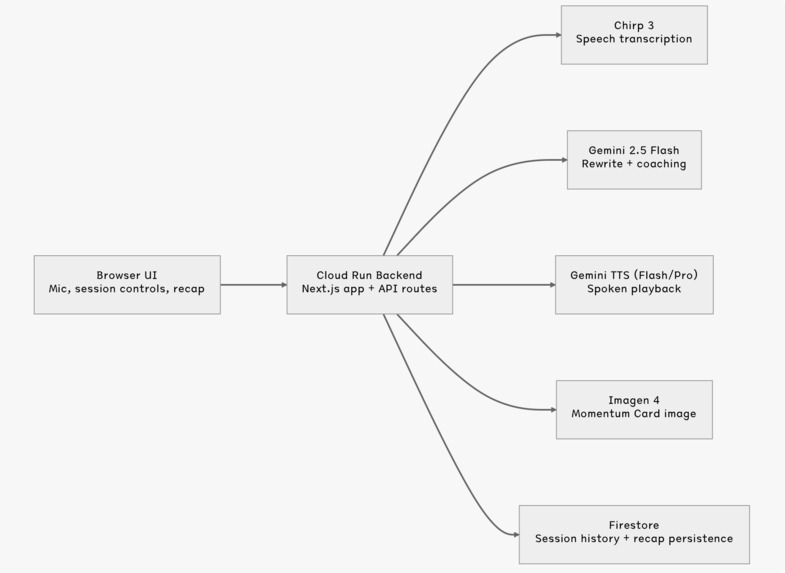
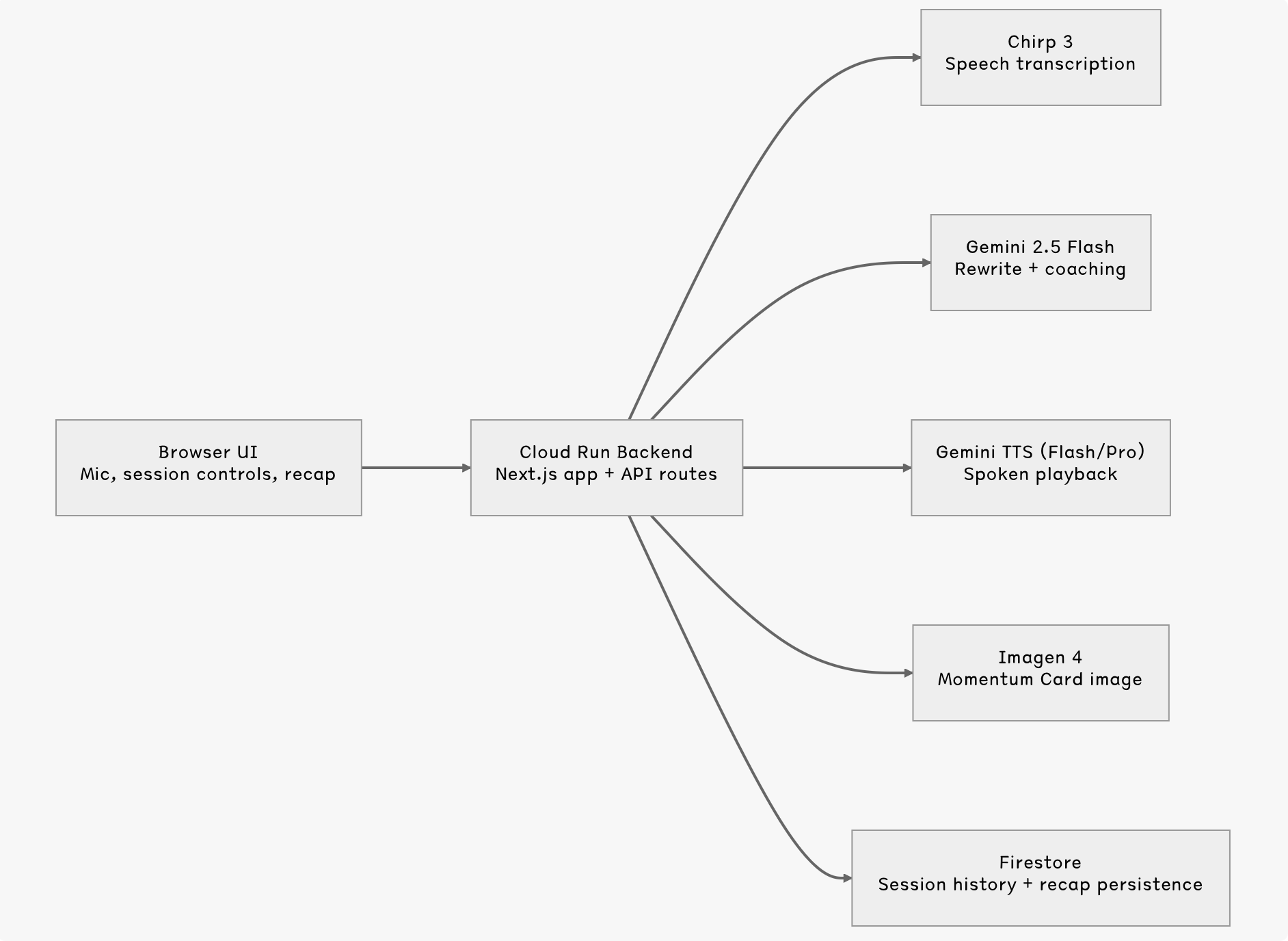
Architecture Diagram
Echo Coach
About the project
Interviews are hard not because people have nothing to say, but because pressure makes good ideas come out in a vague, repetitive, or less professional way. I built Echo Coach to help people practice spoken interview answers in a way that feels live, interactive, and encouraging.
Echo Coach is a live interview expression coach. It asks an interview question aloud, listens to the user’s spoken answer, rewrites that answer into a clearer and more professional version, reads the polished version back out loud, and generates a visual Momentum Card that gives the user something memorable to save from the session.
Instead of treating speaking practice like a text box, I wanted the experience to feel like a real coaching loop:
- hear a question,
- answer naturally,
- get a stronger version of what you meant,
- practice the improved version,
- leave with a recap artifact.
What it does
Echo Coach is focused on spoken expression coaching, not accent grading or speech therapy.
In the current MVP, the user:
- starts an interview practice session,
- hears a live spoken interviewer prompt,
- records an answer,
- clicks Coach this answer,
- receives a polished spoken answer plus improvement notes,
- optionally moves to the next question,
- ends the session and views a recap with a generated Momentum Card.
The app is intentionally designed around on-demand coaching. The user stays in control of when coaching happens, when recording starts, and when to move to the next question.
How I built it
Echo Coach is built with Next.js and deployed on Google Cloud Run.
I used the following Google models and services:
- Gemini Live for the live interviewer session boundary
- Speech-to-Text V2 with Chirp 3 for transcript capture
- Gemini 2.5 Flash for rewrite analysis and structured coaching output
- Gemini TTS for spoken playback of the polished answer
- Imagen 4 for the generated Momentum Card
- Firestore for recap and session persistence
- Cloud Run for hosting the application
The architecture is split into two layers:
1. Live session layer
This gives the app a real-time agent feel and satisfies the Live Agents requirement.
2. Post-turn coaching layer
After the user clicks Coach this answer, the backend:
- transcribes the answer,
- rewrites it into a stronger spoken version,
- extracts role/direction signals for the recap image,
- prewarms the Momentum Card generation in the background.
That means the recap image often starts generating before the user even ends the session.
Challenges I ran into
One of the biggest challenges was deciding what the product should actually optimize for.
I initially explored a pronunciation-first direction, but current models are much better suited to helping users improve clarity, grammar, tone, and professionalism than acting as a strict accent grader. Shifting the product toward interview expression coaching made the experience both more practical and more defensible.
Another challenge was latency. If every step waits for the previous one, the product feels slow. To improve the flow, I:
- preloaded the opening question audio,
- preloaded the polished answer audio,
- generated the Momentum Card in the background,
- and parallelized the rewrite and card-spec extraction work.
I also ran into quota and fallback issues with TTS. I handled that by adding a Gemini-to-Gemini fallback chain so the app can move from the primary TTS model to a second Gemini TTS model when quota is exhausted.
A final challenge was the image prompt design. I wanted the Momentum Card to feel encouraging and role-aware without becoming text-heavy or generating the wrong kind of imagery. I ended up using a two-stage approach:
- first extract role/direction and key strengths from the user’s original answer,
- then combine that structured output with fixed visual style constraints for image generation.
What I’m proud of
I’m most proud that Echo Coach feels like a real product instead of a disconnected AI demo.
It combines:
- spoken input,
- spoken output,
- structured text coaching,
- and generated visual recap output
into one continuous experience.
I’m also proud of the product framing. Echo Coach is not trying to “judge” how someone speaks. It helps people sound more like the version of themselves they want to present in an interview.
What I learned
This project taught me that building a good AI product is not just about calling a model. It is about:
- choosing the right problem,
- deciding what each model is actually good at,
- handling latency and quota realistically,
- and designing the user flow so the intelligence feels useful, not intrusive.
I also learned that multimodal products are strongest when each modality has a clear role:
- audio for interaction,
- text for precise feedback,
- image for emotional memory and recap.
What’s next
If I continue this project, I would focus on:
- stronger follow-up interview logic,
- better downloadable/shareable recap artifacts,
- more role-specific coaching,
- and a cleaner progress/history view across sessions.
My goal is for Echo Coach to become a tool that helps users walk into interviews feeling more clear, more prepared, and more confident.
Built With
- firestore
- gemini-2.5-flash
- gemini-live
- gemini-tts
- google-cloud-run
- google-gen-ai-sdk
- imagen-4
- next.js
- react
- speech-to-text-v2-(chirp-3)
- typescript


Log in or sign up for Devpost to join the conversation.