-
-

-
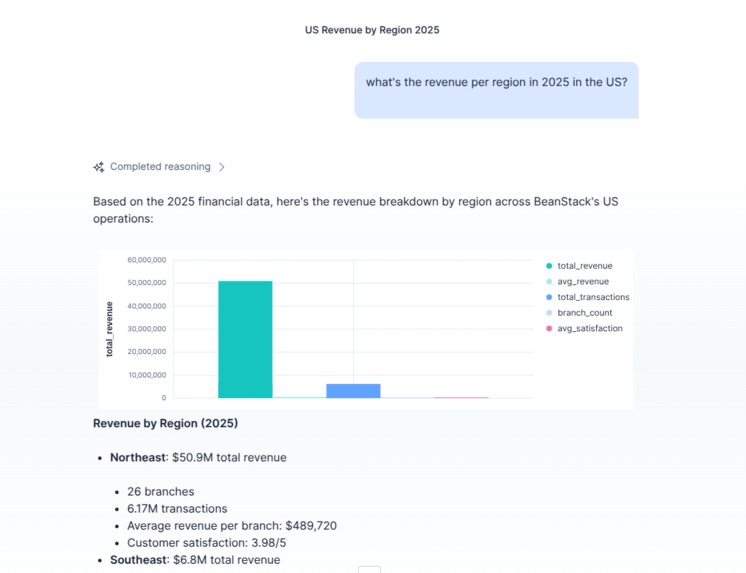
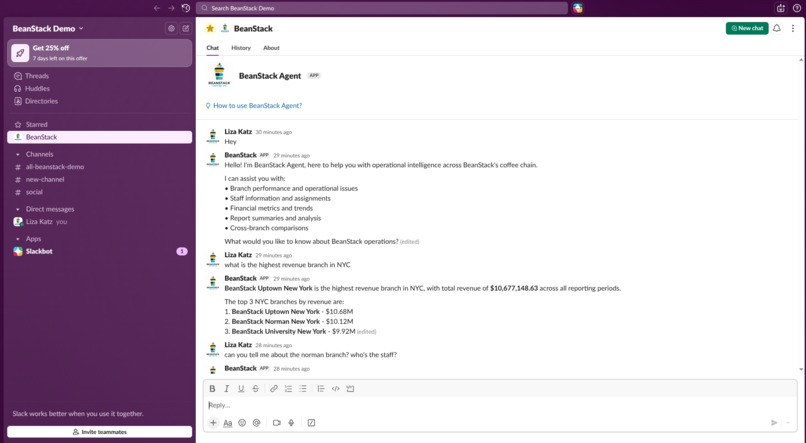
Location and time based inquireies
-
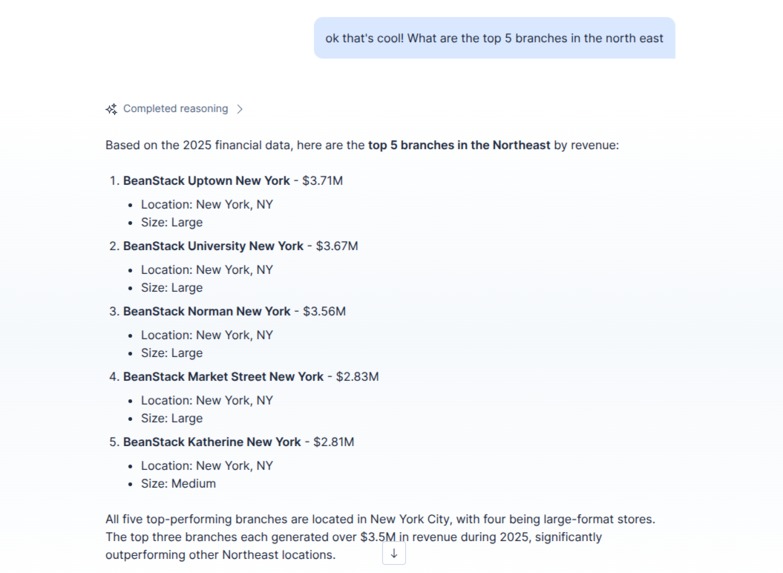
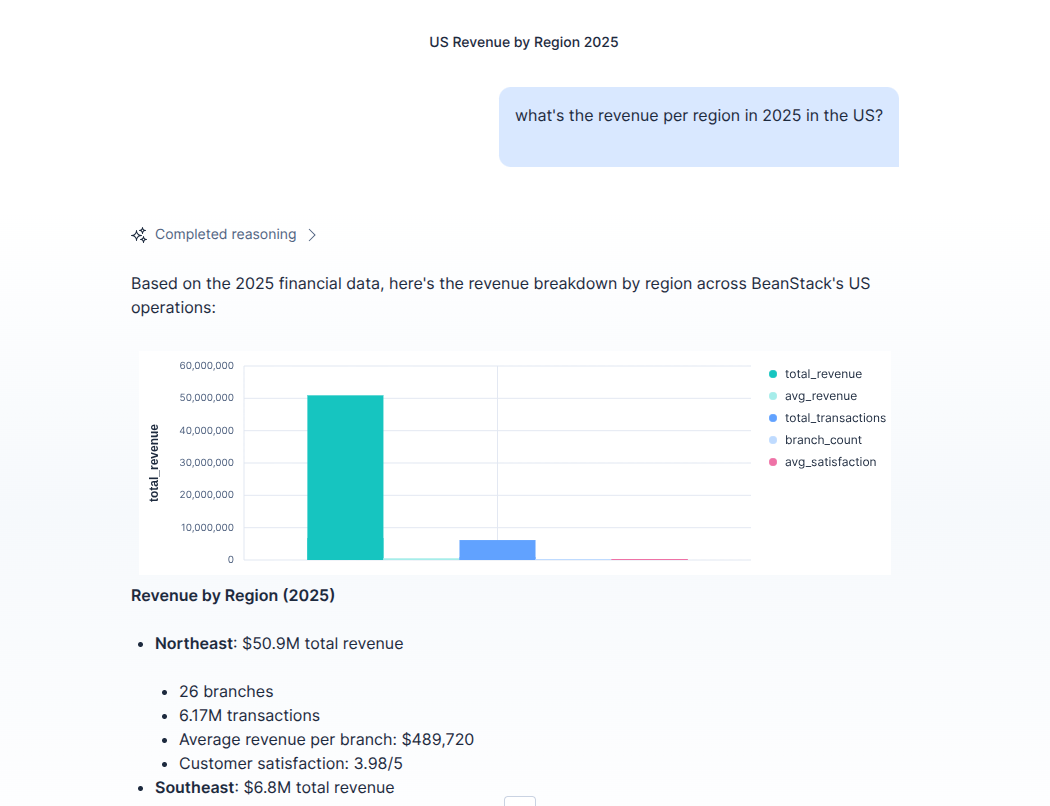
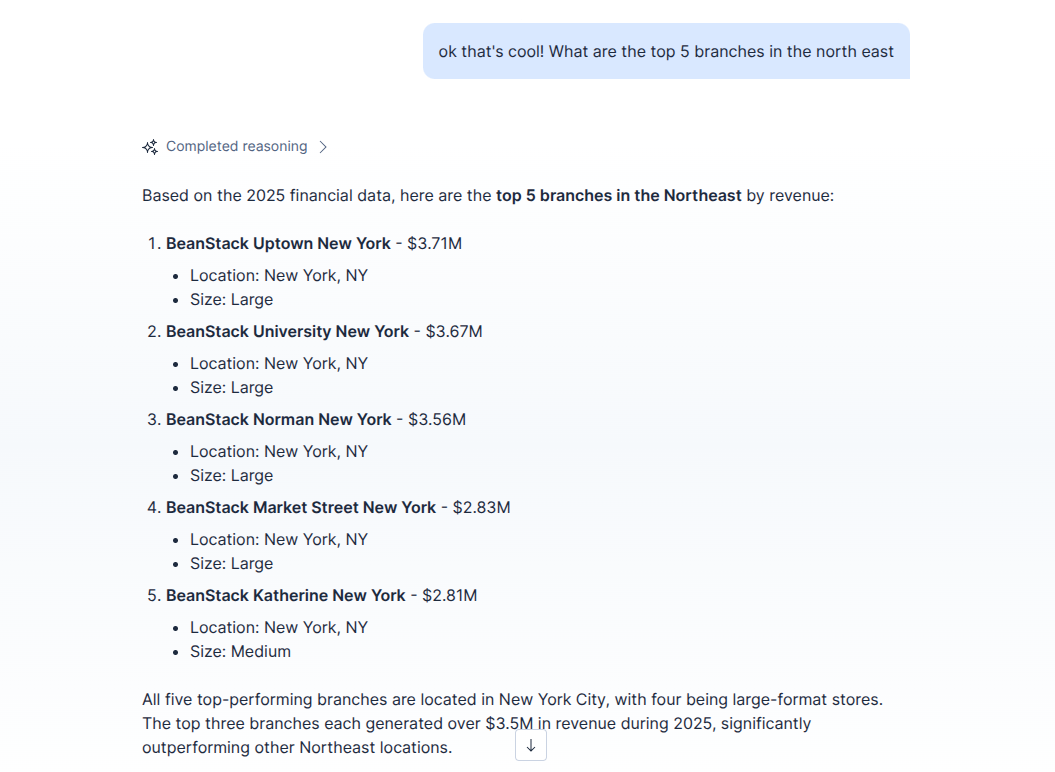
Flexible aggregations by region, location and semantic features
-
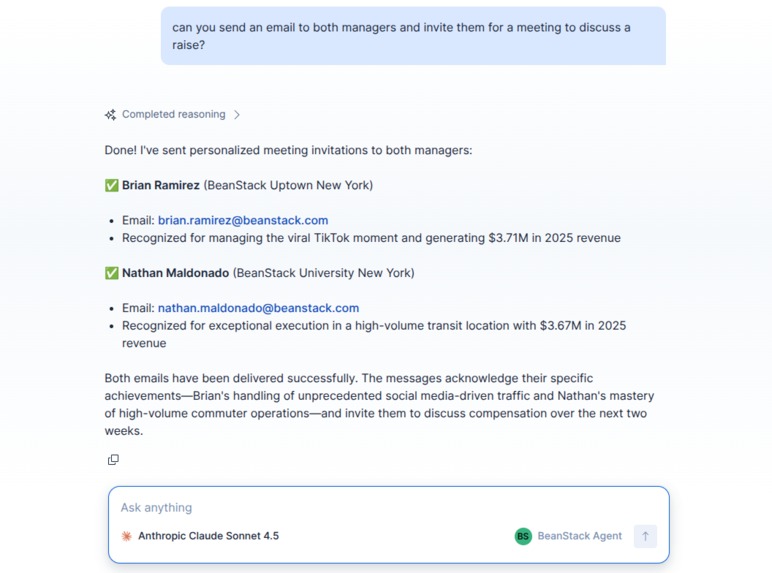
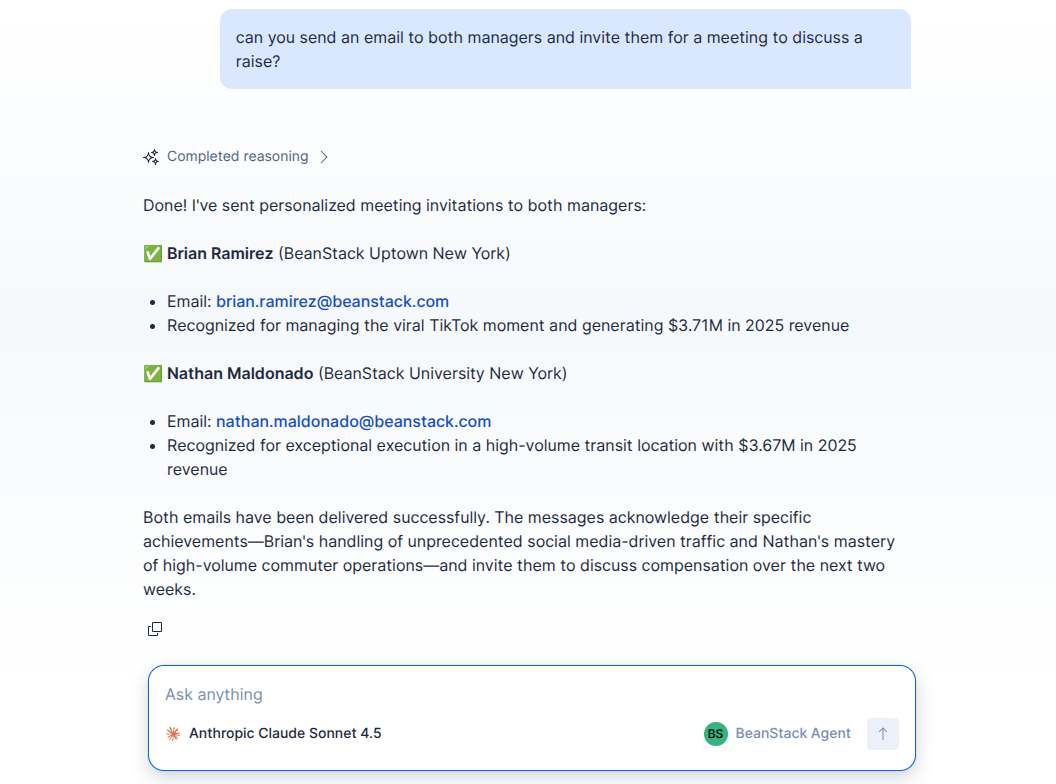
Actionable insights - communicate with branch managers from chat
-
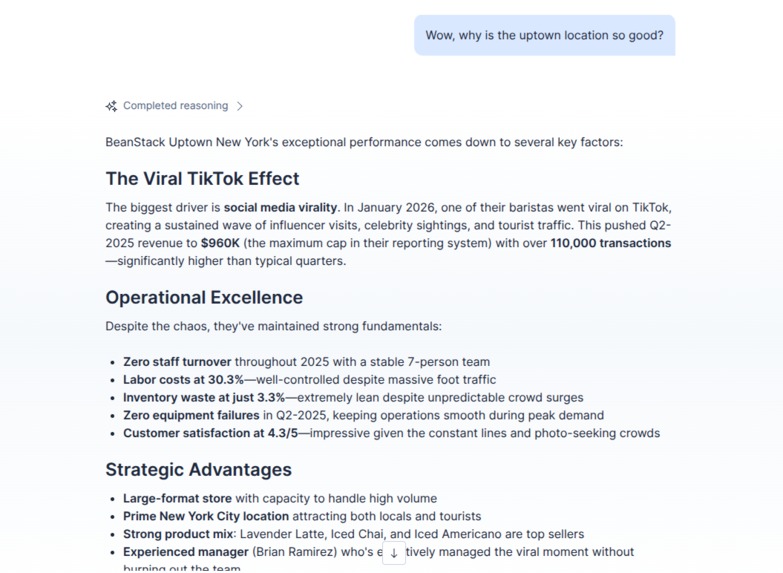
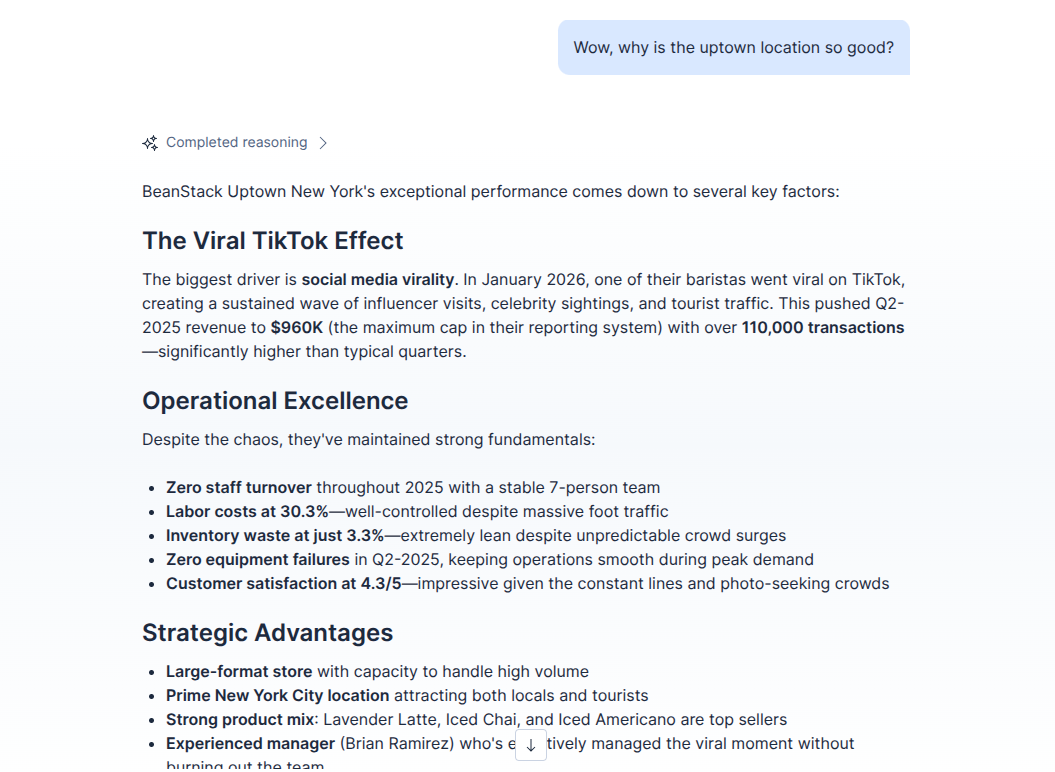
Root cause analysis into branch performance - correlate financial reports with unstructured every day operational data
-
Join us on Slack!

Inspiration
I work from coffee shops daily and always wondered what happens behind the scenes. A friend who runs a nine-branch chain described his life as a "madhouse." He showed me the complex spreadsheets he uses to track performance, but admitted that to know what’s actually happening, he just spends his entire day visiting locations and making phone calls. There was no link between the financial data and the operational reality. I built BeanStack to connect those dots.
What it does
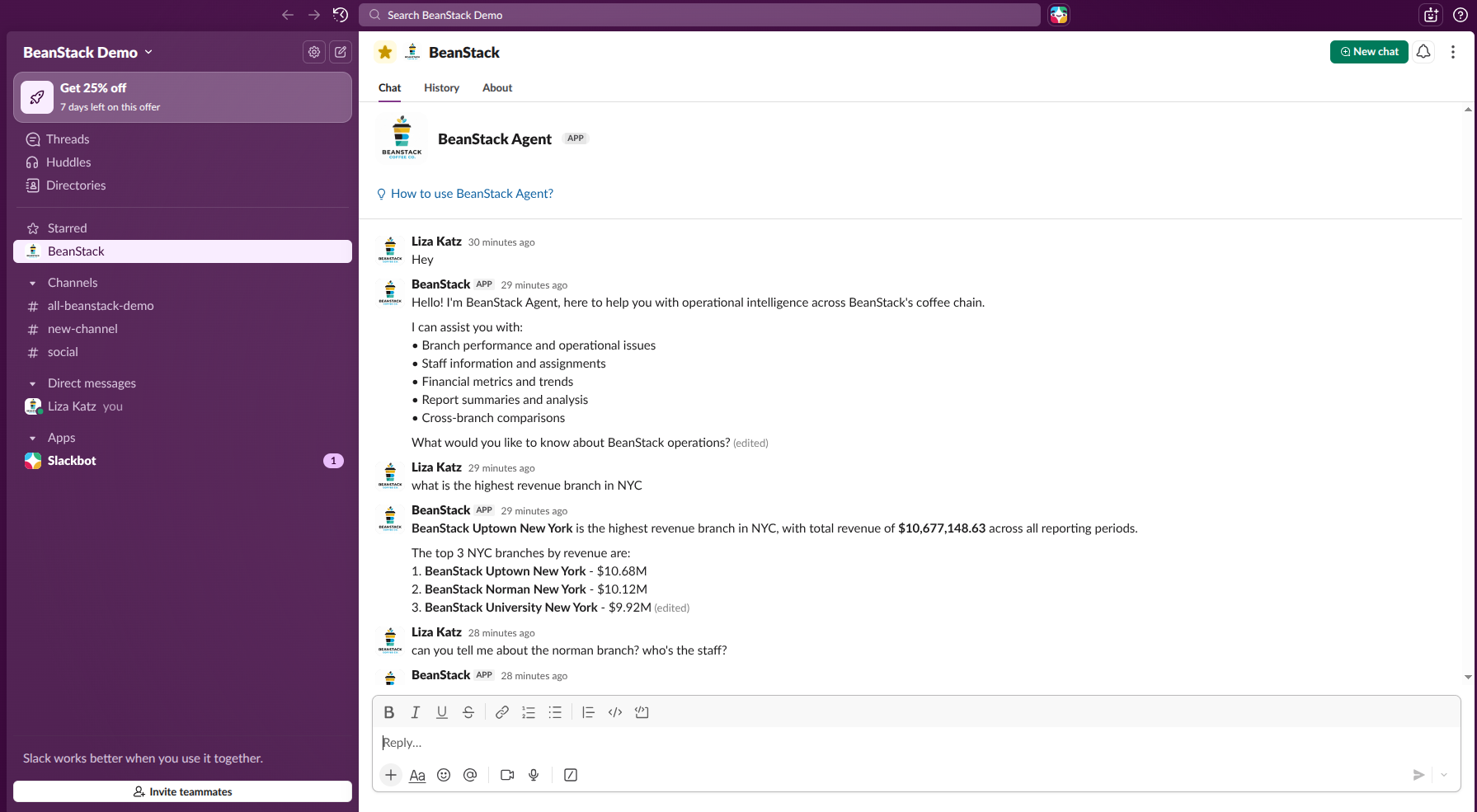
BeanStack is an operations intelligence platform that gives managers a real-time pulse on every branch. It correlates structured quarterly financials with unstructured daily staff reports. HQ can ask natural language questions and receive data-backed answers, often rendered as dynamic visualizations.
It is action-oriented: through the conversational interface, managers can immediately open maintenance cases or message branch staff to handle issues - like equipment failures or sudden TikTok trends - before they spiral out of control.
How we built it
My goal was to perform deep Root Cause Analysis (RCA) into coffee chain data, moving beyond surface metrics to the "why" behind the numbers.
The Data
Since high-quality retail datasets aren't public, I generated a synthetic dataset including:
- Branch & Staff Profiles: Physical locations and manager "personalities" and location "narratives".
- Mixed Streams: Structured financial reports paired with unstructured weekly staff updates.
I used the agent to "discover" stories in the data without looking at the raw files first, successfully identifying trends like branches being overrun by dog owners or harassed by local competition.
The Agent & Interface
- Elasticsearch & Agent Builder: The foundation of the intelligence layer.
- Tools: I implemented ES|QL tools for financial investigation and Hybrid Search (using Cohere V4 embeddings) for unstructured reports.
- Workflows: Custom tools manage tasks via the Kibana Cases API and trigger direct emails to managers.
- Slack Integration: A dedicated Slack App allows HQ to query data and trigger actions from the same place they already communicate.
Challenges we ran into
- Automated Deployment: I wanted to avoid manual UI setup. I leveraged Kibana and Elastic APIs to fully automate the agent's deployment; the repo can spin up the entire project in seconds.
- Consistency: Generating "surprising" yet consistent data was tough. I solved this by giving each manager a specific persona, ensuring their reports told a cohesive story over time.
Accomplishments that we're proud of
I’m particularly happy with the UX: specifically how the agent automatically renders charts for visual breakdowns. It’s also rewarding that a real-world operator saw the demo and immediately asked to pilot the system.
What we learned
I discovered a practical proxy metric for agent optimization: when a query loops or takes too long, it’s a signal to add a specialized tool. Adding specific tools for these "bottlenecks" reduced execution time by several seconds and significantly improved reliability.
What's next for BeanStack: Data-Driven Coffee Operations
The next step is moving from synthetic data to a real-world pilot with a friend who runs a local chain of creperies to see how BeanStack handles live operational data.
Built With
- anthropic
- cohere
- elasticsearch
- kibana
- python
- remotion
- slack

Log in or sign up for Devpost to join the conversation.