-
Pipeline
-
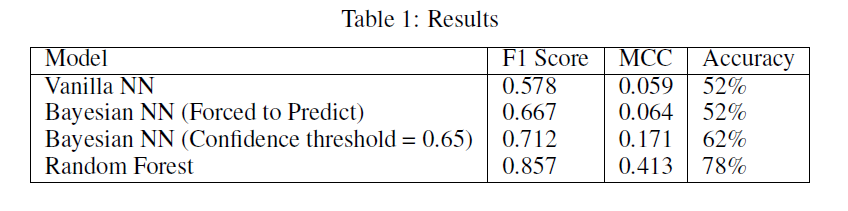
Results
-
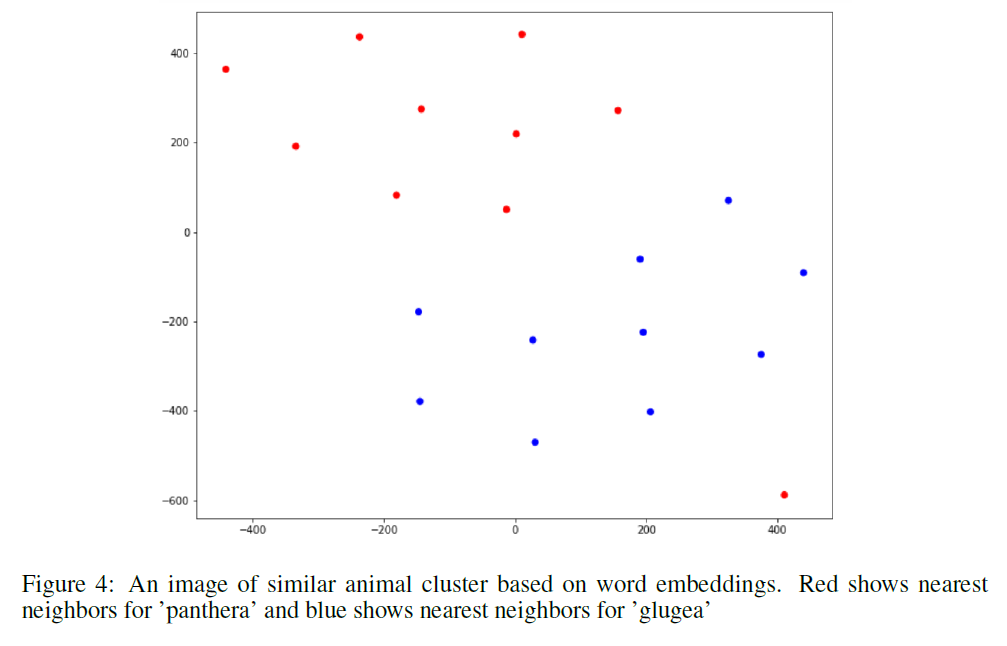
Clustering
-
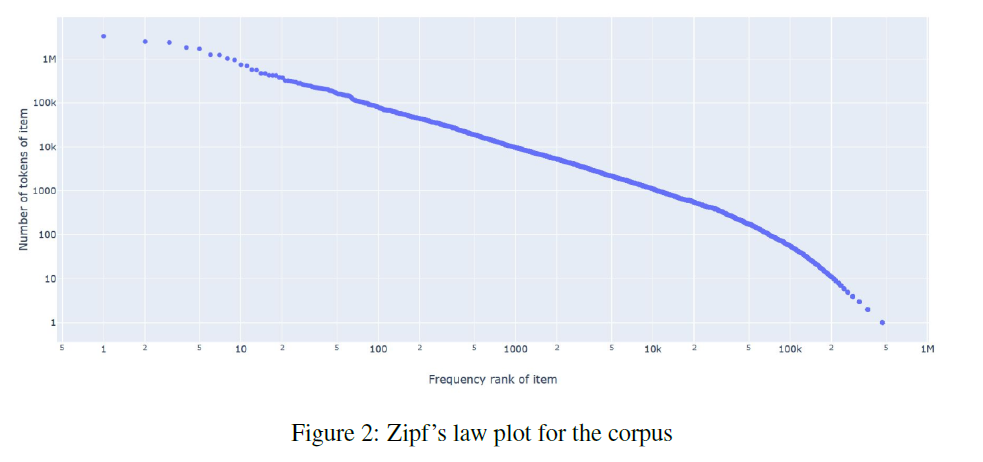
Zipf's law
-
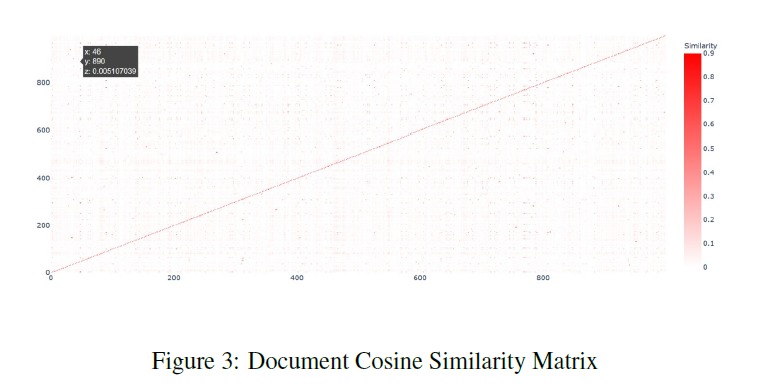
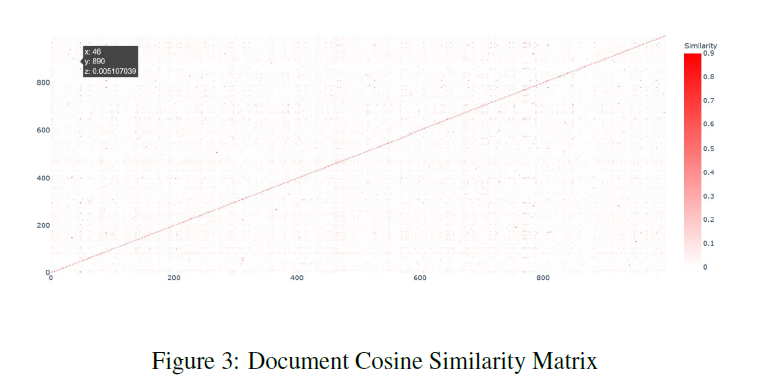
Cosine Similarity
Inspiration
After the Amazonian and the Australian fires, the world lost a huge part of its ecosystem with many species getting endangered/ functionally endangered/ extinct. Machine and deep learning have been implemented in many research areas like medicine and thus enriched a lot of lives through smarter living. So, I wanted to extend this to make prediction of the redList status of animal species easier and thereby save many more species that we have not been able to so far.
What it does
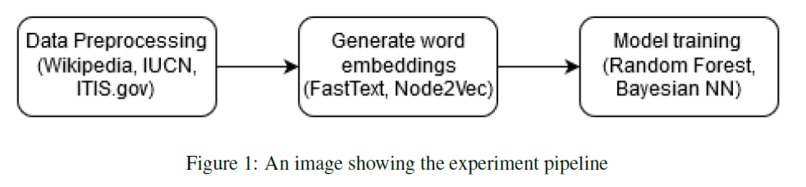
There are two major causes of extinction of animal and plant species. It can be because of either the habitat of the species impacted due to several reasons or the loss of genetic variation. To capture the information of the former, I have introduced the use of fasttext to bring out the subword information from a text corpus obtained through Wikipedia articles while for the latter, I have employed the use of node2vec. These two approaches give us word embeddings for scientific names involving genus and species of every animal that carry all this information across N dimensions. Using this, prediction of the redList status of all the animal species can be studied and analyzed.
How I built it
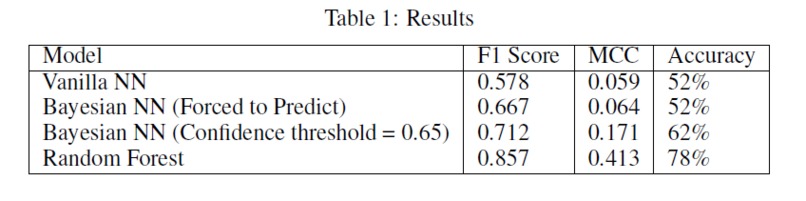
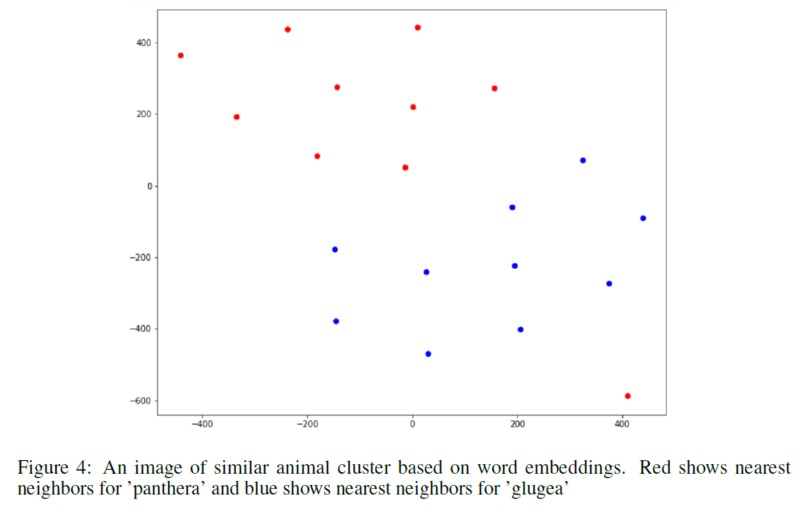
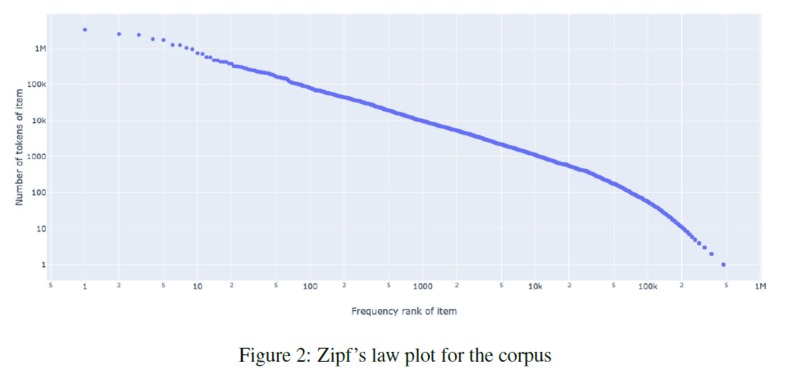
To generate the text corpus for training the fasttext model, I crawled Wikipedia articles for scientific names of every animal species in the animal taxonomy. In order to evaluate the quality of this text corpus, I generated tf-idf vectors for all documents (each document corresponds to a wikipedia article for a particular animal species) and calculated cosine similarity between each document. I inspected N-most similar documents for a few documents selected at random. I performed several data cleaning and preprocessing steps and obtained the final training text corpus. I also did some analysis on this corpus. I plotted a graph for Zipf’s law as shown below to validate the corpus following natural language properties. Then I ran some experiments to find the nearest documents for different species via cosine similarity and saw that I got similar species as top 5 documents. I even plotted the cosine similarity matrix for first 1000 documents. All the data cleaning, preprocessing and analysis was performed using PySpark. Using fasttext on this corpus with window size of 3, I generated 200-dimensional word embeddings for each word and thus obtained word embeddings for each scientific name as well. Scientific names are a combination of genus and species, hence I take a simple average of the two to generate the final fasttext embeddings for each animal species. I also assessed the quality of these word embeddings by looking at the nearest neighbors and verify that morphologically similar words are indeed being identified as similar words. I then collected the hierarchical information of the animal taxonomy from itis.gov. The database contains hierarchy for every species using which I built a graph with nodes as every taxonomic rank and the edges depicting the relations. After generating this graph, I used node2vec to generate another 200-dimensional vector representations for each node in the graph and obtained word vectors for all species. For node2vec, I used the skip-gram model with a window size of 3 and trained it for 10 epochs with default settings of other parameters as described in Grover et. al. (2017). I then concatenated the 200-dimensional embeddings obtained from fasttext and node2vec to obtain a 400-dimensional embedding which was later used as feature input for the machine learning classifier.
Challenges I ran into
Not easily available dataset, had to crawl Wikipedia, build graph out of publicly available database of animal taxonomy of all the species in the world to generate custom embeddings. A lot of work was needed in the data department.
Accomplishments that I'm proud of
Managed to accomplish a lot of things in such short time and also was able to incorporate many of the features I had planned to.
What I learned
Importance of data and feature engineering in machine learning
What's next for Bayesian RedList Classification
Refine the results with additional features such as explicit geography and animal traits data.
Built With
- bayesian-learning
- fasttext
- machine-learning
- node2vec
- python

Log in or sign up for Devpost to join the conversation.