-
-

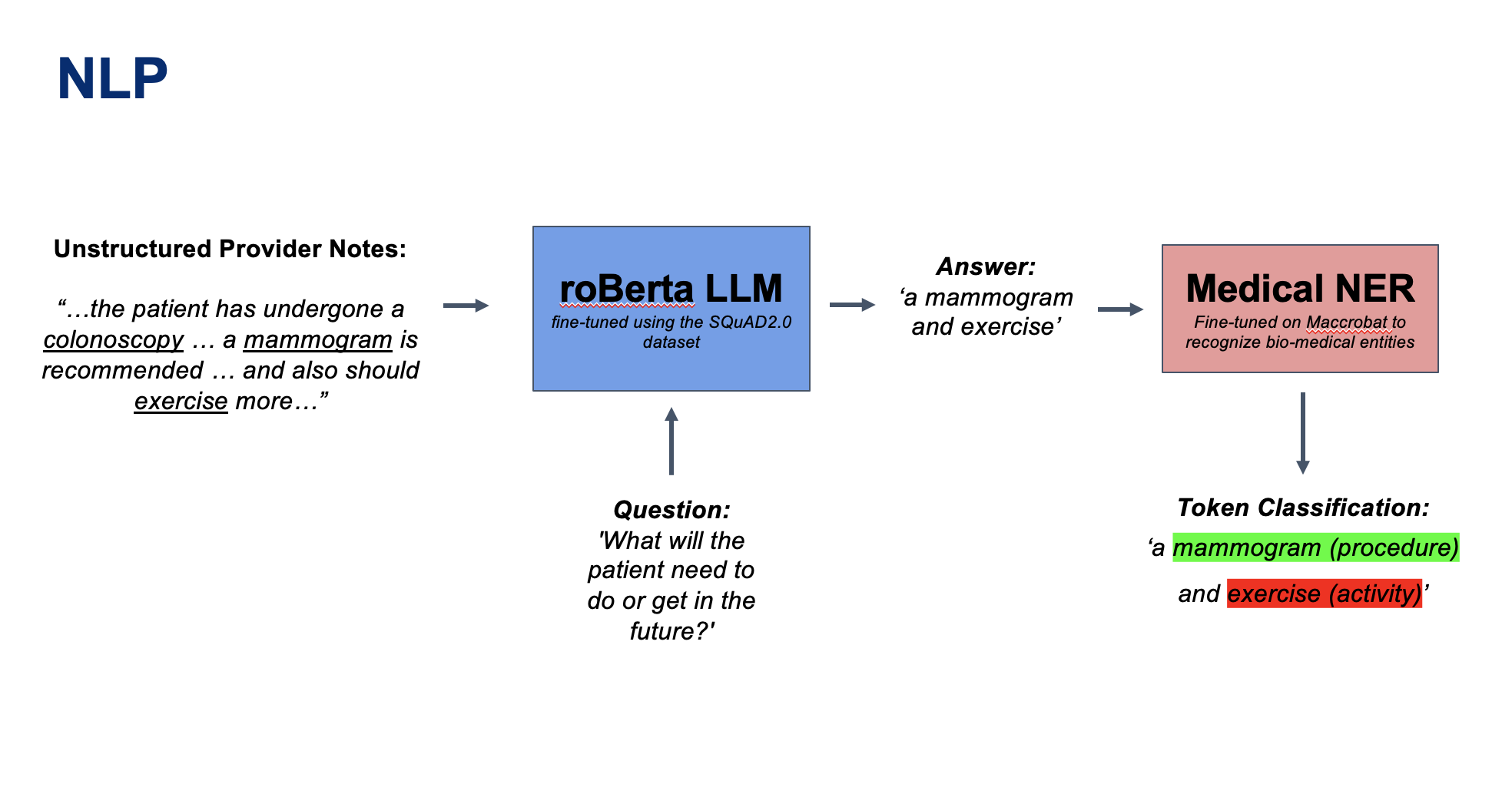
NLP Pipeline
Inspiration
When speaking to the mentors (shout out to the fantastic mentors!), I learned that payers have a problem in obtaining near future insights from unstructured health provider data. As told by one of my mentors, "10% of the value is derived from structured data & 90% from unstructured data" like provider notes and summaries. This information can help with risk adjustment and forecasting for payers. Even though it's easy to get structured information about the past and what it costs through querying datasets, numerical analysis and prediction with ML on easily available patient records can provide limited insight.
What it does
The General Vision/Goal
Create infrastructure that queries health records (in CCDA or FHIR) as well as the latest unstructured provider summaries/notes to determine risk and predicted cost. I will go into specifics in the "What's Next for Basically" Section
I have a big vision and a little time for the hackathon. So for this hackathon, I implemented a web app demonstrating the use of natural language processing. (The process is in the "NLP pipeline" image on the page.)
- Enter a mock provider summary.
- That summary is used for the Question Answering (QA) Large Language Model (LLM) context. The model is then asked, "What will the patient need to do or get in the future?".
- The named entity recognition (NER) model will then classify the tokens (words) of the QA-LLM's answer. Why? Because the QA-LLM doesn't have a biomedical understanding and NERs don't just do a dictionary search. They break down words into parts (just like we learned in elementary school) allowing them to classify procedures that haven't been seen before.
- The pipeline extracts the words that were classified as therapeutic/preventative procedures and query their average cost.
- See the predicted future cost of the member and their percent difference from the average member.
The best part: Everything in the demo is visualized for you!
How I built it
For the QA LLM, I used the roBerta LLM which was fine-tuned using the SQuAD2.0 dataset (a big question answer dataset). For the NER model, I used a distilBert model that was fine-tuned on the Maccrobat Dataset in order to recognize the bio-medical entities.
The rest:
- Streamlit for the web ui
- pure python to bring it all together
Challenges I ran into
The CCDA parsing python library didn't work so I decided that the NLP demo would be most useful.
Accomplishments that I'm proud of
I'm proud of being able to make explainable AI through the web UI and use two LLMs together to make something useful!
What I learned
I learned so much about the problems facing payers which trickles down to affect its members. I didn't know there was such a huge need and opportunity for NLP in this space.
I learned how to show the use QA and NER LLMs together. I didn't know how to use streamlit before either until now. I feel like my NLP skills definitely leveled up.
What's next for Basically
Don't worry. I intend to continue this project. TODO:
- Connect other databases to find the average costs of various procedures.
- Add the ability to query CCDA & FHIR to provide more context to the NLP and cost estimation.
- Add the ability to determine future risk from the data mined from the NLP and from past structured information.
- Demo how this could be used with large datasets, not just one member at a time. It would show the total cost and how each member is relative to the average in an interactive table.
- Be able to visualize with histograms the members' costs and risks.
Built With
- python
- streamlit

Log in or sign up for Devpost to join the conversation.