-
-
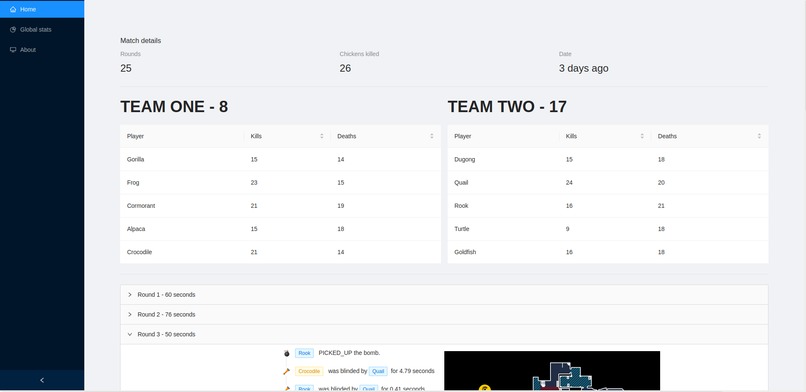
Match scoreboard
-
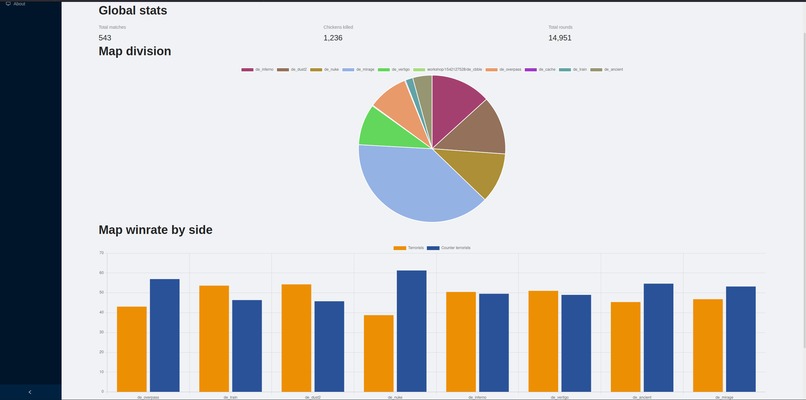
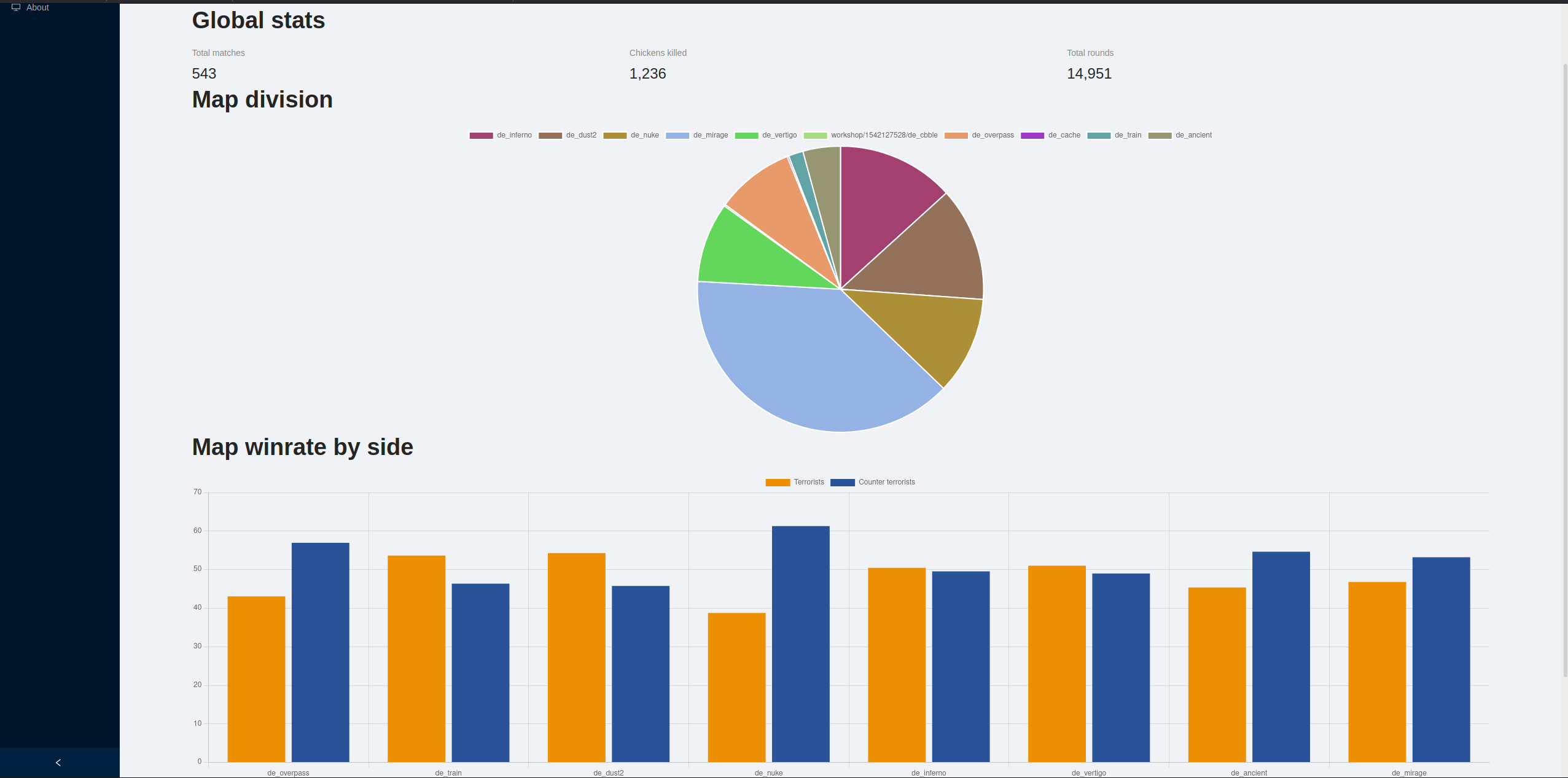
Global statistics
-
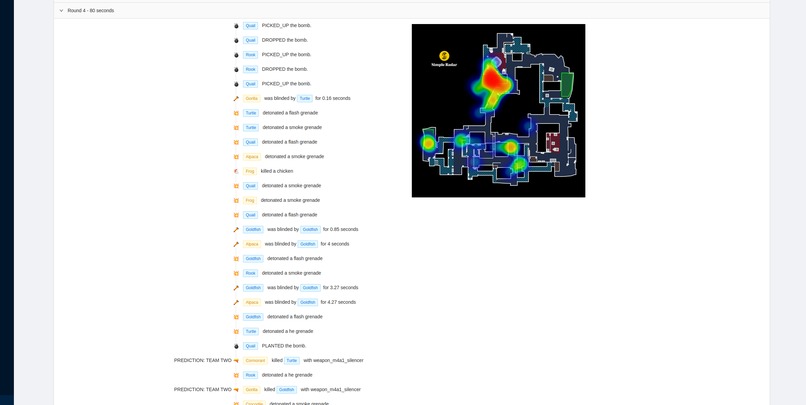
Detailed round data
-

System diagram


Inspiration
Given the hackathon requirements, we knew we had a lot of choice in what we were going to make. We wanted to make something that could utilize Graviton2 processors though, so something CPU intensive.
We're both big fans of the game (over 6000 hours played between us two over the years) and we've always wanted to tackle something like this!
What it does
Bantr retrieves demofiles (files container all the raw data about a match), parses it and stores it. After that, we run statistical analysis on the data, train a machine learning model and calculate global statistics. Finally, all of this is displayed in a frontend
How we built it
We used many different AWS services, like S3, SQS, Lambda, DynamoDB, DocumentDB, and ofcourse EC2/ECS with Graviton2 processors. In terms of programming languages, we used JavaScript (Typescript where it made sense) and Python.
We use ingame recordings called demo files to detect lots of information during games. The system consists of different modules, which are responsible for different tasks. In this README, you will find a high-level overview of each module. For more details, you can find a README in the respective module folder.
Faceit scraper
Faceit is a third-party service for CS:GO matches. They provide demo files for each match played. Our scraper downloads these demo files and stores them in S3 for further processing.
The S3 bucket has a trigger, which is executed every time a new file is uploaded to the bucket. It pushes a new message to SQS.
Demo parser
Downloads demos from S3 and parses them (didn't expect that did you :)). This is a rather CPU-intensive task which makes for an ideal candidate to run on Graviton2 processors.
Once the demo file is parsed, all data is written to DocumentDB.
Stats / machine learning
Stats
The stats module reads data from DocumentDB and calculates global statistics. We write the results of these calculations to DynamoDB so they can be quickly read by the API.
Machine learning
We made a C-Support Vector classification model to predict the outcome of a round. Currently, the model is a binary classification with the states: team1 wins or team1 loses.
To train the model demo data is collected from DocumentDB, which is further processed into valid features. Periodically, predictions are added to new available data in the documentstore.
API
The API consists of several Lambda functions. Each function talks to either DocumentDB or DynamoDB to fetch data.
Frontend
The frontend was written with React using Umi as a framework and Ant Design as component library.
Challenges we ran into
Downloading data from the internet on a ECS container is expensive! In hindsight, it would have been much better to run our scraper external to AWS with a provider that offers infinite bandwidth. S3 charges nothing for data uploaded from the internet.
Initially, we wanted to do live match predictions. We could get this data via the GOTV protocol (essentially, it's demo files but live streamed) but finding these broadcasts and understanding/integrating the protocol proved to be very time consuming. Ultimately, we decided to pivot and not do live predictions.
Accomplishments that we're proud of
It works! That's a big one ;) In all seriousness though, we're very proud of the finished product. It's a lot of small components that really came together in the end. It's hard to pick one specific thing to say here, there's so much cool stuff in the project!
What we learned
We learned SO MUCH about running software on AWS. From setting it all up, to keeping it running and troubleshooting.
What's next for Bantr
Maybe get live match predictions working? :)
Built With
- amazon-web-services
- ecs
- lambda
- node.js
- python
- sqs
- typescript

Log in or sign up for Devpost to join the conversation.