-
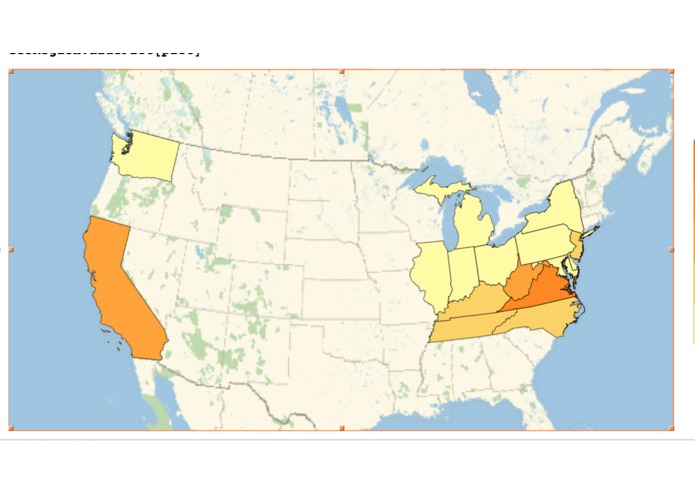
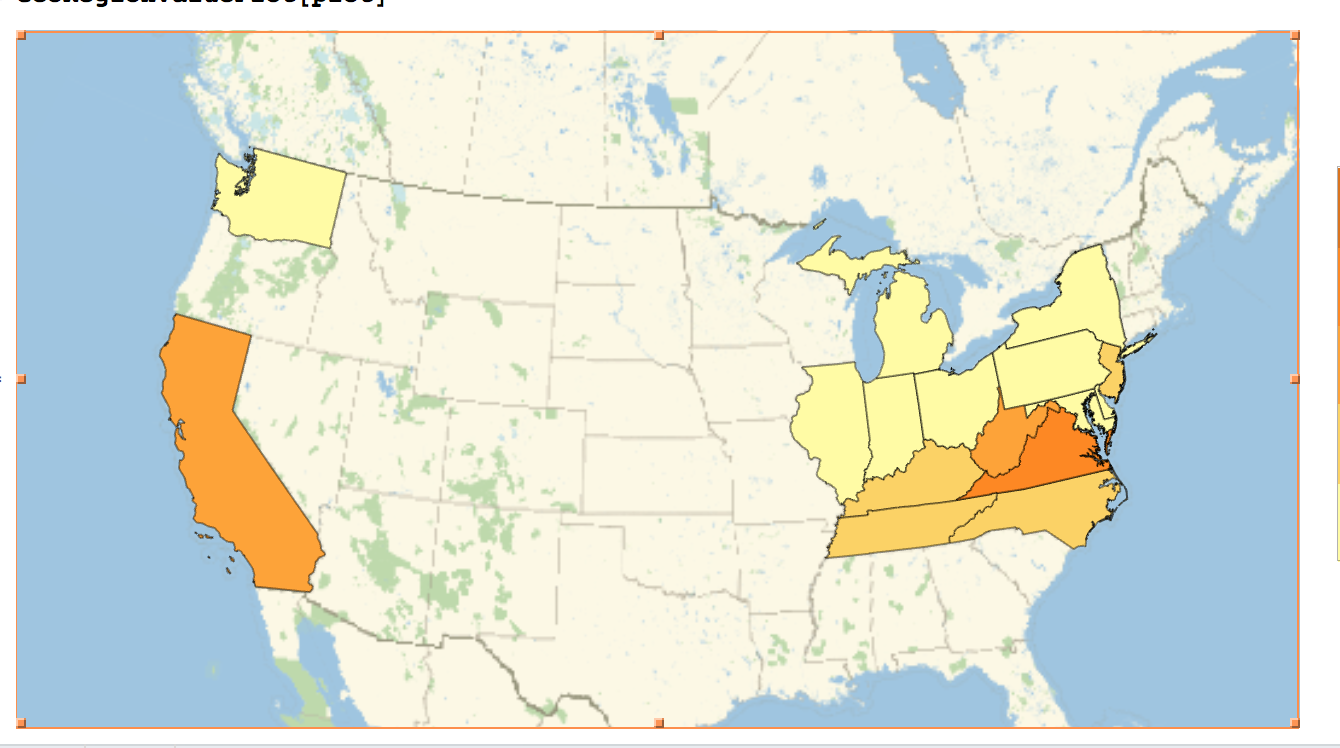
Average bank balances across the US.
-
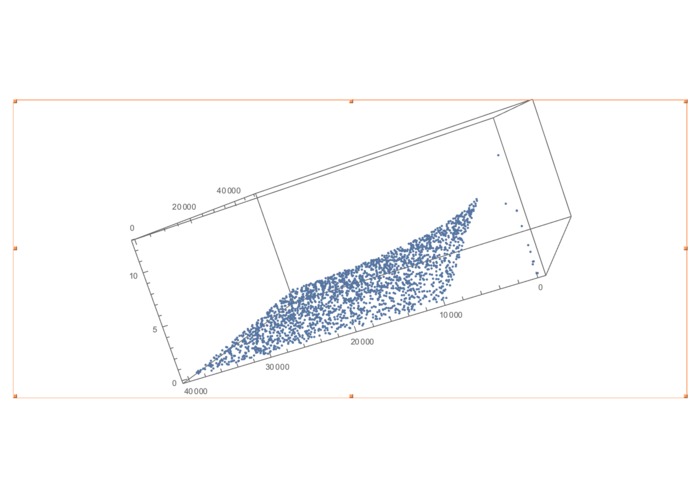
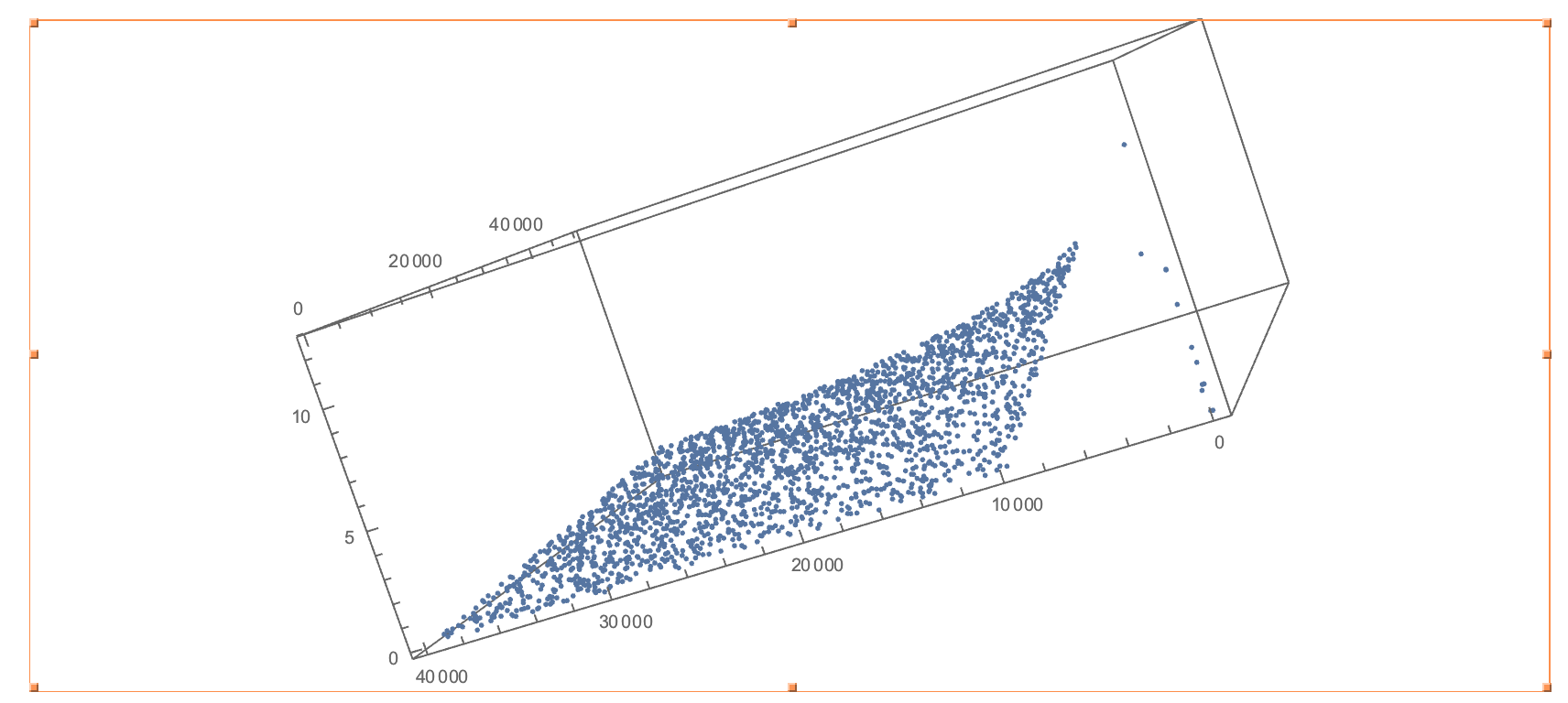
Ratios of balances and rewards.
Inspiration
Data is always better represented and understood visually. Sometimes big excel sheets of numbers don't reveal patterns that would otherwise be obvious in visual representations. This motivated us to use Capital One's API to fetch the data that would doesn't say much on its own, but when plotted in different ways through Wolfram Mathematica, clear patterns become obvious.
What it does
We built a python program that fetches data from the API. This data is then parsed by two other python programs. One of them correlates average balance in banks to states nationwide. Our representation is limited by the data provided but easily extensible. The other one shows a correlation between the balance and the reward points in various peoples accounts.
How I built it
We spent most of our time learning Wolfram Mathematica, but it was worth it. We were inspired by the tweetable programs so we wanted to make our code as efficient as possible - hence all our Mathematica programs are less than 10 lines long. Figuring out the correct visuals and truncating boundary values was also a challenge.
Challenges I ran into
Learning the API took some time, and then trying to integrate our data into Wolfram Mathematica was challenging. Finding the best the visualizations for the data took a lot of time because we sampled our data on various visuals.
Accomplishments that I'm proud of
We had two first time Hackers and we were able to build a project that we are proud of. We were all able to effectively contribute to the project by dividing the tasks between ourselves.
What I learned
We learned Mathematica which is probably going to be very useful for further projects in college. We also saw some interesting relationships between the datasets.
What's next for Banklytics
We are going to try and analyze real world data from various sources based on our platform. This will actually let us discover trends that affect bank transactions. We are also planning on extending our platform to start Princeton's first Fintech club.

Log in or sign up for Devpost to join the conversation.