Inspiration
-Customer churn is a major problem of customers leaving your products/subscription and moving to another service. To retain them, they need to identify the customers as well as the reason for churning so that they can provide the customers with personalized offers and products.
How we built it
link -Part 1: Data Exploration: Visualize data, create histograms, box plots, and heatmaps to understand the distributions visually, and check if there is skewness in the data.
-Part 2: Feature Preprocessing: Before performing predictive analysis, data must be cleaned and formatted. Non-relevant variables in the predictive analysis are therefore dropped. Categorical and ordinal data is encoded, and continuous data standardized
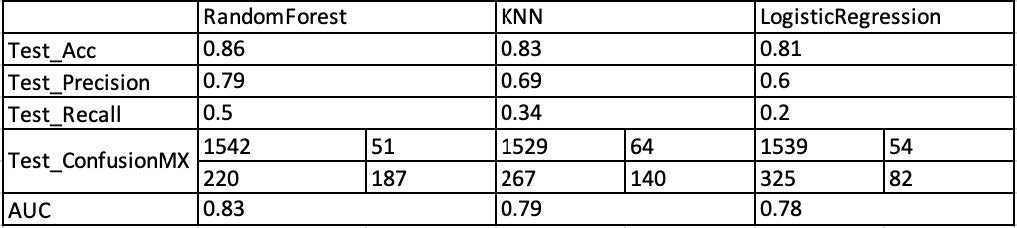
-Part 3: Model Training and Result Evaluation: Find the best performance models with Random Forest(baseline), K-nearest Neighbor(non-baseline), and Logistic Regression. Also, perform a grid search to find the best parameters for those Classifiers. Evaluate the models using the confusion matrix (precision, recall, accuracy), ROC, and AUC.
-Part 4: Feature Importance: Add L1 and L2 regularization to logistic regression to check the coefficient for feature selection. Moreover, check feature importance of random forest for feature selection
What it does
-This project aims to identify customers who are likely to churn in the future using supervised learning models and analyze the top factors that influence user retention.
Challenges we ran into
-The difficulty of this regression problem is that it has a limited number of training samples with an imbalanced dataset (Stays - 79.63% and Exits - 20.37%). It has very weak correlations in general as well.
Accomplishments that we're proud of
-This project achieved the highest accuracy with Random forest at a test accuracy of 86% and recall of 50%. Other supervised models exploited a similar, however worse performance.
What we learned
-This real-life problem can also be extended to other domains wherein a similar the approach can help companies know ahead of time about their customers and accordingly, take action.
What's next for Banking customer churn prediction and analysis
-Further expectations of this project include:
- Deal with imbalanced data with imbalance handling techniques, such as SMOTE, to get better performance for improvement.
- Use finer hyperparameter tuning and extract more data points.
- Apply the models above to a more difficult problem to see if the conclusion above still holds.


Log in or sign up for Devpost to join the conversation.