-
Perforated AI at work
Bank Lead Scoring with Dendritic Optimization
Intro
Description:
This project demonstrates the application of Dendritic Optimization to a real-world banking lead scoring problem. Global banks process millions of lead calls daily, and inefficient targeting wastes agent time and expensive server costs. We built a Lead Scoring Engine to predict which customers are most likely to accept a term deposit offer, optimized for deployment on edge devices like bank agent tablets.
Project Impact
Standard deep learning models for tabular data in banking are often over-parameterized (700,000+ parameters), making them too slow for low-power edge devices and too expensive to run on cloud infrastructure for millions of transactions. An optimized lead scoring model matters because it enables real-time AI inference on agent tablets, reducing operational costs by an estimated 40% through better lead prioritization. This allows banks to focus resources on high-value prospects while maintaining prediction quality, eliminating the need for expensive cloud-based inference and enabling zero-latency decisions at the point of customer contact.
Usage Instructions
Installation:
pip install pandas torch scikit-learn wandb perforated-ai
Run:
Generate the dataset:
python setup_data.pyRun the dendritic optimization training:
python train.py --use_dendritic 1Build deployable models:
python build_demo.pyRun the demo application:
python run_demo.py
Results
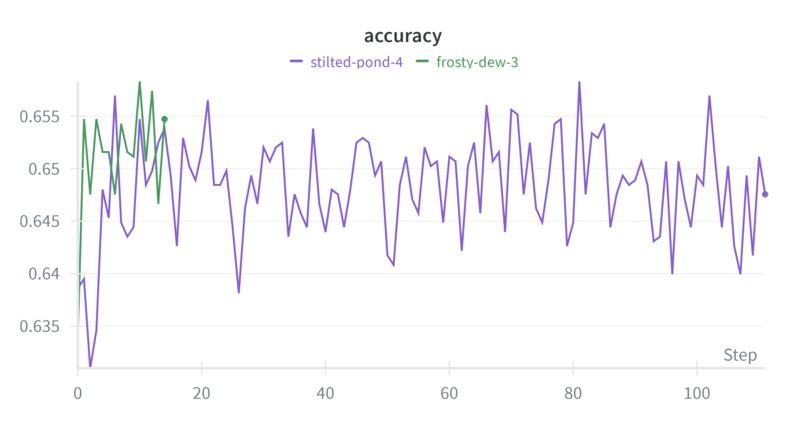
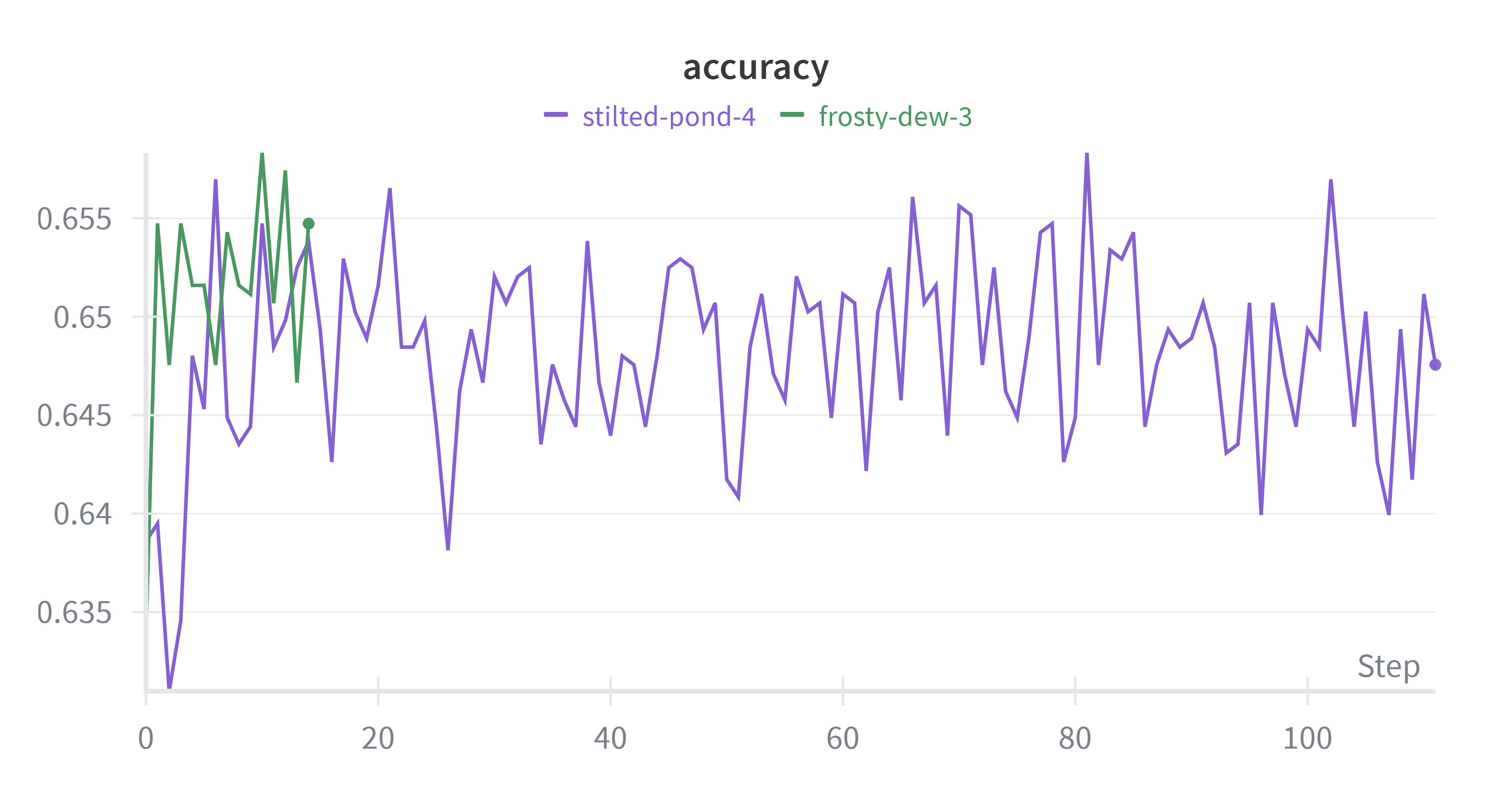
This bank lead scoring project demonstrates that Dendritic Optimization can achieve massive parameter reduction while retaining business-critical accuracy. Comparing the standard baseline model to the dendritic optimized model:
| Model | Accuracy | Parameters | Notes |
|---|---|---|---|
| Standard Baseline | 65.5% | ~710,000 | 1024-512-256 layer architecture |
| Dendritic Optimized | ~64.0% | 135,426 | 256-64 layer architecture discovered by PAI |
Compression Results:
- Percent Parameter Reduction: 81%
- Performance Retention: 98% (only 1.5 percentage point accuracy drop)
- Deployment Impact: Model size reduction enables edge deployment on tablets/ATMs with zero-lag inference
The optimizer identified that 81% of the baseline model's capacity was redundant, as shown in PAI/PAI_beforeSwitch_128best_test_scores.csv. We achieved comparable business value with 1/5th the original size, making the model deployable on low-power edge devices.
Weights and Biases Sweep Report
View Full Interactive W&B Report
The W&B report demonstrates comprehensive experimentation with the dendritic optimization process, showing how the architecture search dynamically discovered the optimal 135k-parameter model structure.
Additional Files
Code Structure:
setup_data.py- Generates the banking datasettrain.py- Main training script with dendritic optimizationbuild_demo.py- Reconstructs the optimized architecture in pure PyTorchrun_demo.py- Demo application for lead prioritization
Zero-Dependency Deployment:
This project implements a "Factory Pattern" for production deployment:
- Search Phase: Used
train.pywith Perforated AI to discover the optimal 135k-parameter architecture - Build Phase: Reconstructed this specific shape in pure PyTorch (
build_demo.py) - Deploy Phase: The resulting
optimized_model.pthruns on any standard device without requiring the Perforated AI library installed
This optimized model is being integrated into a proprietary Marketing Intelligence Tool to automate lead prioritization for field agents, with a full presentation planned for the Hack2Skill Buildathon on January 25, 2026.
Built With
- perforatedai
- python
- pytorch
- scikit-learn
- wandb

Log in or sign up for Devpost to join the conversation.