-

The logo for BallerB0t
-
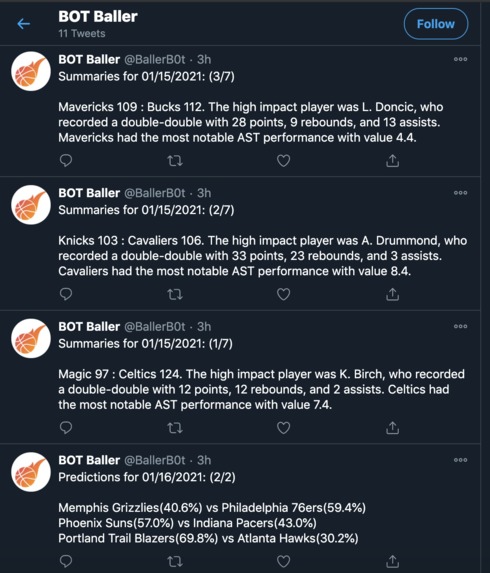
Sample tweets from BallerB0t


Inspiration
Every day, numerous NBA games occur anytime between 10 a.m. and 7 p.m. PST. For all different kinds of NBA fans, it is simply impossible to balance academics, a job, or other commitments while still keeping up-to-date by watching match highlights and reading articles. Furthermore, sports reporting can often be subjective with post-game interviews that include sentiments and hypothetical statements. This is why we wanted to find a system that primarily uses quantitative factors to present a useful recap of basketball games. Our product, BallerB0t, is an efficient and easily accessible solution.
What it does
BallerB0t is a bot, coded in Python, that tweets predictions on today's NBA games as well as summaries on the results of yesterday's games. Summary tweets include the final score of the game, a sentence about a notable individual performance, and a sentence about a notable team statistic. Prediction tweets cover the upcoming games for a day, giving a percent chance that a given team will win their matchup.
How we built it
We started by creating a Twitter bot that used the tweepy API to generate certifications for authentication. It relies on a Flask API that serves programmatically created statements for match predictions and predictions from a Sqlite database. We chose this SQL format due to its portability and since the formatted tweet phrases would be relatively short and simple. The schedule API is included to automate the generation of predictions and summaries.
Match summaries are created using Pandas data analysis of box scores to extract the most salient statistics that describe both player and team performance. Notably, new functions that focus on different aspects of games like defensive or offensive efficiency can be easily built - currently we are using a function that is centered on double-doubles and triple-doubles since they highlight players who performed well both offensively and defensively.
For predictions, BallerB0t uses a Random Forest Classifier with 75 estimators and a max-depth of 8. Having too many estimators would cause a timeout, as well as use more of the CPU with only a small increase in accuracy. We trained BallerB0t using statistics, adjusted per 100 possessions, across 3 seasons: 2016-2017, 2017-2018, and 2018-2019. We based our predictions off of several features, including the home team, rebounds, turnovers, win rate, offensive rating, defensive rating, and true shooting percentage. Ultimately, we obtained an accuracy of 65% on our testing set.
Challenges we ran into
We experienced an issue right at the start, with trying to identify a project. We knew we wanted to implement a technologically complex backend, but we were unsure of how to do that for entertainment. Originally, we started with a jigsaw puzzle game, but after contemplating further, we decided to change to this project. Another issue we discovered was a timeout in the random forest model while running the project. This was a random occurrence, where an extended runtime caused an html timeout. This issue was due to the dependency on the nba api, which had this as a common error. It was supposedly fixed in the current version, but the error still persisted.
Additionally, ESPN does not offer public API keys, so we had to use multiple data sources, in order to find sufficient data sources. Some thought and brute force was involved in creating a web scraping script that could effectively gather data from post-game box score reports on the ESPN website. This led to a lot of dependencies and we occasionally had issues with linking code that relied on different data formats.
Accomplishments that we're proud of
We are proud that we made a quite complete product. The summarizing system works on practically all NBA games on ESPN, and the prediction system utilizes a model with a fairly high accuracy rate. The team was quite efficient, since we had a project that leveraged our collective skills such as machine learning, web development, and data processing.
What we learned
We learned about how to create and utilize a twitter bot to post at scheduled times. Additionally, we improved our skills in webscraping with BeautifulSoup and formatting with Pandas. In addition to programming skills, we strengthened our overall teamwork and collaboration skills in a project context.
What's next for BallerB0t
We had some failed predictions from our initial tests. Our model still has room for improvement because we don’t factor in everything. Since our data is mostly integer points (Free throws, points scored, etc) we leave out factors such as injuries, mentality of players, etc. While we do have a relatively high accuracy, there is definitely room to improve our model.
We also hope to improve our player summaries, with more information, better statistics, and an overall improvement of the analysis. We hope that this will be used in the future to give visibility to underrated players. Since the finalized tweets are stored in a database format, we maintain a backlog of information that provides direct material for the improvement of our summary generation and match prediction algorithms.
Additionally, because of the way we built our project, we leave a lot of room for expansion. First, we can expand into other sports leagues. Since we have the foundation of the bot, which pulls from a backend database, all we would have to do is propagate the database with different sports. We would need to build more specialized web scraping software, but we could potentially utilize the same overall structure to analyze other sports. This also allows for expanding into different social networks or a website, as they would just have to pull the same information from our database. A website would allow us to have more information in our summaries and predictions, as well as increased freedom in how the information is displayed.
Built With
- beautiful-soup
- flask
- nba-api
- numpy
- pandas
- python
- requests
- scikit-learn
- sklearn
- sqlite
- tweepy

Log in or sign up for Devpost to join the conversation.