-
-
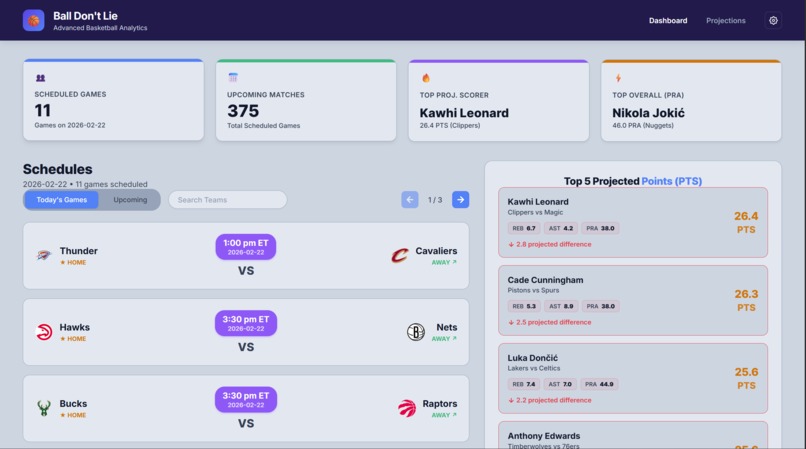
Dashboard for Ball Don't Lie
-
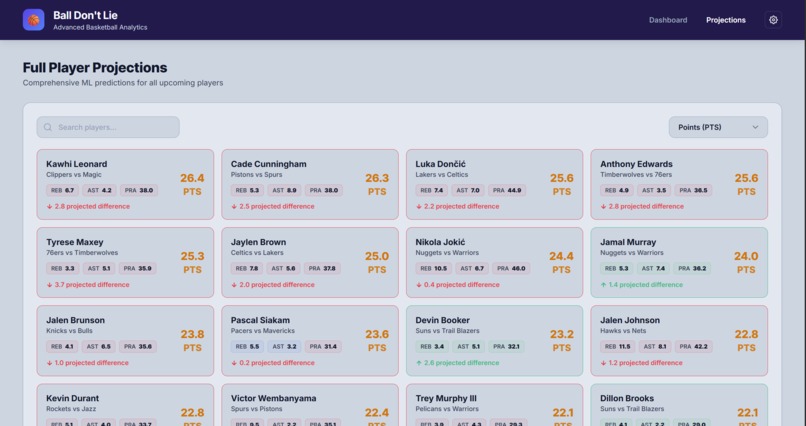
Full Player Projection Screen
-
Team Theme Options for Dashboard
-
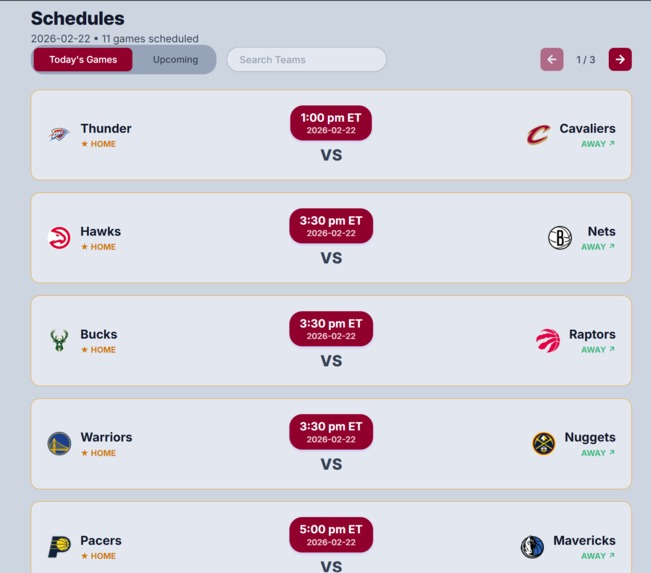
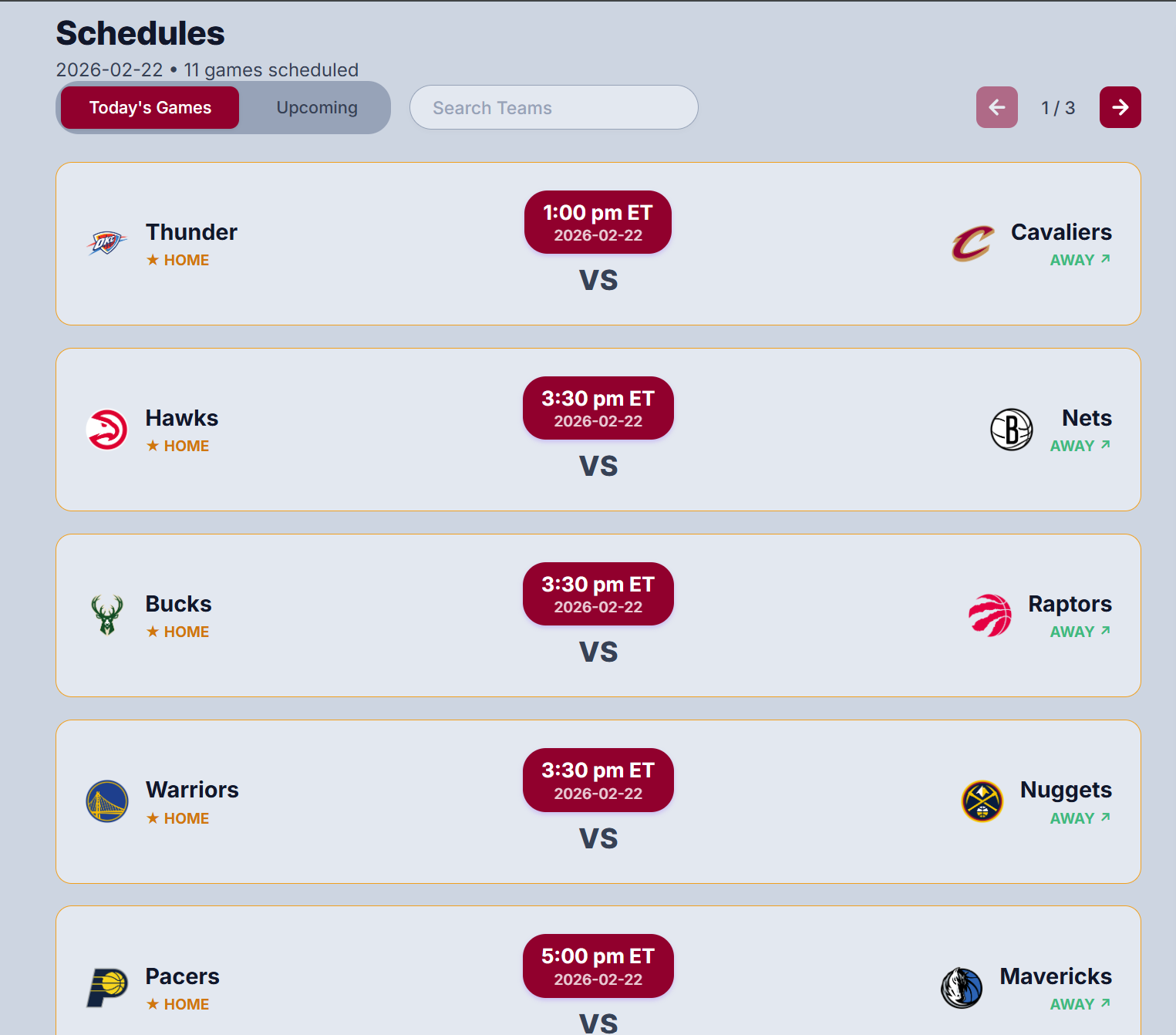
Today's Game Schedule Display
-
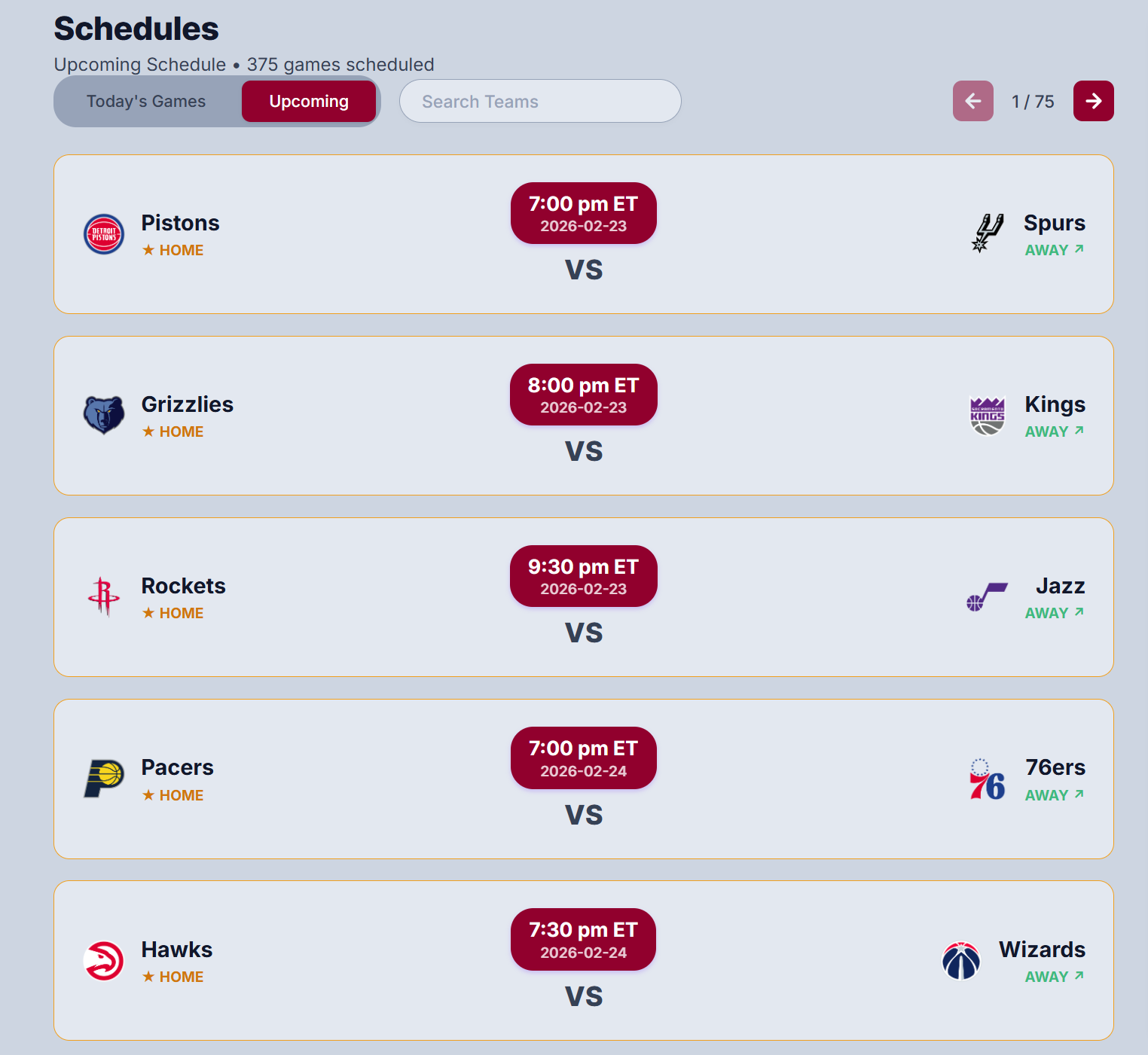
Upcoming Game Schedule Display
-
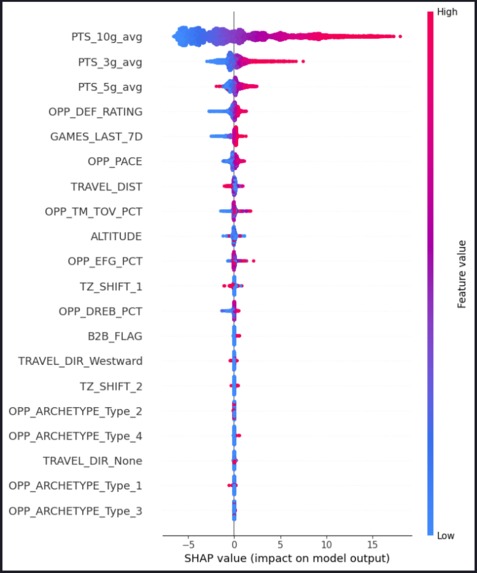
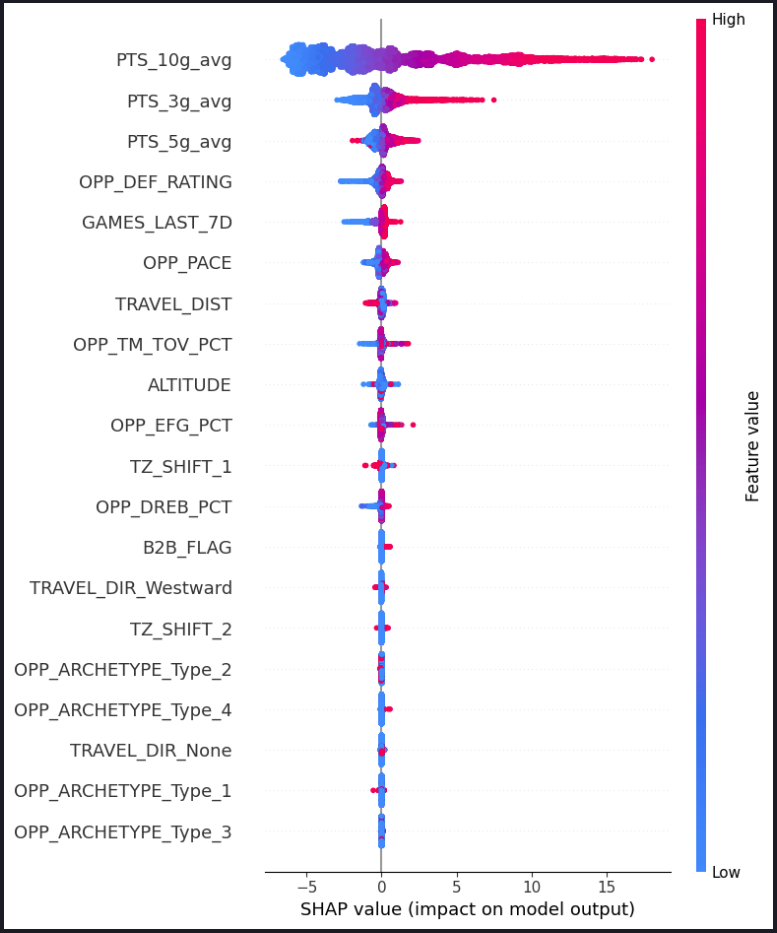
SHAP graph for PTS

Inspiration
Our group really enjoys to once a week throwdown a parlay on PrizePicks. However, we rely on 2 people in our group who really know ball to try and cook up something crazy based off their knowledge. So when we came here, we got thinking, what if we had a more statistical approach to picking our lines? We decided to pick some of the most common lines we take, and see if we could try and predict a players stat line by considering environmental factors that we believe are not likely traditionally considered by Sports Analysts, without relying on a hunch on how those factors actually matter.
What it does
Ball Don't Lie is a Machine Learning powered predictive engine to try and predict NBA Player stat line performance. Our engine attempts to aggregate and analyze traditional game by game data in conjunction with situational and environmental factors such as travel fatigue, time zone differences, back to back games, and opposing team defense archetypes.
How we built it
We first gathered our data set using the open source python library "nba_api" which acts as an api regarding nba stats by scraping the nba statistics website and aggregating all of the data. We use this to gather all the game logs and defensive metrics for every game from the last 4 NBA seasons. Then, we process this data to calculate averages from 10 games, 5 games, 3 games to capture the player statistics which we will train our model on. We also used the Haversine formula to calculate travel distance between player games, attempting to model what their flight travel might look like to see how far they are traveling and if they are traveling across timezones. Following that, we then used a K-Means Clustering algorithm to try and create a defensive profile to categorize the teams. As we believed there may be correlation of a player having poor performances against certain defensive playstyles (aggressive turnover, slow defensive rebound plays). These clusters were based off of Pace, Defensive Rating, Effective Field Goal %, Turnover %, and Defensive Rebounding %. Finally, we pass these features we have defined into an XGBoost Regressor to predict our stat lines for a player. We would then compare our models MSE/MAE metrics compared to a naive model that only uses the past 5 games rolling average to try and evaluate our comparative edge and model performance.
Challenges we ran into
One of the biggest challenges we faced was getting the data from the api. Given the need for an incredibly large sample to try and first train our model, we constantly ran into rate limiting and time out issues when attempting to pull the data. It also did not help that we did not realize until very far in that we realistically only need to pull in the data once a day, as the players history is not changing during the day and we are just causing ourselves issues trying to pull data to find the averages rather than just recording it all initially and using that, avoiding all the issues requesting the data.
Accomplishments that we're proud of
Our biggest accomplishment would likely be getting the K-Means clustering algorithm to feed into a statline for our model. It was very exciting to get to try an utilize multiple data science algorithms to create a more comprehensive picture. Going into the project we thought this would prove to be a competitive edge as it's something that is likely not considered statistically when picking the lines, but rather something commentators may just talk about. It turned out it had almost zero effect on our model, but it was fun to implement and see.
What we learned
There definitely needs to be more of a statistical undertaking in trying to determine what significantly impacts a players performance. None of our team has much of a statistical or data science background at all for this type of research, and it would have been useful. We added the K-Means clustering and it had virtually zero impact on the prediction for the majority of the matchups. Most importantly what we learned, is gambling is really not able to be bet probabilistically. We wasted $10 trying to bet using our models predictions, and as it turns out, there is nothing you can do if a player just ends up having a great game, as Wemby went above our predicted line 22.2 to a whopping 28. However our line was pretty close to a line that a casino would set, typically being only a point or two away from PrizePicks standard over-under line.
What's next for Ball Don't Lie
See if we can try other possible factors that impact the game. We were thinking to implement other factors such as rivalry games, or players that may have transferred from one team and playing their old team. Additionally, we want to predict additional lines such as steals, blocks, dunks, etc, but we did not have time for that during our application.

Log in or sign up for Devpost to join the conversation.