-
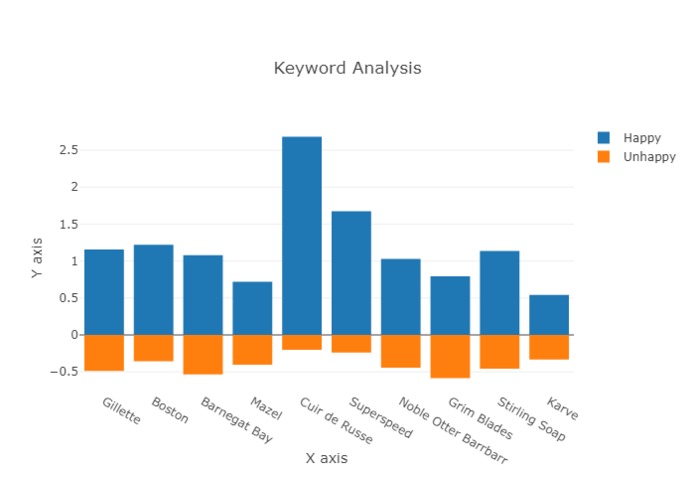
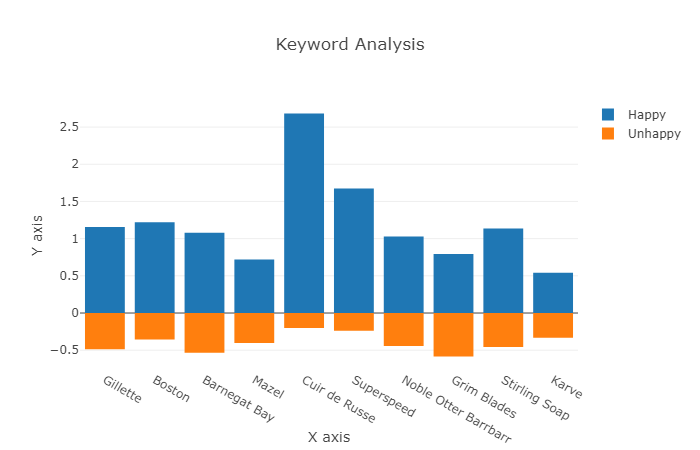
An example output from /r/Wicked_Edge, a shaving enthusiast subreddit, each keyword is a different product
Inspiration
We wanted to find an application for the Watson ML APIs that was both relatively novel and relatively adaptable. We initially tried to use a series of APIs in order to assess relations between keywords, entities, and sentiments to determine bias in news media, but quickly determined that due to the length and diversity of news articles, as well as a lack of a way to sort articles based on 'quality,' it was infeasible. However, we did determine that it would be much more feasible and applicable to assess social media comments, which already have easily accessible metrics for perceived quality, (upvotes/likes/retweets), short strings, which would allow for a much better way to both produce a working model of sentimental analysis and make useful sense of the data that we produced.
We ended up choosing to select posts from reddit, and analyze what keywords and entities they encompassed, incorporating upvote data, top comments, and body text. In doing so, we created a system that produced data on trending topics in a selective basis, picking from one or a combination of subreddits, which allows for granular topic control, providing sets of similar data points (posts), that also had scope for application on other text-heavy social media websites.
What it does
Baker Street Analytica is a prototype framework for in-depth analysis of subreddit trends and opinions. We created a GUI for selecting data sets [subreddit(s), number of posts collected, number of comments assessed], we produced a user-friendly graphical output that can be easily interpreted to understand the collective consciousness of a subforum. This framework, while currently plugged into the PRAW (Python Reddit API Wrapper) tool for Reddit, can easily be reworked to take input from Twitter and/or other forum style websites.
How we built it
We started by tinkering with Watson's Natural Language Understanding API, to try and figure out how it interpreted text and divided it into keywords and entities. From there on, we decided on a website to gather our data from, and ended up picking reddit due to its numerous and specific sub-forums, which closely group similar posts and its python API, which allowed us to use one powerful language that became modular due to its ease of understanding and use. From there on, we decided to first output the data we gathered as text, separating keywords/entities, and how positively, and negatively they were perceived. While we gained adequate results, which we kept in as a debugging tool, we still believed that there was a better way to represent them. As such, we went on to first develop a graphical tool to produce a graph of the intensity of the negative and positive sentiments of each keyword and entity. From there, we then decided to improve the user-friendlyness of our script and produce a 'webpage' that allowed for easy input of subreddits, number of posts to be assessed, number of comments, and number of keywords/entities to be chosen.
Challenges we ran into
After we completed the initial task of implementing a barebones NLU keywords algorithm, we decided to attempt graphical representations of the data. We had some trouble finding a good graph type to represent both positive and negative feedback without convoluting the data. We eventually settled on a bar graph that extended both into the negative as well as the positive end. Then, we struggled to embed the graph into the front-end interface that we were developing. We started by using a Dash implementation, which run a new server and opened a new page for each new graph. We eventually had to switch to a Plot.ly implementation, which involved rewriting our entire graph implementation to embed our graph to the same page as our form.
What's next for Baker Street Analytica
Sometimes it becomes quite hard to interpret the data outputs, particularly when they return non-sequitur keywords and entities. Certainly, improvements to the accuracy and contextualization of results would vastly increase the utility of this application.
Built With
- bottlepy
- html
- ibm-watson
- plotly
- praw
- python





Log in or sign up for Devpost to join the conversation.