-
-

Our writeup!
-
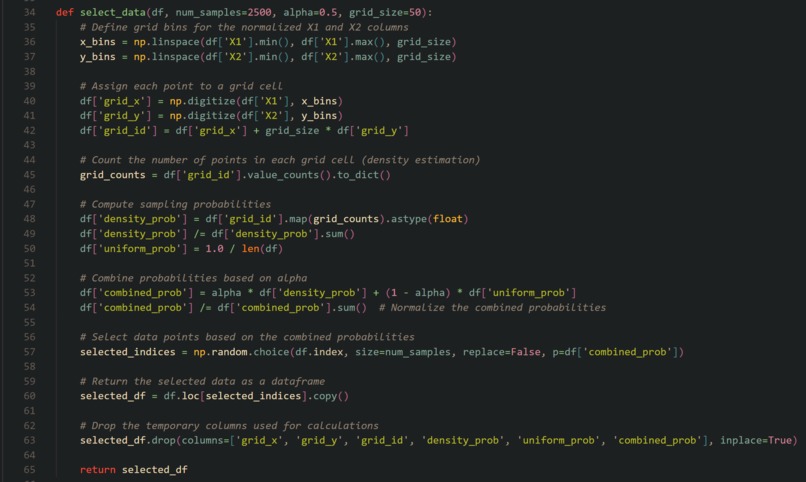
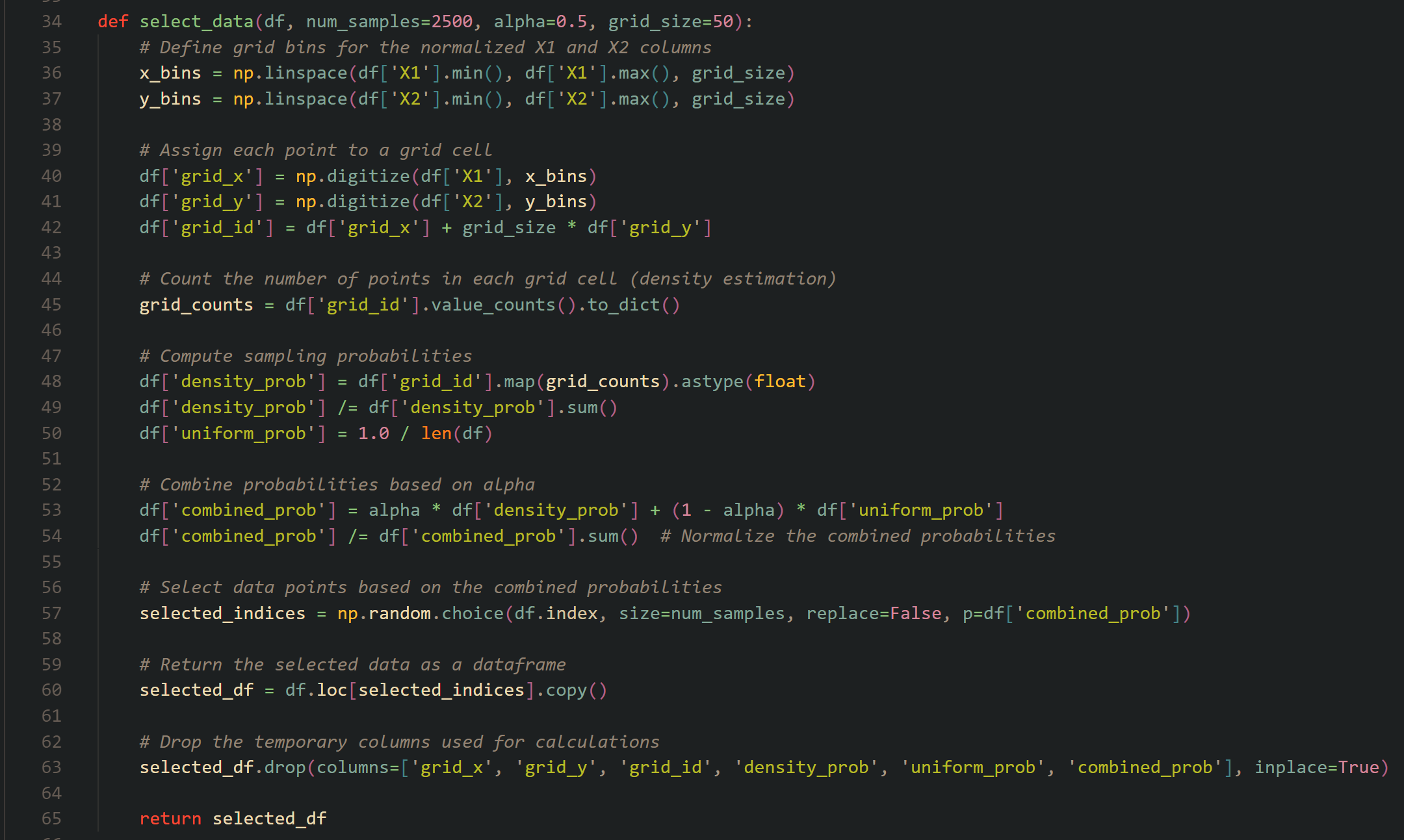
Algorithm code
-
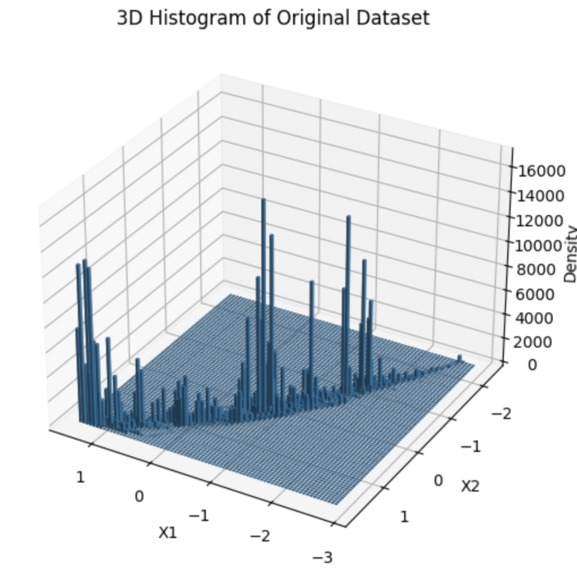
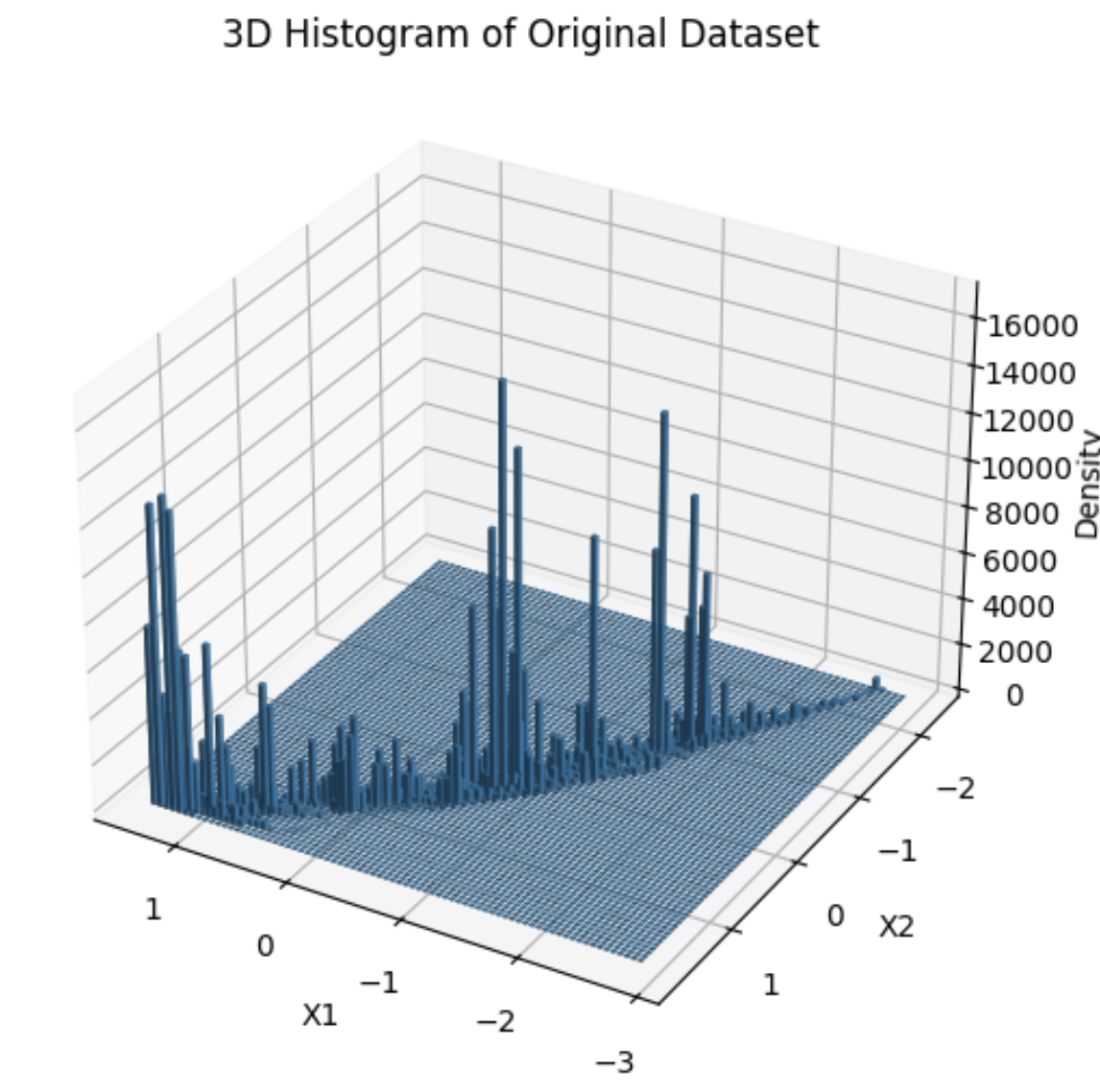
Histogram of Original Dataset
-
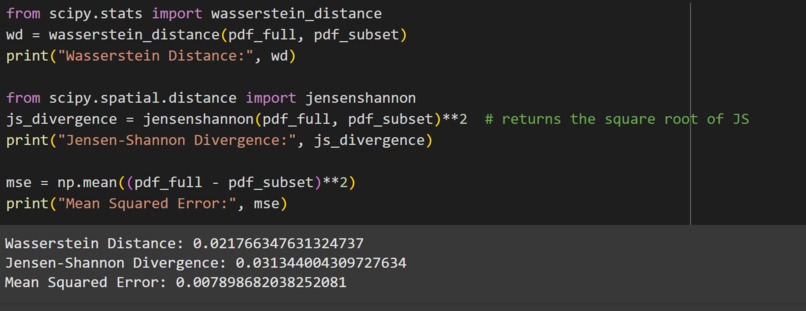
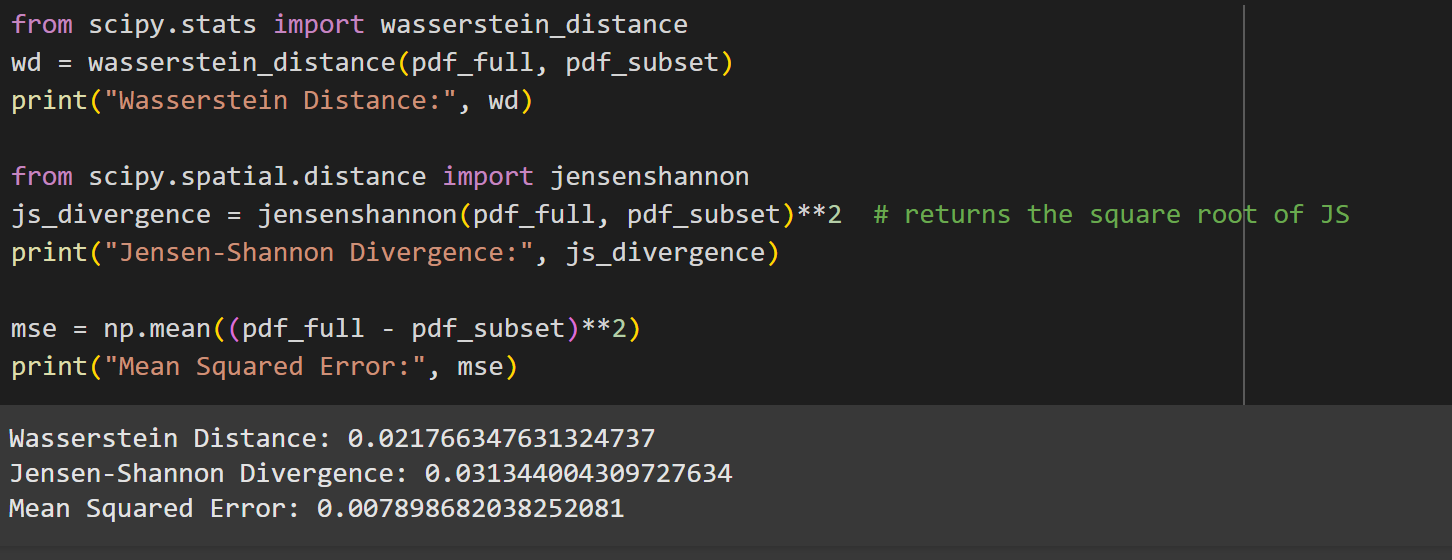
Evaluation Metrics on X1
-
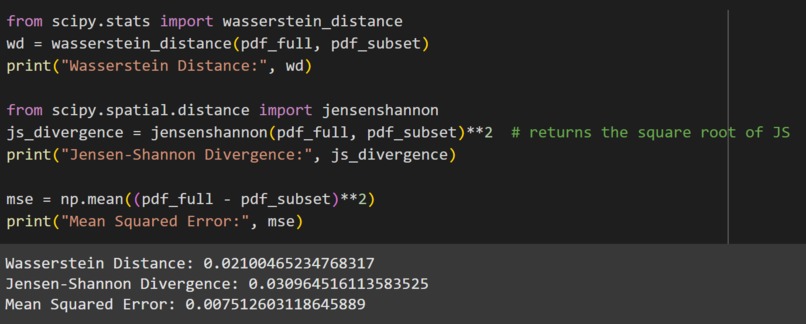
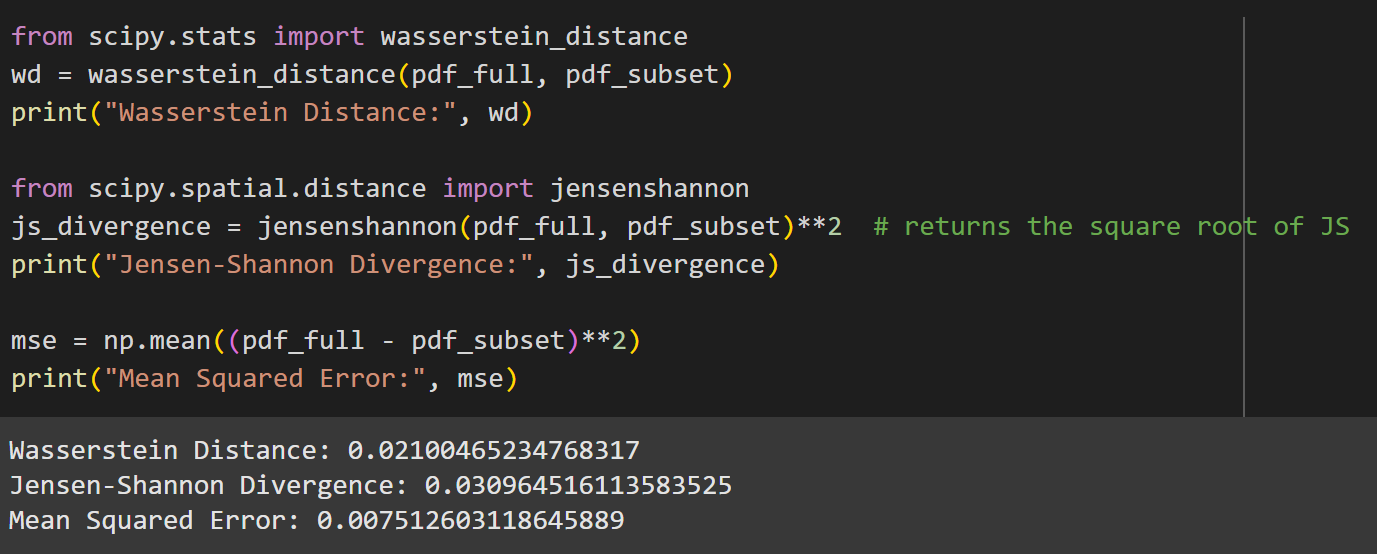
Evaluation Metrics on X2

Inspiration
The challenge of efficiently monitoring the health of electric motors, while minimizing computational resources, inspired us to develop a smart data-selection approach. The goal is to improve predictive maintenance systems, enabling industries to track motor health and prevent downtime in a cost-effective manner. By optimizing the data used for machine learning, we aim to make these systems more practical, even in resource-constrained environments.
What it does
Our solution is a condition-monitoring algorithm that predicts electric motor vibration levels based on frequency (X1) and power (X2) measurements. By training a machine learning model with a carefully selected subset of the data, the system predicts vibration levels and detects early signs of motor health degradation. The predictions are compared with actual data, allowing operators to identify maintenance needs before a failure occurs.
How we built it
We designed a data-selection algorithm that efficiently reduces 500,000 data points to just 2,500, ensuring we maintain the balance between data coverage and density. The first step was normalizing the frequency and power data to make them comparable. Then, we developed a grid-based sampling algorithm that divides the input space into cells. Each cell's density is calculated by counting how many data points fall into it. Data points are then selected based on both uniform and density-based sampling, with a tuning parameter (α) that adjusts the balance between the two approaches. This reduces training time and computational resources while maintaining high prediction accuracy.
Challenges we ran into
The main challenge was selecting a representative subset of data from a much larger dataset. We had to balance uniform sampling across the input space with focusing more heavily on high-density regions, where the motor operates most frequently. Another challenge was ensuring that the selected data didn’t introduce bias and effectively represented all operating conditions of the motor.
Accomplishments that we're proud of
We're proud of successfully creating an algorithm that can efficiently select a small but representative dataset for training. This approach reduces the time and resources needed to train the model without sacrificing prediction accuracy. It enables the use of machine learning in resource-limited settings, making condition monitoring more accessible.
What we learned
We learned how to effectively balance data diversity and computational efficiency in machine learning training. This project deepened our understanding of predictive maintenance and how selective data sampling can improve the performance and adaptability of such systems. We also learned how to apply normalization and grid-based sampling to handle large datasets efficiently.
What's next for Baker Hughes Challenge
Next, we plan to refine the data-selection algorithm to further improve accuracy and speed. We’ll test it on a wider variety of assets and explore adaptive algorithms that dynamically adjust based on real-time data. This will enhance the model’s ability to adapt to changing operational conditions over time, providing a more flexible and long-term solution for predictive maintenance.

Log in or sign up for Devpost to join the conversation.