Inspiration
A factory coordinator goes on sick leave. Two days later, production is half-speed — not because machines broke, but because nobody else knew what to run next. All the scheduling logic was in one person's head.
The frustrating part: every shift had been logged. Every mold-machine combination, every actual cycle time, every order — sitting in spreadsheets, never used for anything beyond compliance. The knowledge was there. It just wasn't being extracted.
That's where Bailout came from.
What it does
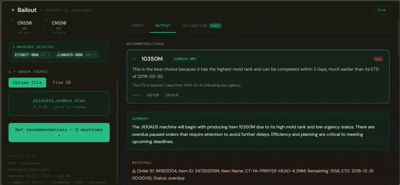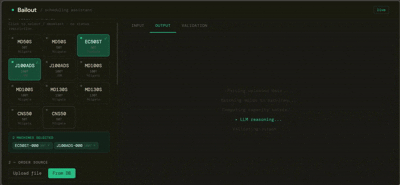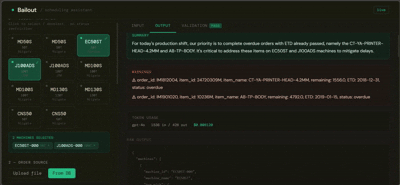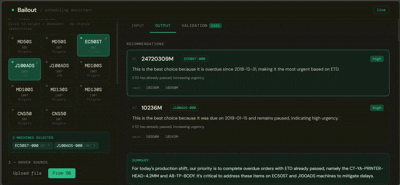
Bailout tells you which job to run next on an idle machine, based on your factory's actual production history.
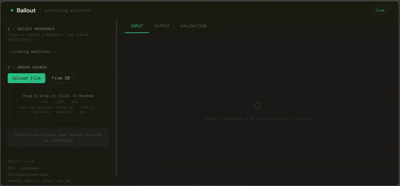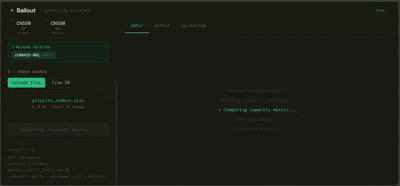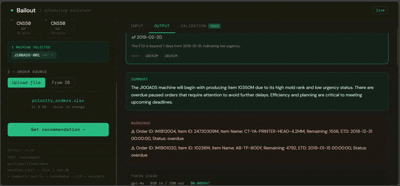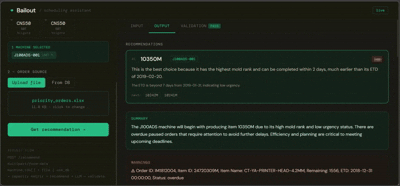
You select the machines about to go idle, provide a list of pending orders (or let it pull from the database), and Bailout returns a ranked recommendation per machine — with a plain-language explanation of why, written for someone who doesn't read data tables.
How we built it
Two layers, deliberately kept separate.
Layer A is entirely deterministic — a recommendation engine built in Python/pandas. It blends spec-based default capacity with historical run data using a time-decay weighted model, builds a priority ranking of machines per mold, and assigns orders across machines without duplicates.
Layer B is the interface layer — a FastAPI orchestrator that handles order resolution (uploaded file, database fallback, or both), calls Layer A, then passes the structured result to an LLM that translates it into plain language. The LLM receives a fully computed output and explains it. It makes no scheduling decisions.
A validation layer checks every LLM response against Layer A's ground truth before it reaches the user — catching hallucinated machine assignments, wrong urgency labels, or missing warnings before they cause problems.
Challenges we ran into
Rank ties. When a mold has no run history, all compatible machines fall back to the same default capacity — same score, same rank. Pandas .rank(method="average") returns floats like 1.5, which confused the LLM. Switching to method="min" gave clean integer ranks and made the tie semantically clear: these machines are genuinely equivalent.
Keeping the LLM in its lane. Early prompt versions had the LLM occasionally reranking candidates or suggesting alternatives not in the input. Explicit constraints — "DO NOT recalculate, DO NOT change the order or machine assignments" — combined with a validation layer fixed it.
Fallback state across multiple machines. "Fall back to DB if no file match" sounds simple until Machine A matches from the file, Machine B falls back to DB, and Machine C has no match at all. Each path needed separate tracking and distinct user-facing notices.
Accomplishments that we're proud of
The validation layer is holding up. Across multiple test runs with fully structured prompts, hallucination rates on factual fields (machine assignments, item IDs, urgency labels) dropped to near zero. The LLM occasionally softened language, but the structural outputs were reliable, which was the hypothesis we wanted to test.
Also: the fallback chain. A system that gracefully degrades from "use your uploaded orders" → "fall back to DB" → "tell you clearly when nothing matches" felt more useful than one that just errors out.
What we learned
When the hard decisions are already made—ranked, validated, and structured —an LLM becomes a genuinely reliable interface. The failure mode isn't hallucination of facts; it's hallucination of decisions. Remove the decisions from the LLM's scope, and reliability increases dramatically.
The broader lesson: in high-stakes domains, LLMs work best as translators, not reasoners. Build the logic deterministically. Let the LLM make it readable.
What's next for Bailout
With more time, this system can become a higher-level planner for all machines. It can consider more constraints and give multiple scenarios for better decisions. We also want to improve LLM to reduce hallucination and give more reliable explanations from data.

Log in or sign up for Devpost to join the conversation.