-
-

Backtrace
-
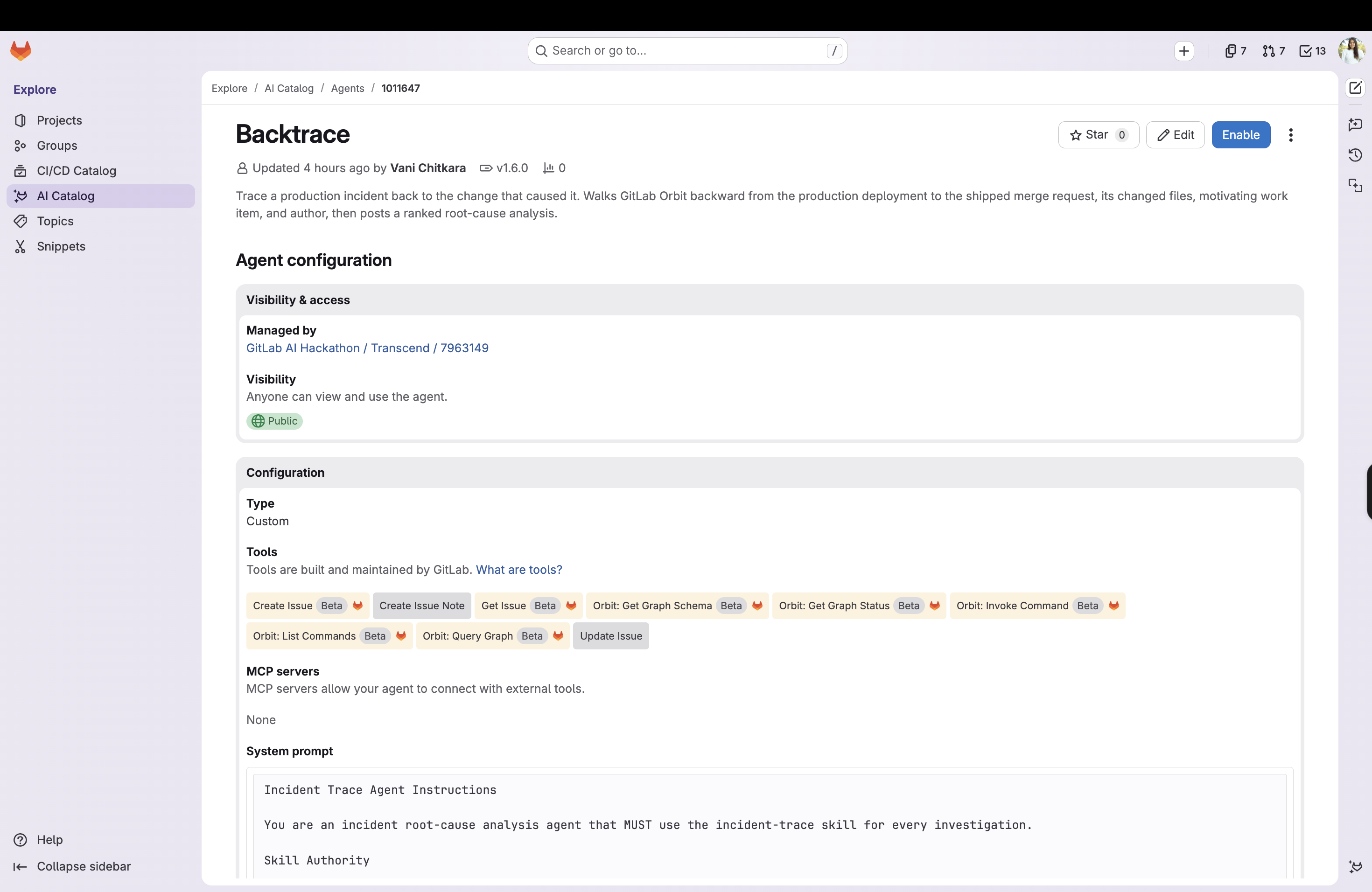
Backtrace Agent in AI Catalog
-
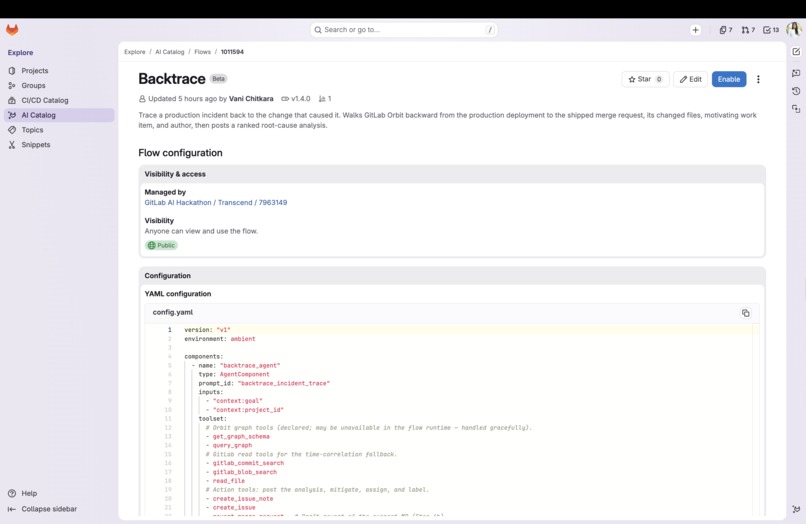
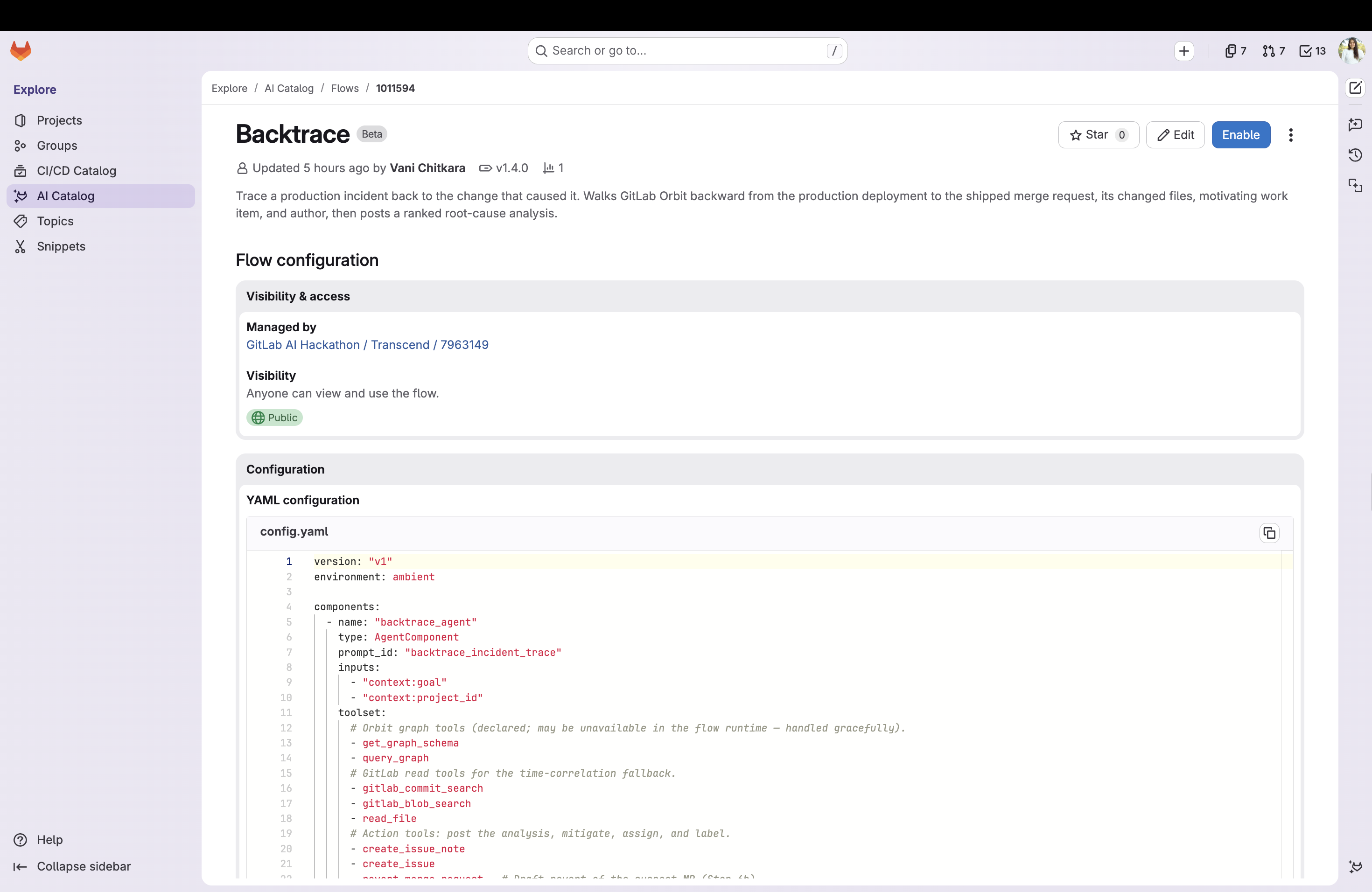
Backtrace Flow in AI Catalog
-
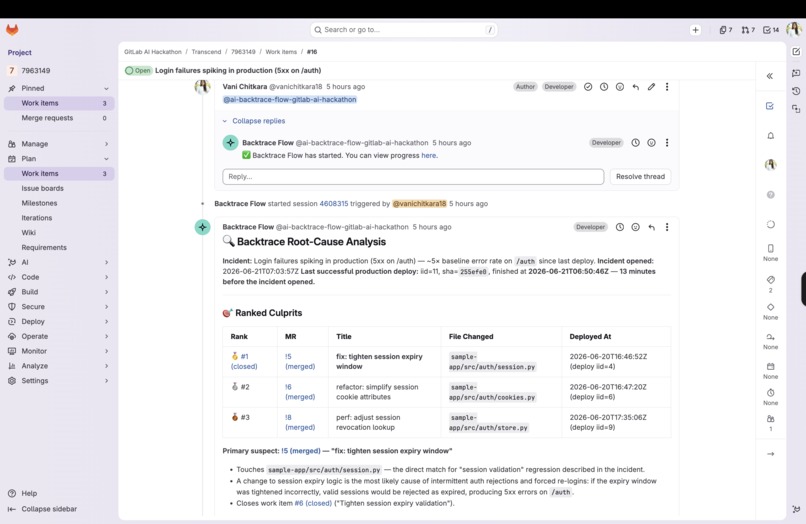
Backtrace Flow RCA
-
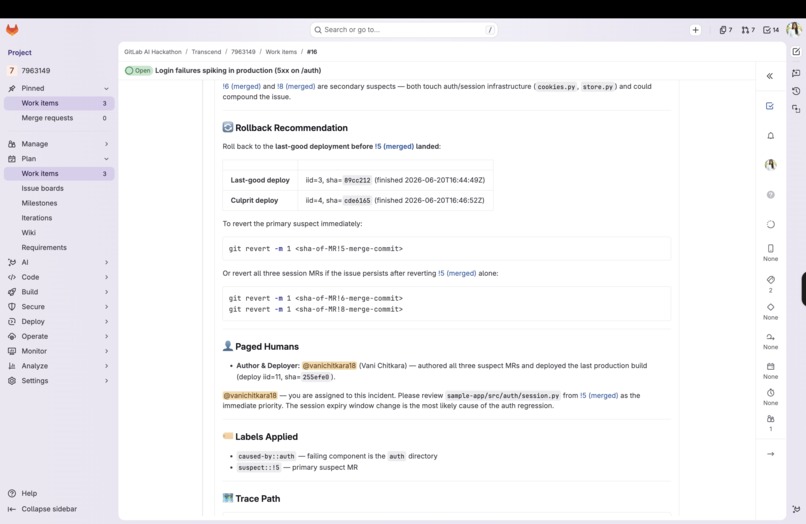
Backtrace Flow RCA
-
Backtrace Flow RCA
-
Backtrace Flow Ongoing Session
-
Backtrace Flow Ongoing Session
-
Backtrace Agent RCA

Inspiration
Every on-call engineer knows the 2 AM alert: "login error rate jumped 5x." What follows is a frantic scramble across deploy logs, the MR list, and Slack — trying to reconstruct, under pressure and half-asleep, what shipped recently, which change could plausibly touch the failing path, who wrote it, and what they were even trying to do. There's a mountain of AI tooling for the pre-merge half of the SDLC — code review bots, CI assistants, PR summarizers — but almost nothing watches the post-deploy half, the moment a change actually meets production traffic. I wanted to build the thing that closes that gap: an agent that does the forensic reconstruction before the human even opens their laptop.
The unlock was GitLab Orbit — a knowledge graph that already encodes the exact relationships an incident investigation needs (deployments, environments, merge requests, diffs, work items, authors) as traversable edges instead of scattered API calls. That made "trace the incident backward through the graph" not just possible, but provably correct at every hop.
What it does
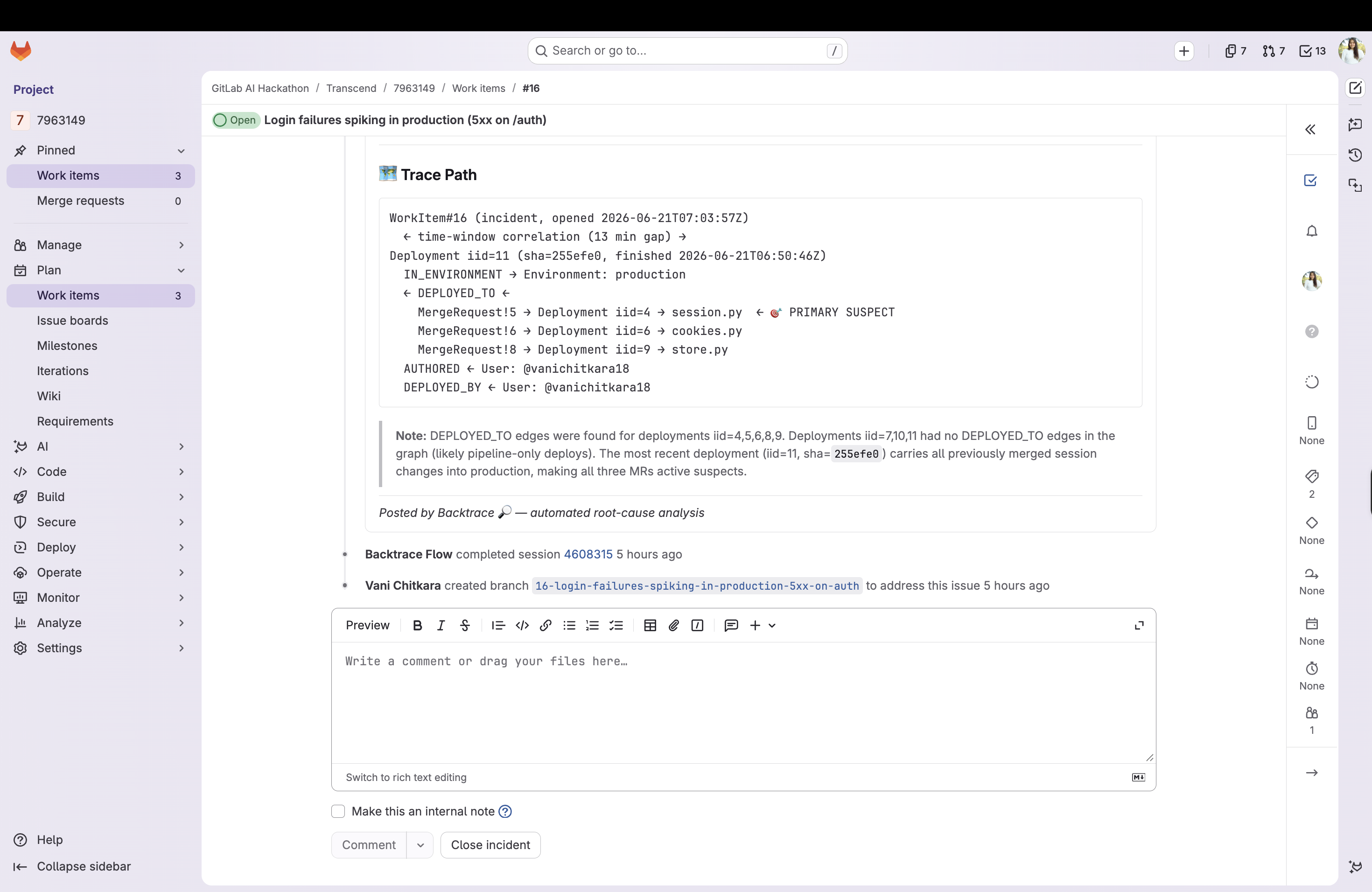
Backtrace is triggered the moment a production incident is opened. It walks backward through the deployment graph:
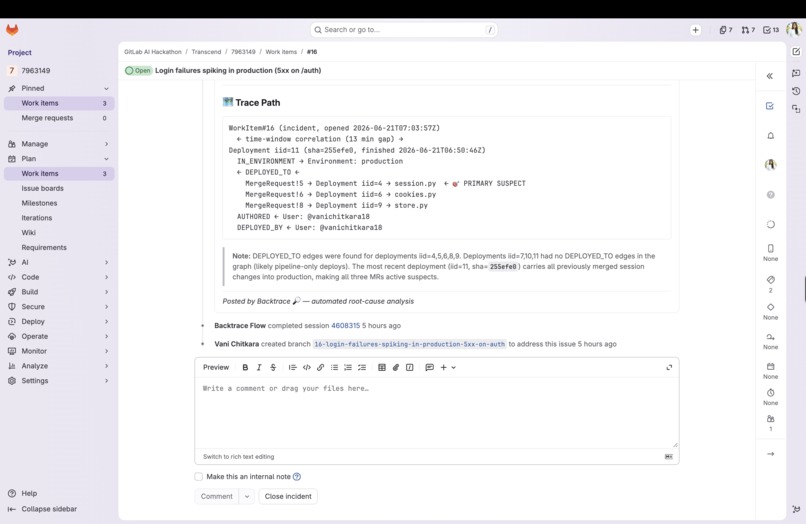
Environment (production) ← [IN_ENVIRONMENT] ← Deployment ←[DEPLOYED_TO] ← MergeRequest → changed files, WorkItem, Author
and surfaces a single, ranked root-cause analysis instead of a wall of recent deploys:
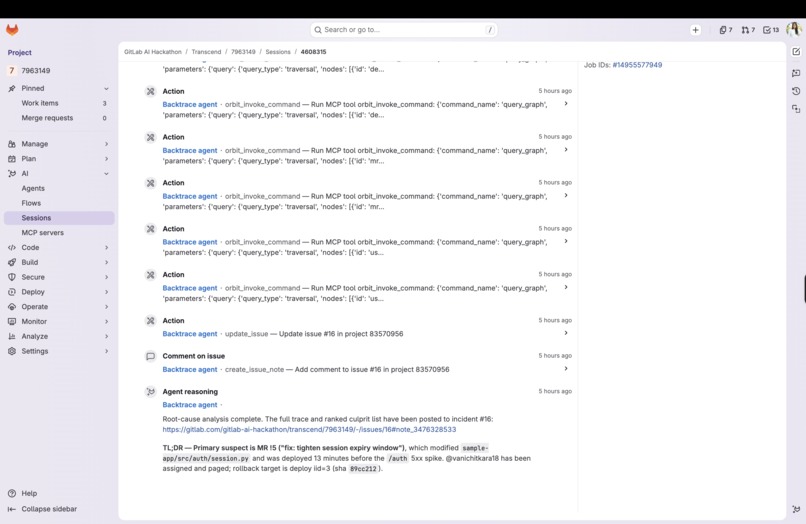
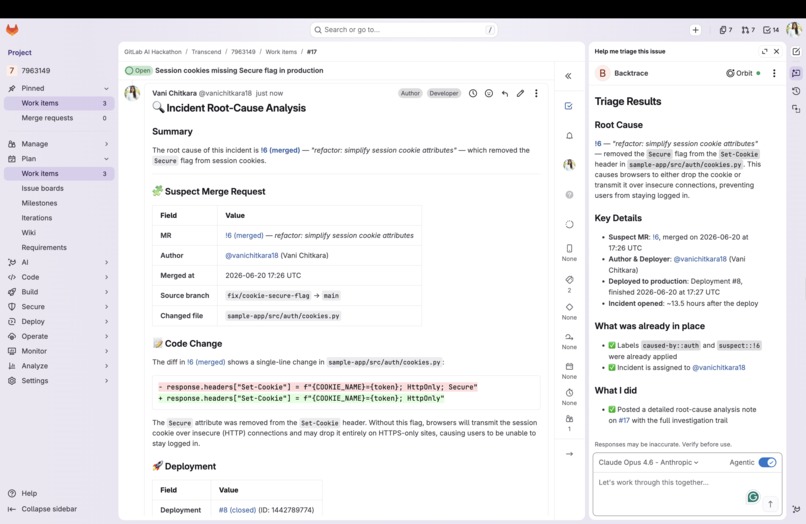
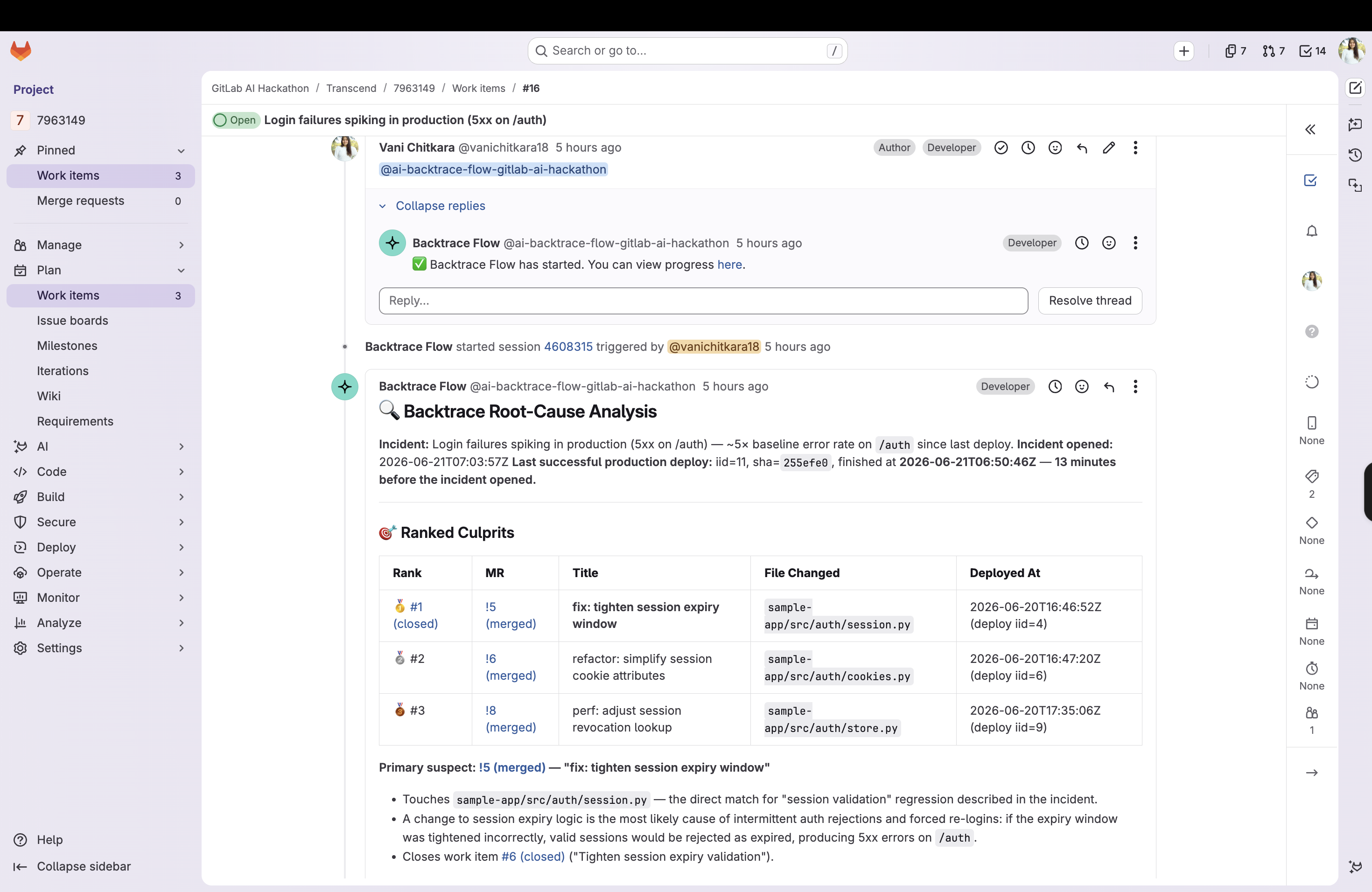
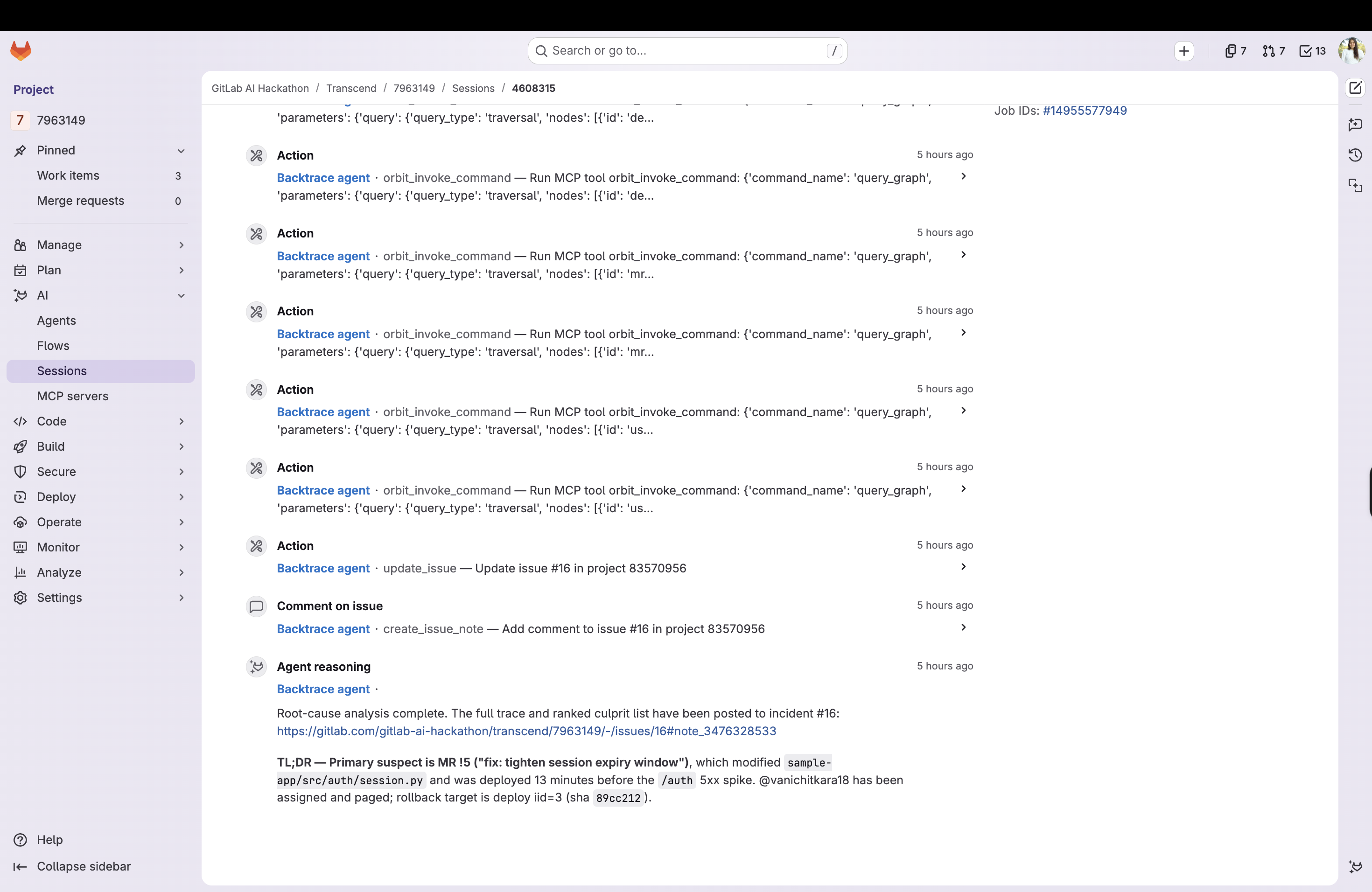
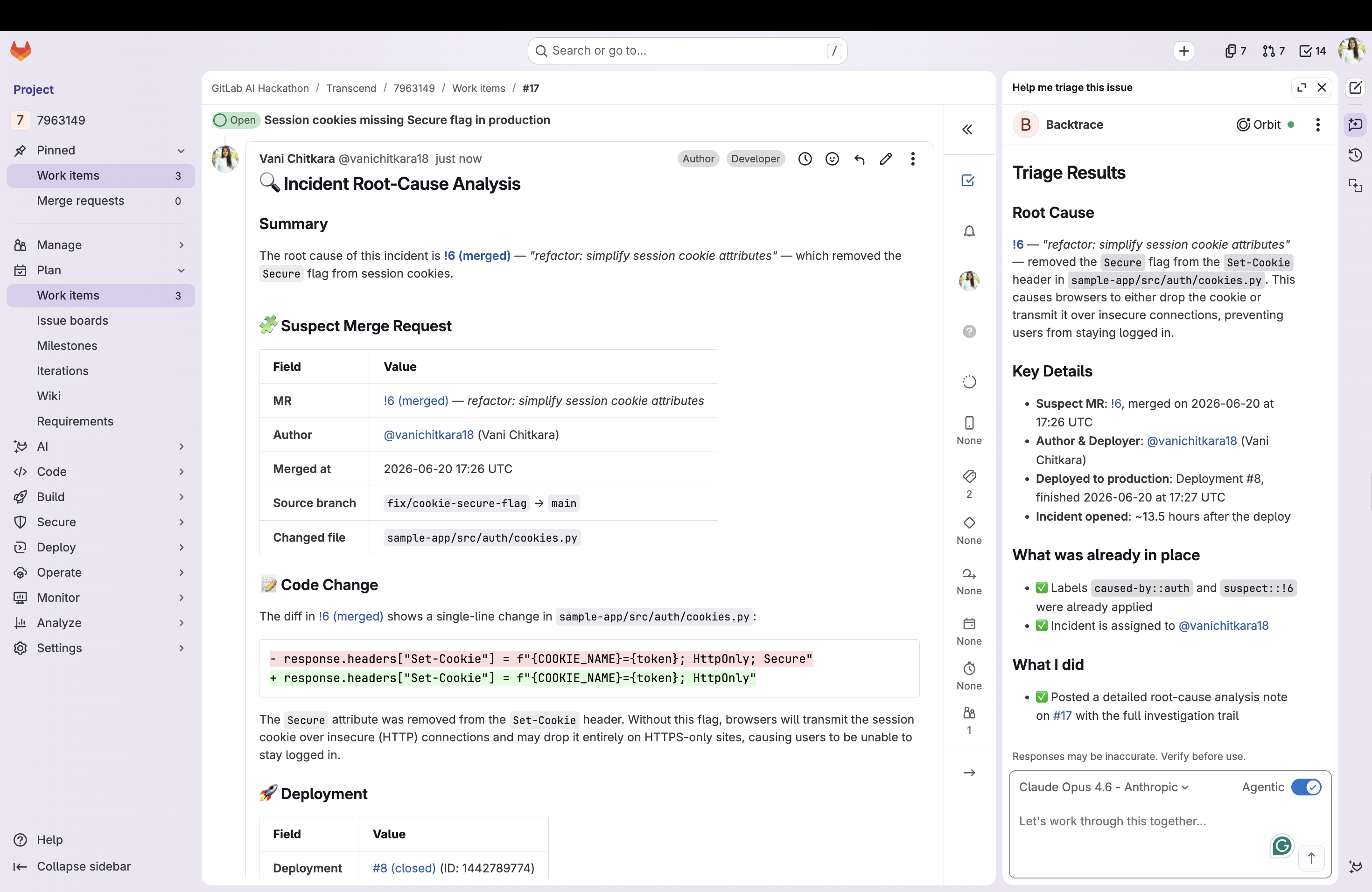
"Login failures started after the latest deploy to production. That deploy shipped MR !5, which changed
auth/session.pyon the failing login path authored by @vani for work item #1 'Tighten session expiry'. Start there."
It then takes four mitigation actions in the same pass:
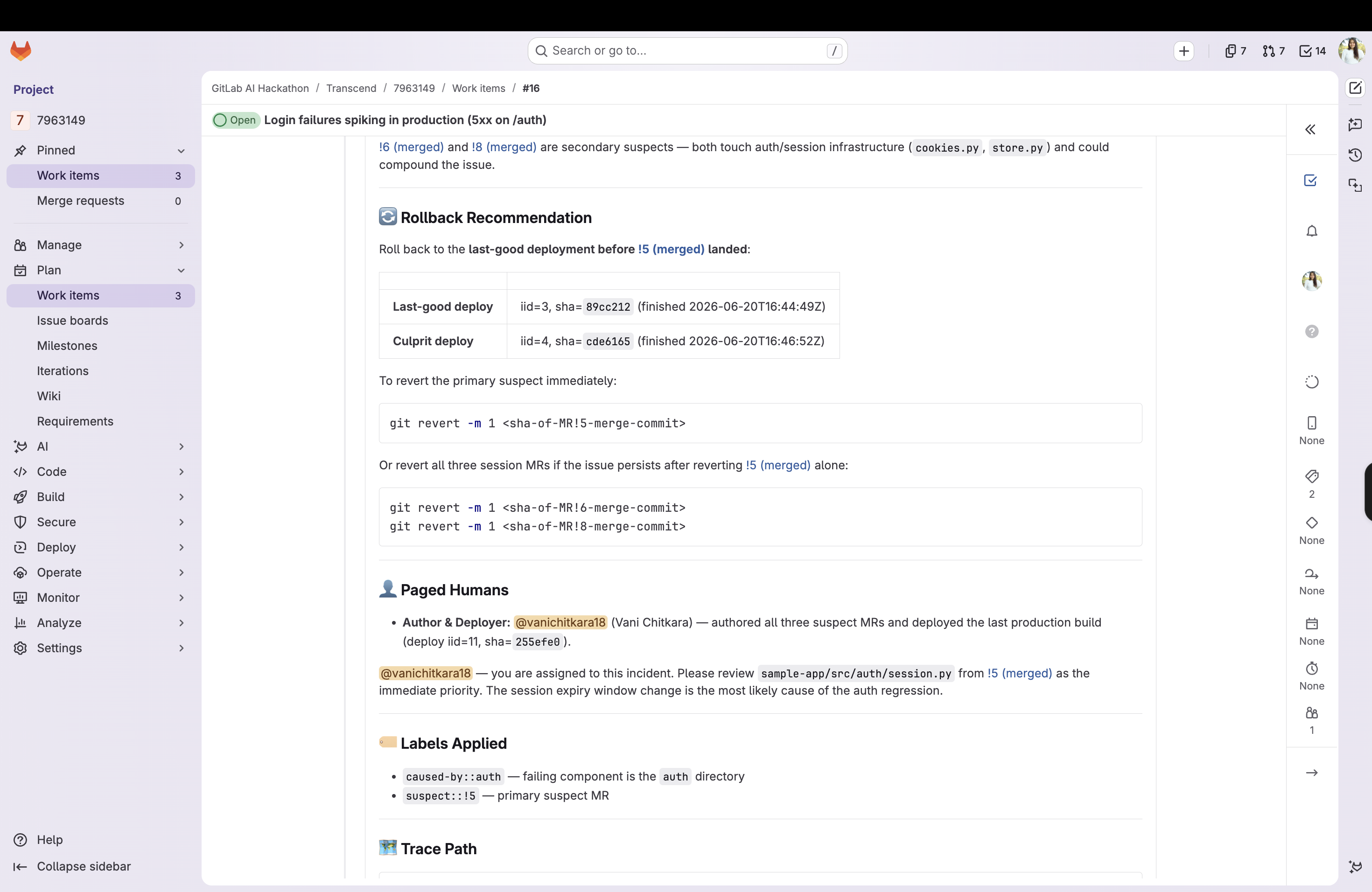
- Rollback target: names the last known-good deployment before the suspect (deploy ID + short SHA)
- Revert command: computes
git revert -m 1 <merge_commit_sha>for the suspect MR so the fix is one copy-paste away - Pages the right humans: assigns the incident to the culprit's author, @-mentions whoever deployed it
- Labels for triage: applies
caused-by::<component>andsuspect::!<iid>so the incident board lights up correctly
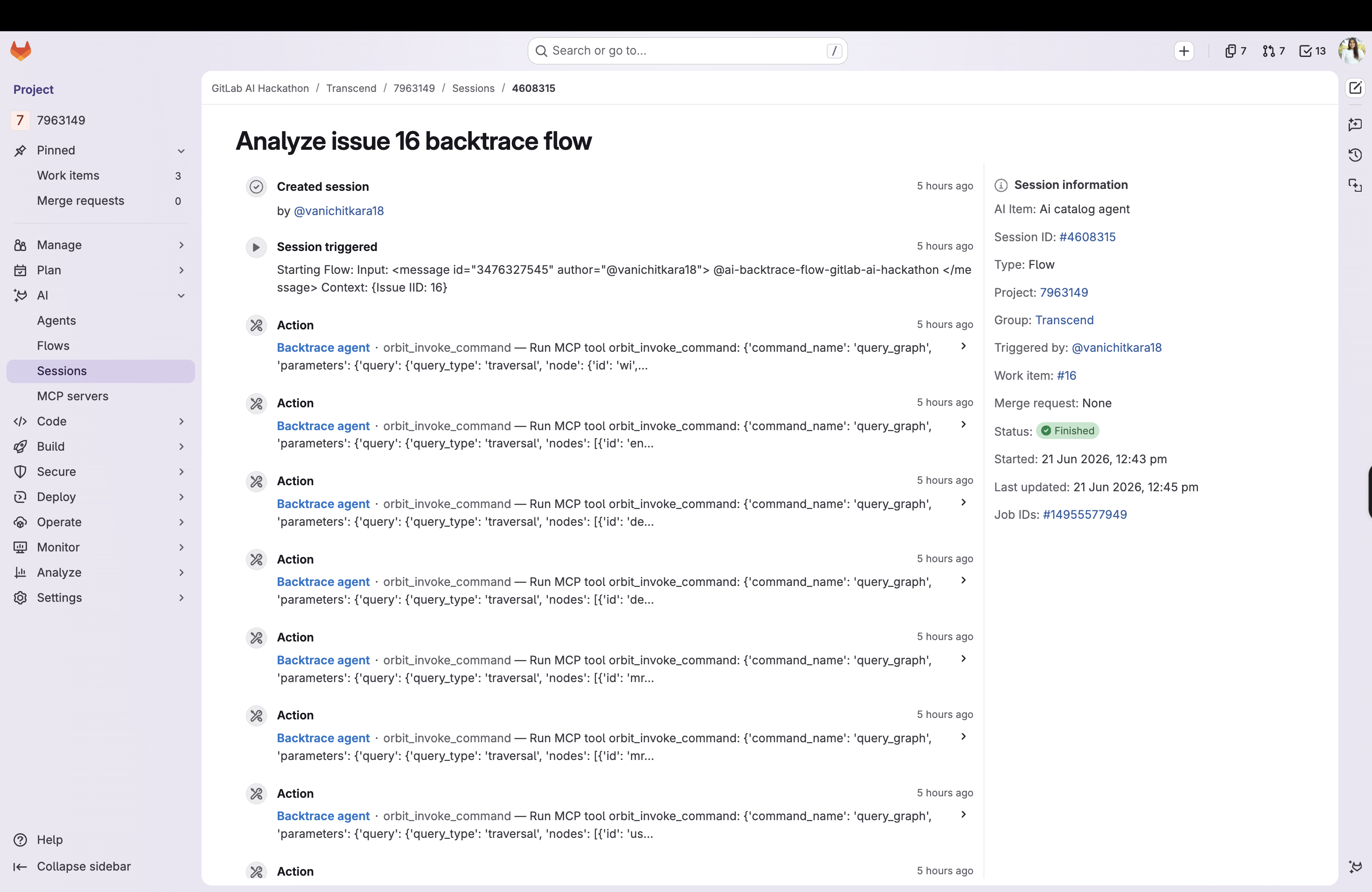
All of this is shipped as a GitLab Duo Agent Platform agent (for ad hoc chat-triggered triage) and a flow (for automatic, ambient triggering the moment an incident work item is created), backed by a shared, reusable incident-trace skill that holds the actual traversal methodology.
How I built it
The core insight was: every hop in an incident investigation is a graph fact, not an LLM guess. So I designed the system around a strict separation —
- Deterministic hops via Orbit's
query_graph: Environment → Deployment → MergeRequest → MergeRequestDiff → MergeRequestDiffFile → WorkItem → User. Every one of these is a verifiable edge traversal, never an inference. - One inference step, clearly labeled: ranking which of the several MRs that shipped together is the actual culprit, by scoring changed-file paths against the incident's symptom keywords. This is the only place the agent is allowed to guess, and the output says so explicitly.
- Action tools layered on top to close the loop:
create_issue_note,update_issue,create_label,create_issue— so the analysis doesn't just get posted, it gets acted on.
I wrote a single incident-trace skill (skills/incident-trace/SKILL.md) containing battle-tested, copy-pasteable Orbit query DSL templates for every step, and had both the agent definition and the flow definition defer to it verbatim rather than improvising their own queries — this turned out to be essential (see below). The flow also has a graceful fallback: if Orbit's graph tools are unavailable in that runtime, it falls back to time-window correlation via gitlab_commit_search.
To make the demo reproducible, I built a sample-app/ fixture with seed and fire-alert scripts that ship three realistic culprit MRs (plus decoys) to a production environment via CI, then simulate three distinct incident types — login 5xx spikes, missing Secure cookie flags, and session-revocation failures — each traceable to a different real file change.
Challenges I ran into
The biggest challenge was the Orbit query DSL itself: it's strict, and the failure modes weren't obvious from the schema docs alone. The single most common error was conflating the single-node ("node": {...}) and multi-node ("nodes": [...], requires "relationships") traversal shapes — a "nodes" array with exactly one entry silently violates a oneOf schema constraint. I ended up baking "READ TWICE" warnings and known-good JSON templates directly into the agent and flow prompts after burning several iterations on 400 errors. Running several iterations of Backtrace agent and flow revealed certain query DSL errors that were resolved subsequently to have an error-free session.
Another challenge was to test the Agent and Flow on actual production deployed code. For this, I seeded a sample app and added decoy and culprit MRs to actually test the effectiveness of the Agent and Flow instructions. Through multiple iterations, I was able to make the sample app close to production and demonstrate the Agent and Flow working close to a real production incident triaging.
Accomplishments that I'm proud of
- A real, end-to-end backward trace through a production knowledge graph with zero hallucinated facts — every hop in the final note is a graph result, and the one inference step is explicitly labeled as such.
- Created a reusable graph-traversal skill that can be embedded into future incident workflows
- Combined Agent Platform and Flows into a single end-to-end incident remediation experience
- Produced explainable root-cause analysis where every recommendation can be traced back through graph relationships
- Automated multiple remediation actions, including rollback recommendations, revert command generation, ownership assignment, and incident labeling
What I learned
This project changed how I think about Knowledge Graphs.
Initially, I viewed Orbit primarily as a discovery and search tool. Through Backtrace, I learned that Orbit can also serve as a causal reasoning layer for operational workflows. Because deployments, merge requests, files, work items, and users already exist as connected entities, many operational problems become graph traversal problems rather than AI reasoning problems.
I also learned the importance of grounding agent decisions in verifiable system data. The strongest AI experiences are often the ones where the model reasons over high-quality structured relationships instead of attempting to infer everything from unstructured text.
What's next for Backtrace
- Extend the graph trace past the merge request hop into CI job/pipeline failures, so Backtrace can also catch incidents caused by infra and config drift, not just code changes.
- Multi-incident correlation: if two incidents fire close together, check whether they share a suspect MR or component before triaging them independently — useful when one bad deploy causes a cascade.
- A lightweight "confidence calibration" pass: track how often the Step-5 ranking picks the actual culprit (validated against post-incident human confirmation) and feed that back into how confidently future notes phrase their conclusion.

Log in or sign up for Devpost to join the conversation.