Inspiration
The inspiration for this project started with my exposure to The Internet Archive. I wanted a platform that would facilitate preserving Arabic literature in a useful digital format. This would provide a multitude of benefits including simplifying research that relies on Arabic text, and enriching the delivery medium for visually impaired readers. When I first thought about this project, I started a Google group to get a small team working on it, but there were no reliable Arabic OCR engines at the time. More recently, I came across a paper that discusses recent developments in Arabic OCR, that showed very promising performance from an OCR engine called Kraken, that relies on Recurrent Neural Nets (RNNs). Later, when VandyHacks IV was announced, I thought this would be a great opportunity to try and start working on this project using the Kraken engine.
What it does
Babl hosts books in the form of separate scanned pages and their corresponding OCR text. When a user selects a book, they are presented with the pages, 1 at a time, along with the machine-generated text so they can revise it, and approve or edit it.
How I built it
I obtained one standard dataset from the paper cited above, and I used an OCR engine to generate the textual data used in the prototype. I built the web application using Laravel, bootstrap, and MySQL.
Challenges I ran into
I ran into several challenges, the first of which was that I have not done any serious coding in a very long time owing to grad school, where I mostly just write MATLAB scripts. Aside from my intrinsic limitations, the Kraken engine was challenging to use, mainly because of its dependencies. While the authors of the cited paper have generously provided their trained models on github, some of Kraken's dependencies are not being actively maintained for Windows, and so it was not feasible for me to build a working toolset based on Kraken fast enough. Instead, for the sake of demonstration, I used Tesseract OCR, which is being maintained by Google, but its accuracy does not match that reported using Kraken's.
Another minor challenge was working with Laravel 5.5. I have only tried Laravel 4 once, so I had to remember and/or relearn some things about the framework, which took a longer time than I expected.
Accomplishments that I'm proud of
Since I was working alone, and given the aforementioned challenges, I'm very happy that I was able to put a prototype together that showcases almost all of the basic features that I want in the platform.
What I learned
I learned a bit of Laravel 5.5 and php.
What's next for Babl
A very interesting possibility with Kraken is that we can provide a training model that is tailored for each book. According to the paper, roughly 800 lines are needed for training a model, the computational time is less than 24 hours on a single core machine, and it has been shown to allow accuracies exceeding 95%. This can be seen in these sample tests from the paper:
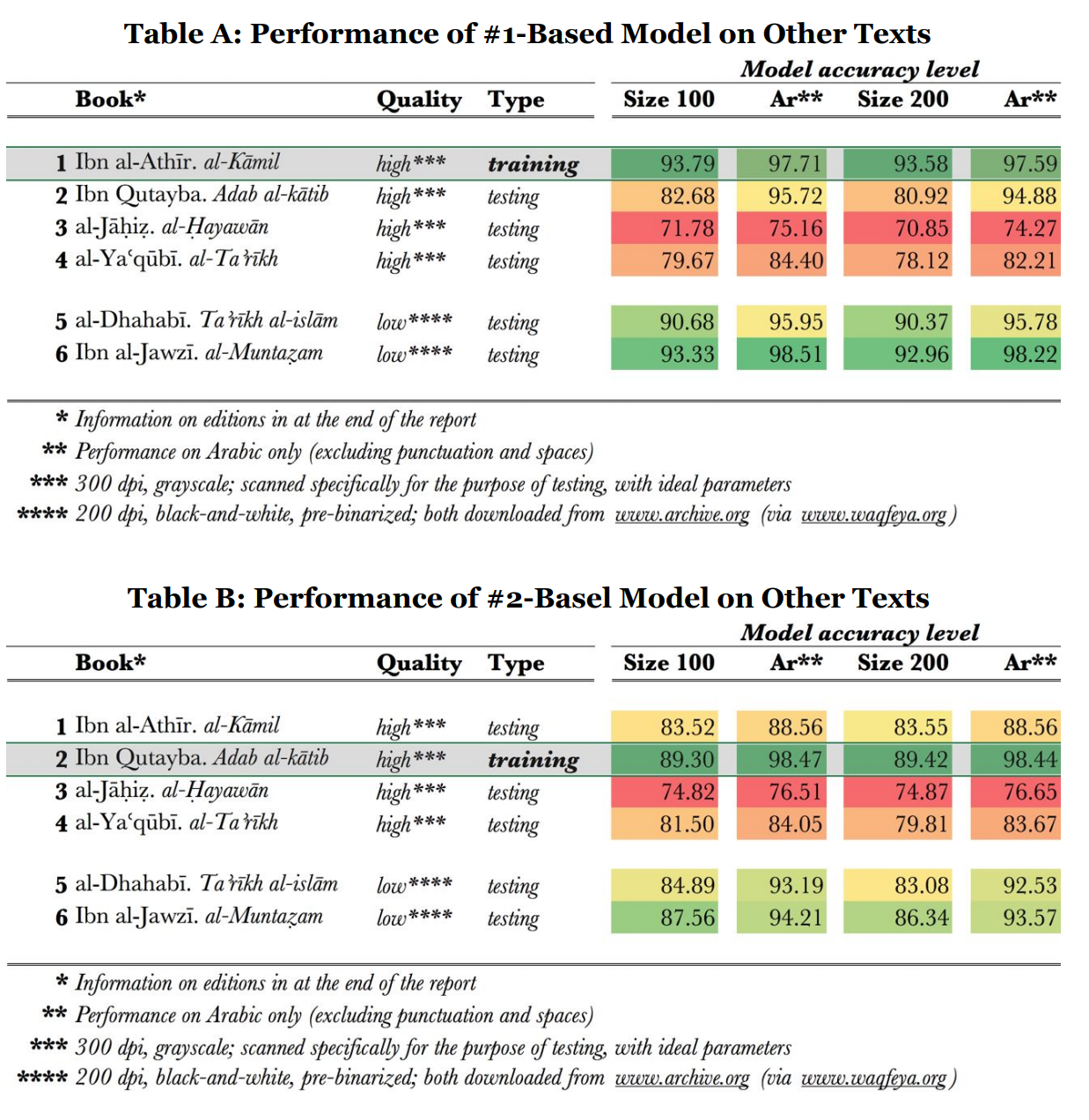
So the two main next steps for Babl are: 1- Move from Tesseract to Kraken 2- Use user-revised and approved text to automatically train more accurate models per book. The main idea is to use a generic model at first with some accuracy so that digitization is at least semi-automated, and then decrease the required user input by training a more accurate.
Another development is to provide a more rich digitization ecosystem, where the edit history for each page is available, along with approval score so that multiple users can revise the same page.
Finally, the whole experience may be gamified with badges and perks to encourage user contribution.
Note
To try the demo, please login using user:test@test.com pass:password.

Log in or sign up for Devpost to join the conversation.