-
-
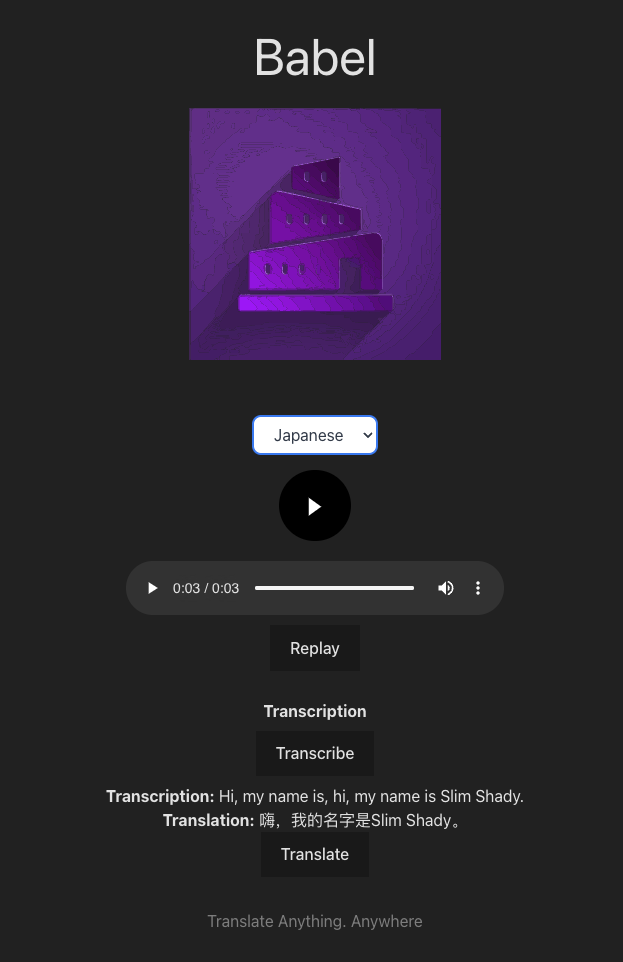
Our App Demo
Inspiration
The Tower of Babel tells of a time when humanity, united by a single language, could achieve monumental feats. Inspired by this, we built Babel a same-voice translation software.
What it does
It performs same-voice live translation by recording the user's audio transcribing their audio and then using a machine learning model to create a new audio file using text to speech that maintains the user's voice.
Why is this important
By creating a solution for live translation, we try to break down language barriers that might prevent communication between people with diverse backgrounds. Especially in software engineering, collaboration and knowledge-sharing are paramount, and a solution to translation ensures that everyone, regardless of their native language, can actively participate, contribute, and understand discussions. Inclusivity in language not only empowers individuals who face linguistic challenges it also is conducive to a supportive environment for female and minority participants. Providing this service that supports same-voice speech, people from different backgrounds can communicate in more inclusive ways without fear of misrepresenting themselves.
How we built it
We built our client application using Express, React, and TypeScript. Additionally, we made use of OpenAI's Whisper and GPT-3.5 model. This allowed use to perform live transcription and translation with relatively low latencies. Additionally, we made a custom service for voice cloning text-to-speech using speaker audio file and Modal Labs to host our containers. This made it so we could perform voice cloning with relatively low latency since Modal Labs uses a parallelized container model that allowed us to spin up containers with an A100 GPU attached to each container. We used Fast API to communicate with our Modal Labs container service for inference and streaming. Lastly, we made use of AWS S3 to store our playback audio file.
Challenges we ran into
The major problem in this project was being able to support audio files. For example, this involved designing the storage systems for audio files, along with hosting an audio streaming API and performing conversion on Numpy arrays outputted by our ML model back to audio/wav.
From our experience, we realized deploying machine learning application from scratch is one of the hardest challenges in modern software engineering. We spent hours trying to optimize our primary voice cloning model to provide efficient and timely inference. When machine learning is your primary product, execution is the most important.
Additionally, learning new frameworks such as React and TailwindCSS for building components was difficult because we had to learn web development skills from scratch.
Accomplishments that we're proud of
We our proud we made a voice cloning streaming service that can be use to convert Text to cloned voice speech using containers.
We are also proud that we managed to come together to building a functioning web application using popular frameworks like React and ExpressJS along with Vite.
We made a fully-functioning web application to read and play audio.
Additionally, we solved problems related to storage by using persistent volumes on Modal Labs along with a public ephemeral s3 blob links for audio playback of TTS.
What we learned
We learned a lot about applying what we learned from Computer Systems to an actual system that can handle audio and performs complex computations like machine learning.
What's next for Babel
The next goal for Babel is to try to improve the latencies for voice cloning and make use of more optimization techniques such as parallelism and GPU kernels.
Built With
- containers
- express.js
- fastapi
- modal
- react
- typescript
- vite

Log in or sign up for Devpost to join the conversation.