

Inspiration
There is a boy from my village who earns over a thousand dollars a month making videos where he walks through fields, picks up ordinary roadside weeds and common grasses, and narrates their identity using ElevenLabs-generated Sanskrit Ayurvedic names with authoritative voiceover. His viewers believe him. They buy what he sells. The herb growing freely in their own field becomes a premium wellness product because nobody can verify the Sanskrit claim. He is not an edge case — he is a business model. Entire brands, some of them nationally established, use Sanskrit formulation names precisely because Sanskrit is inaccessible. The harder the name, the more legitimate it sounds. The more legitimate it sounds, the higher the price. I have watched this happen for years across social media, in health stores, and at wellness fairs. It is a large, profitable, and entirely consequence-free industry built on one structural condition: 1000 years of Ayurvedic clinical knowledge encoded in Sanskrit texts that no modern system can read.
I did not fully understand the technical dimension of this problem until I started researching it. The Ministry of AYUSH formally identified it as an unsolved problem under Smart India Hackathon problem statement SIH1347: Ayurvedic practitioners lack digital tools to query classical formulation knowledge during clinical decision-making. The classical texts — Charaka Samhita, Sushruta Samhita, Ashtanga Hridayam and three others — contain over 300 named formulations with contraindication data, ingredient lists, and disease indications recorded in Sanskrit. A practitioner trained in English medicine cannot query them. A practitioner trained in Ayurveda must rely on memory across all 300 variants because no search tool handles Sanskrit medical vocabulary. When I understood that the reason this problem was unsolved was fundamentally a semantic retrieval problem — not a translation problem, not a data problem — I knew what Elasticsearch's ELSER was built for. AyurSense exists because ELSER is the only retrieval technology that can bridge Sanskrit semantic complexity to modern queryable intelligence. This is not a production-ready project without Elasticsearch. It simply cannot be built any other way.
What It Does
AyurSense is a formulation intelligence system that makes classical Ayurvedic knowledge semantically queryable across three types of users, all powered by a single Elasticsearch-backed intelligence layer.
For the Ayurvedic practitioner, AyurSense is a prescription decision-support tool. The doctor types chief complaints in plain English — "chronic dry cough, weak digestion, fatigue after meals" — into a prescription pad. Behind that input, Elasticsearch's ELSER resolves "cough" to its Sanskrit clinical equivalents Kasa and Ksavatu, "weak digestion" to Mandagni, and executes a semantic search across 300 formulations with automatic prakriti (constitutional type) filtering. What Elasticsearch makes possible here is not synonym lookup — it is semantic inference across a domain vocabulary that has no reliable bilingual dictionary. The Clinical Agent then invokes a dynamic contraindication filter as a pure ES|QL query against the patient's known conditions, removing formulations that would be unsafe for that specific patient. A diabetic patient does not see formulations containing Madhu (honey). The practitioner sees only safe, ranked results with ghost cards showing what was removed and why. Elasticsearch did this — not application logic.
For the researcher or educator, AyurSense's Research Mode surfaces citation authority
across classical texts. The Research Agent executes a COUNT_DISTINCT(source_text) ES|QL
aggregation that ranks formulations by how many distinct classical texts independently
recommend them for a given condition. A formulation cited in four out of six classical
texts carries cross-textual consensus that a single-source citation does not. This is a
confidence signal that could not be computed without Elasticsearch's aggregation layer.
The Chrome Extension brings AyurSense into the practitioner's existing workflow. While reading a PDF case study or a research article, the practitioner selects a Sanskrit Ayurvedic term, right-clicks or presses the keyboard shortcut, and AyurSense opens in Chrome's native side panel with context-aware search results derived from the selected text and surrounding page context. Sanskrit terms in PDF pages show inline tooltips explaining their clinical meaning. Classical knowledge becomes reachable from inside any clinical reading workflow, not only from a dedicated application.
How I Built It
The architectural foundation is Elasticsearch Serverless with semantic_text field
type on the formulations index. This single decision eliminated an entire class of
infrastructure complexity. On self-managed Elasticsearch, deploying ELSER requires
allocating ML nodes, configuring inference pipelines, and managing model loading.
On Serverless, declaring a field as semantic_text is sufficient — ELSER inference
runs automatically at ingest and at query time with zero model configuration. For a solo
build with a 75-hour timeline, this was not a convenience feature. It was an
architectural unlock that made the project possible. The formulations index has two
semantic_text fields: diseases_treated and text_excerpt_english. Every document
is embedded at ingest. Every MATCH() query runs ELSER retrieval without any
client-side embedding step.
Sanskrit synonym resolution required a second Elasticsearch index. The ayurveda_synonyms
index stores deterministic English-to-Sanskrit cluster mappings: "fever" maps to
["Jvara", "Santapa", "Vishama Jvara"], "cough" maps to ["Kasa", "Ksavatu",
"Kapha-ja Kasa"]. Before each ELSER search, a synonym expansion ES|QL query resolves
the doctor's English terms to Sanskrit clusters. These clusters are then injected as the
MATCH() query string, combining deterministic clinical precision with ELSER's open
vocabulary handling. The synonym index is stored in Elasticsearch rather than a hardcoded
file because it is queryable, extensible, and auditable — new terms can be added without
code changes, and the synonym underline system in the prescription pad textarea reads
from it live.
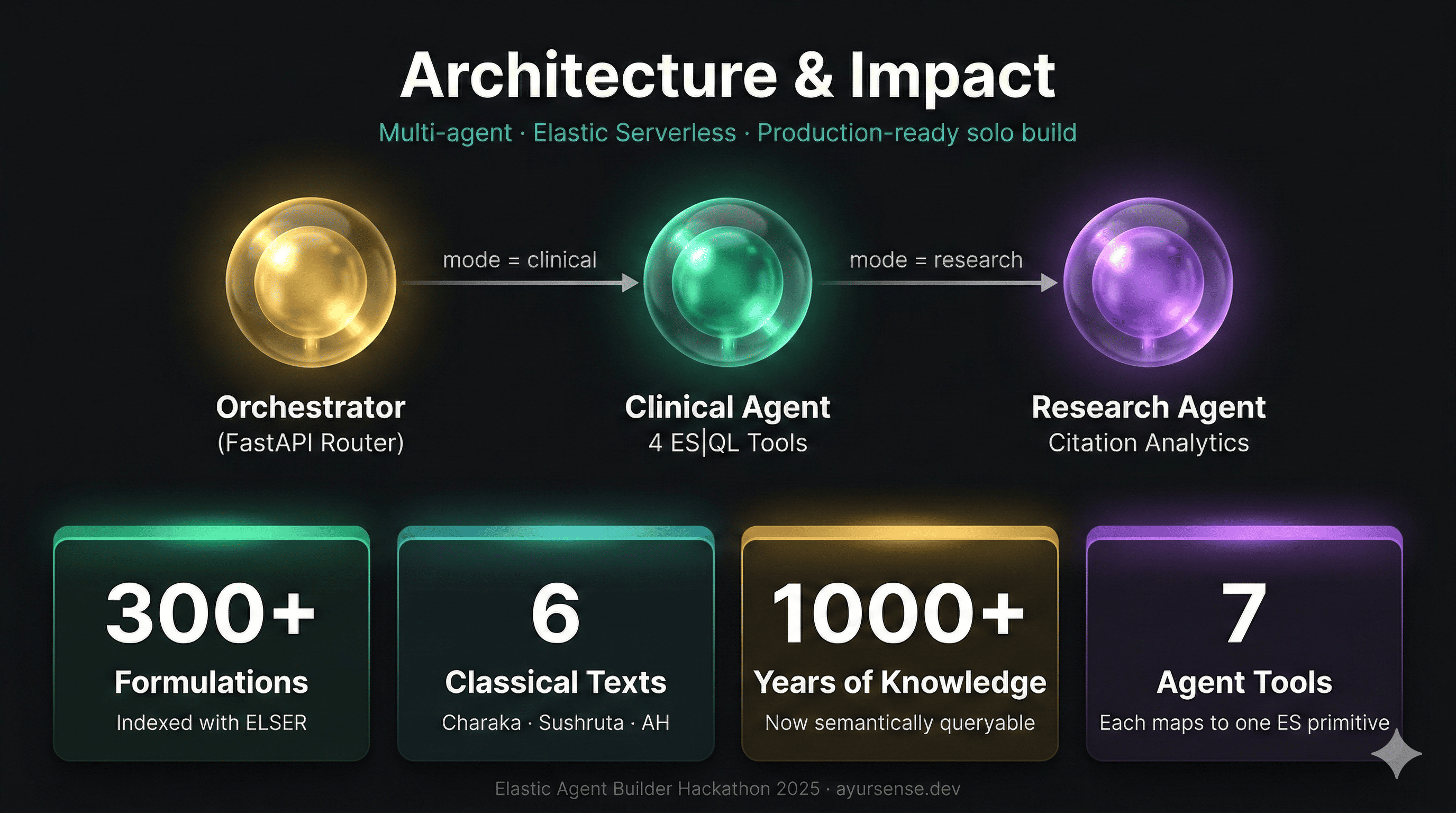
The multi-agent architecture uses Elastic Agent Builder with three agents. The
Orchestrator receives the doctor's input and routes by mode: clinical search or citation
research. The Clinical Agent executes a four-tool sequential pipeline — synonym
expansion, ELSER hybrid search with prakriti filter, dynamic contraindication filter,
and herb disambiguation — each tool backed by a distinct Elasticsearch primitive. The
Research Agent executes citation analytics using COUNT_DISTINCT and VALUES
aggregations in ES|QL. A verification loop in the Orchestrator detects when the Clinical
Agent's contraindication filter removes high-authority formulations and triggers the
Research Agent to surface substitution candidates with equivalent classical consensus.
Seven tools across three agents, each tool a thin wrapper over one Elasticsearch
operation.
Herb disambiguation required solving a specific problem: the Sanskrit herb name Abhaya
refers to different botanical species depending on which classical text is cited and
which disease context it appears in. I built herb_disambiguate as an ELSER query
against a dedicated herb context index, returning a resolved Latin botanical identity
with a confidence score derived from match count across formulation contexts and an
evidence citation pointing to the source texts used for resolution. A critical constraint
appeared during development: nested field objects are unsupported in ES|QL on Serverless.
The ingestion pipeline was modified to extract flattened ingredient_names_sanskrit and
ingredient_names_latin keyword arrays alongside the full nested ingredient structure,
enabling ES|QL herb queries without losing the rich data model for application use.
The backend is Python 3.12 with FastAPI, strict Pydantic v2 models, and typed async
ES|QL query functions for all six query patterns. The frontend is Svelte 5 with
TypeScript and Zod schemas at all API boundaries — every field from Elasticsearch has
a corresponding Zod validator that runs at the fetch boundary, not in components. The
Chrome Extension is Manifest V3 with a custom ebuild.mjs build script producing a
Chrome Web Store-ready zip. The prescription pad is fully stateless client-side: no
patient data touches the server, and the print output is a CSS-rendered Rx slip with
doctor letterhead, dosage instructions, and pathya/apathya dietary guidance
auto-populated from the formulation's Elasticsearch record.
Challenges I Ran Into
The deepest technical challenge was Sanskrit's vocabulary topology. A keyword search for "fever" across 300 formulations would return nothing — the texts use Jvara, Santapa, and Vishama Jvara for clinically distinct fever types that share no English characters. The naive solution is a translation dictionary. The real solution is understanding that Sanskrit medical vocabulary is not a finite enumerable set — it is a living clinical language where the same English concept maps to multiple Sanskrit terms with different clinical weights depending on the school of thought, the century of the text, and the patient constitution being described. ELSER handles the open vocabulary problem because sparse vector inference captures semantic proximity across domains even when direct lexical overlap is zero. The two-layer architecture — synonym index for deterministic precision on known clinical terms, ELSER for open vocabulary semantic recall — took several iterations to calibrate correctly. Relying only on the synonym index produced brittle results when English input varied from the indexed terms. Relying only on ELSER drifted on high-stakes clinical Sanskrit terms with low English corpus representation. Both layers together produce reliable retrieval.
The semantic_text behavior on Elastic Serverless required careful understanding that
differed from documentation written for self-managed deployments. ES|QL syntax on
Serverless is stricter — ARRAY_CONTAINS() does not exist, requiring adaptation to
IN operator patterns for array field filtering. The METADATA _id declaration is
required in ES|QL to return document IDs, which matters for the contraindication filter
where I needed to identify removed documents by ID for the filtered_out ghost card
array. Understanding the exact Serverless ES|QL grammar rather than assuming parity
with self-managed documentation was a consistent requirement throughout the build.
Multi-agent coordination presented a coordination reliability challenge. The Orchestrator
needs to detect when Clinical Agent results are insufficient — specifically when
high-authority formulations were removed by contraindication filtering for a patient
whose condition list is uncommon — and re-route to the Research Agent for substitution
candidates. Defining "insufficient" as a triggerable condition rather than a subjective
judgement required grounding the verification loop in concrete signals: the length of
filtered_out[], the citation_count of removed formulations, and whether the safe
results list contains at least one formulation with unique_texts >= 3. The loop is
deterministic and auditable, not a model judgement call.
Accomplishments That I'm Proud Of
Running ELSER over Sanskrit medical texts and having it work — genuinely work, not approximately work — is the accomplishment I am most satisfied with. Sparse vector inference was not designed with Sanskrit in mind. Sanskrit Ayurvedic vocabulary is among the most domain-specific text any retrieval system could encounter: technical terminology with no modern usage, clinical concepts with no English equivalents, and a six-century span of textual variation across source texts. The fact that ELSER's semantic proximity model captures clinical relationships across this corpus — that querying "weak digestion" surfaces formulations treating Mandagni and Agnimandhya — is a demonstration that sparse vector inference handles narrow domain vocabulary better than any keyword-based approach could. Nobody has applied ELSER to this corpus before. That result matters beyond this hackathon.
Building a production-architecture system — strict type safety end-to-end, Pydantic models on the backend, Zod schemas at every API boundary on the frontend, 37 tests across unit and integration layers, Chrome Extension with its own build pipeline — as a solo project in 75 hours is something I am quietly proud of. The architecture did not cut corners to meet the deadline. Every decision was made as if this system would be deployed to real Ayurvedic practitioners, which it will be.
The multi-agent disagreement-resolution loop producing more complete recommendations than any single-agent approach represents a design I believe in. When a patient's contraindication profile removes high-authority formulations, the system does not simply return fewer results — it recognises the gap and triggers a second agent to surface classically authoritative substitutes. This is the kind of behaviour that makes AI systems clinically useful rather than clinically risky.
What I Learned
I did not know Elasticsearch before this project at the depth I know it now. I had used it as a search backend — documents in, keyword queries out. What this project taught me is that Elasticsearch is a reasoning substrate when it is used correctly. Every intelligence operation in AyurSense — synonym resolution, semantic retrieval, contraindication filtering, citation authority ranking, herb disambiguation — runs as an Elasticsearch query. The FastAPI backend has almost no business logic. The logic is in the data layer, which is exactly where it should be for auditability, performance, and maintainability.
The semantic_text field type on Elastic Serverless changed how I think about deploying
semantic inference permanently. Before this project, I would have approached ELSER
deployment as an infrastructure problem requiring ML node allocation, pipeline
configuration, and model management. After building AyurSense on Serverless, I
understand that zero model configuration is not a convenience feature — it is an
architectural unlock that separates inference deployment from application development.
I can declare a field semantic and focus entirely on what the retrieval needs to
accomplish. That shift in how I approach the problem changes every project I build
going forward.
ES|QL changed how I think about the application-layer boundary. Before AyurSense, I would have fetched candidate results from Elasticsearch and filtered them in Python. Seeing contraindication filtering execute as a pure ES|QL query — dynamic patient conditions injected at query time, filtering happening inside Elasticsearch, filtered documents returned with full records for ghost card rendering — made me understand that keeping intelligence inside the data layer is not just a performance optimisation. It is the difference between logic that is auditable, testable, and portable versus logic that is buried in application code.
Elastic Agent Builder changed how I design AI systems. I have built LLM applications before using orchestration frameworks where the agent's tool usage is opaque and hard to observe. Agent Builder's tool trace UI, where every tool invocation with its parameters and results is visible in real time, made me understand that observability is not a logging problem — it is an architecture problem. Designing tools as thin wrappers over single Elasticsearch operations produced a system where every agent decision is traceable to a specific query result. That is a different quality of reasoning than black-box chains.
This hackathon upgraded my workflow in a specific way: I now reach for Elasticsearch when the problem involves domain-specific semantic intelligence, not when the problem is search or storage. AyurSense's intelligence would not exist without Elasticsearch. That is not a statement about the product — it is a statement about my understanding of what the platform can do.
What's Next for AyurSense
Sanskrit is difficult enough that Indian medical students trained in classical Ayurveda struggle with the original texts. AyurSense is not a complete solution — it is the first version of a solution to a problem that has been unsolved for decades. The 300 formulations indexed represent roughly one sixth of the classical corpus. The six source texts represent a fraction of the 150+ classical Ayurvedic texts that exist. What I have built is a working architecture and a proof that ELSER-powered Sanskrit semantic retrieval is not only possible but reliable. The next step is scaling it.
I will reach out to the Ministry of AYUSH and to Ayurvedic medical colleges in India to explore institutional deployment. A practitioner-facing tool of this kind needs clinical validation from domain experts, and that process needs to begin with the organisations that have both the knowledge and the mandate to validate it. I will also pursue partnerships with Ayurvedic research institutions that are working on Sanskrit text digitisation — the more classical text data is indexed, the stronger the semantic retrieval becomes.
On the technical roadmap, the next milestone is multilingual support. Hundreds of millions of patients across India discuss their health in Hindi and regional languages, not English. Elastic's NLP capabilities make Hindi semantic search tractable, and extending the synonym index to cover Hindi medical vocabulary is a straightforward architectural addition to what already exists. After that, real-time integration with AYUSH's digital repositories would allow the formulation index to grow dynamically as new digitised text becomes available.
The conversational patient interface — where patients and students can ask plain-language questions about Ayurvedic concepts and receive Sanskrit-explained responses — is the next user-facing layer I will build. The practitioner tool demonstrates that the Elasticsearch intelligence layer works. The patient interface would make that layer accessible to everyone, not only to trained practitioners.
I feel a responsibility to this knowledge that I did not feel before I built this project. Sanskrit Ayurvedic texts contain 1000 years of accumulated clinical observation. That knowledge belongs to everyone — to practitioners, to patients, to researchers, and to the communities whose ancestors wrote it. It does not belong to the wellness brands and social media channels that profit from its inaccessibility. I will maintain AyurSense long-term and continue building on Elastic's platform because the problem this project addresses is not solved by a hackathon submission. It is solved by deployment, iteration, and the sustained commitment to make classical Ayurvedic knowledge as queryable as any modern medical database.
Built With
- elastic-ai-agent
- es|ql
- python
- svelte
- typescript

Log in or sign up for Devpost to join the conversation.