Inspiration
In 2026, AI can ship features faster than any team—but it still can’t prove the feature works. Code can compile, types can pass, and the UI can look “done”… while the login button does nothing, the error state never appears, or checkout fails only in a real browser.
Axolotl was born from that paradox: AI code velocity is exploding, but QA hasn’t scaled. We wanted an agent that doesn’t assume correctness—one that validates behavior the way users experience it: in a real, messy, dynamic UI.
What it does
Axolotl is a Gemini-powered QA agent that tests applications end-to-end by driving a real browser.
- Converts a natural-language requirement into a structured test plan (happy path + edge cases + failure modes)
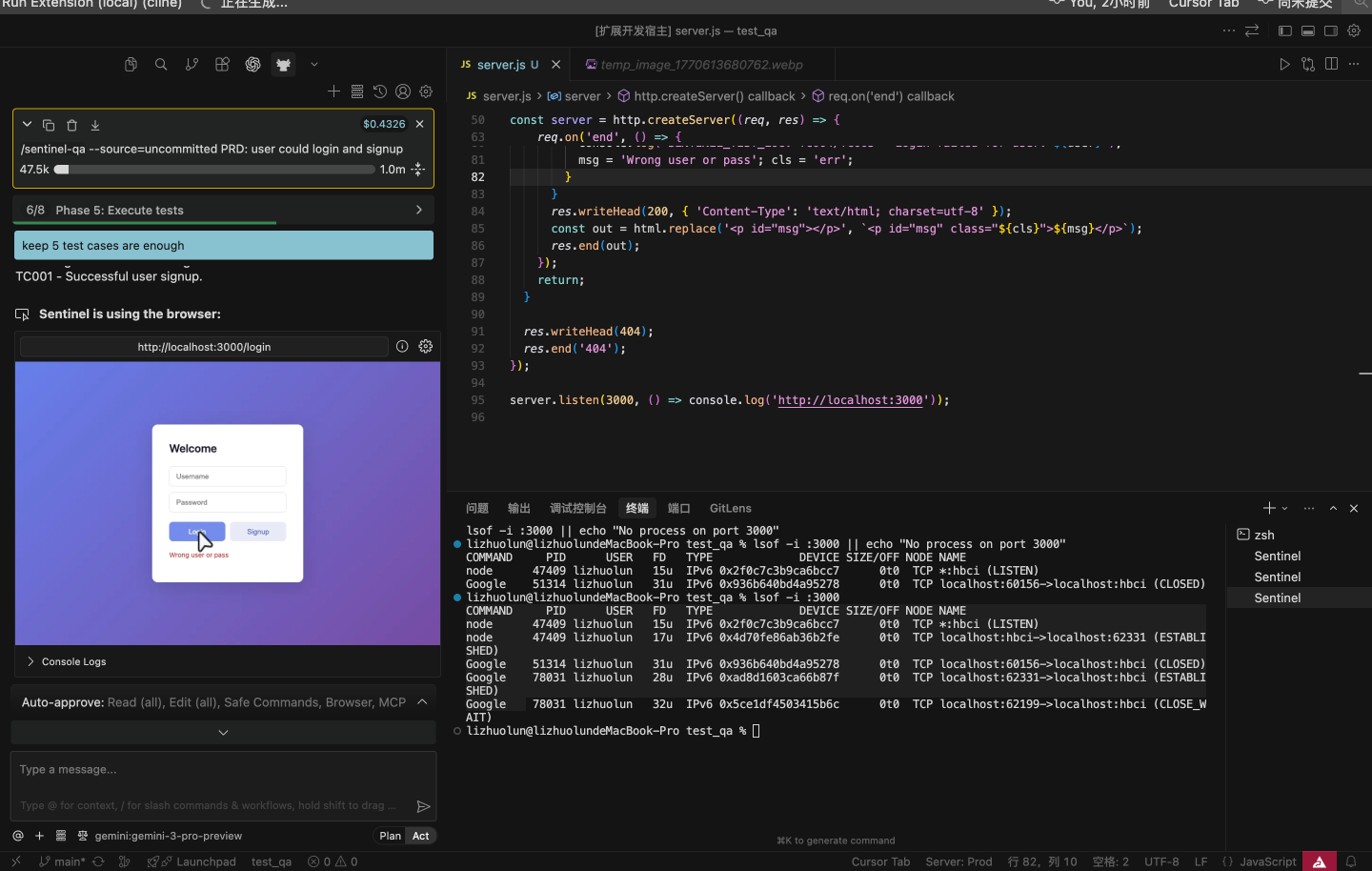
- Executes steps like a real user (navigate, type, click, wait, verify)
- Collects evidence (screenshots and runtime signals) for every critical assertion
- Produces an evidence-backed verdict: ship / no-ship, plus a clear report of what failed and where
Instead of brittle selectors, Axolotl focuses on intent: it looks for the right control (“Log in”, “Continue”, “Submit”) and adapts when UI structure or styling changes.
How we built it
Axolotl is built around the Gemini 3 API as the planner + judge inside an agentic loop:
- Planning: Gemini translates product requirements into executable, step-by-step test cases
- Tool/function calling: Gemini invokes browser actions (click/type/scroll), captures screenshots, and queries page state
- Multimodal understanding: Gemini interprets what’s on screen to decide the next best action and verify outcomes
- Structured outputs: Plans, steps, assertions, and results are machine-readable to keep runs deterministic and debuggable
- Evidence-first reporting: Every pass/fail is tied to observable outcomes, not just “the model thinks it worked”
At a high level, the loop is:
[ \text{observe} \rightarrow \text{plan} \rightarrow \text{act} \rightarrow \text{verify} \rightarrow \text{report} ]
Challenges we ran into
- Flakiness in real UIs: async loading, animations, transient toasts, and delayed navigation
- Grounding: preventing the agent from “assuming success” without verifying a visible outcome
- UI variability: different layouts, component libraries, and ambiguous labels across apps
- Speed vs certainty: moving fast while still making assertions strong enough to be meaningful
- Reproducibility: keeping outputs structured so failures are actionable, not just descriptive
Accomplishments that we're proud of
- Built an end-to-end QA workflow that runs in a real browser and verifies behavior through observation
- Made results evidence-backed (screenshots + runtime signals), so failures are easy to trust and reproduce
- Created test plans that cover not only success paths, but also the failure cases developers usually forget
- Achieved a UX that turns “does it work?” into a fast, decisive answer: ship / no-ship
What we learned
- The most valuable agent behavior is verification, not generation—every action needs an observable check
- “AI QA” needs guardrails: structured steps, explicit assertions, and consistent evidence capture
- Evidence-first reporting beats long explanations: one screenshot tied to one assertion is incredibly powerful
- End-to-end testing becomes more important as AI code generation increases, because the cost of silent failure rises
What's next for Axolotl
- Expand coverage beyond web flows: auth, payments, onboarding, and multi-step forms with richer assertions
- Add stronger reliability features: better waits, retries for safe steps, and smarter state synchronization
- Improve reports: clearer timelines, diffs between runs, and minimal reproducible failure steps
- Enable continuous “pre-merge” QA: run Axolotl automatically on new AI-generated changes and block risky merges
Built With
- agent
- deepmind
- gemini
- qa
- test
- typescript


Log in or sign up for Devpost to join the conversation.