Try it out on Google Cloud http://prediction-service-2-dot-keen-genre-220015.appspot.com/
Inspiration
Our inspiration is our interest in the stock markets and always wanting to do something with the Twitter API. We also wanted to try a new language and knew Python is good for artificial intelligence projects.
What it does
Our application scrapes users' tweets to find out their sentiment on different companies. We then use this sentiment to determine how well a company is doing in the public eye. We believe the more positively and recently a company is being talked about on twitter, the higher a consideration should be for investing in it.
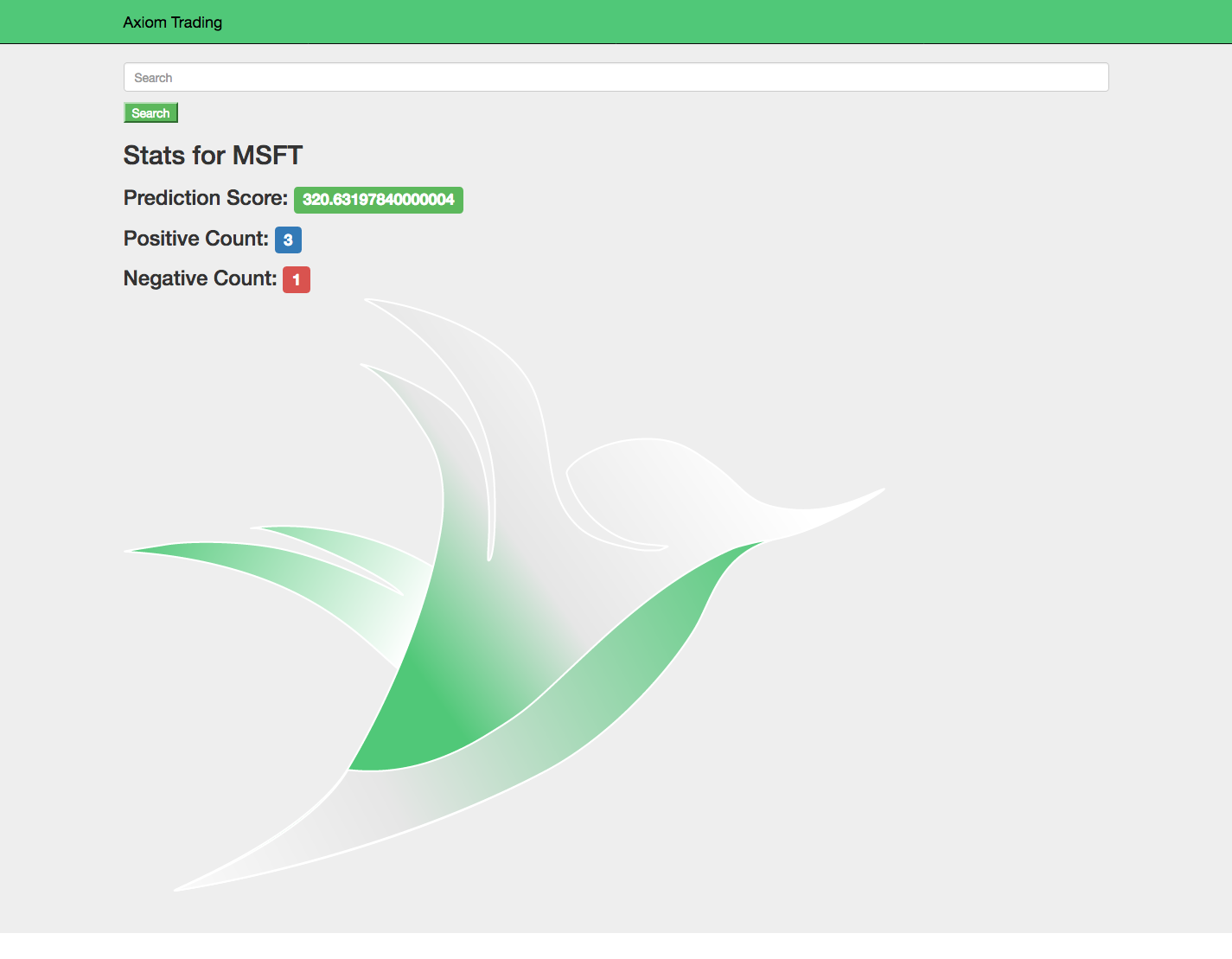
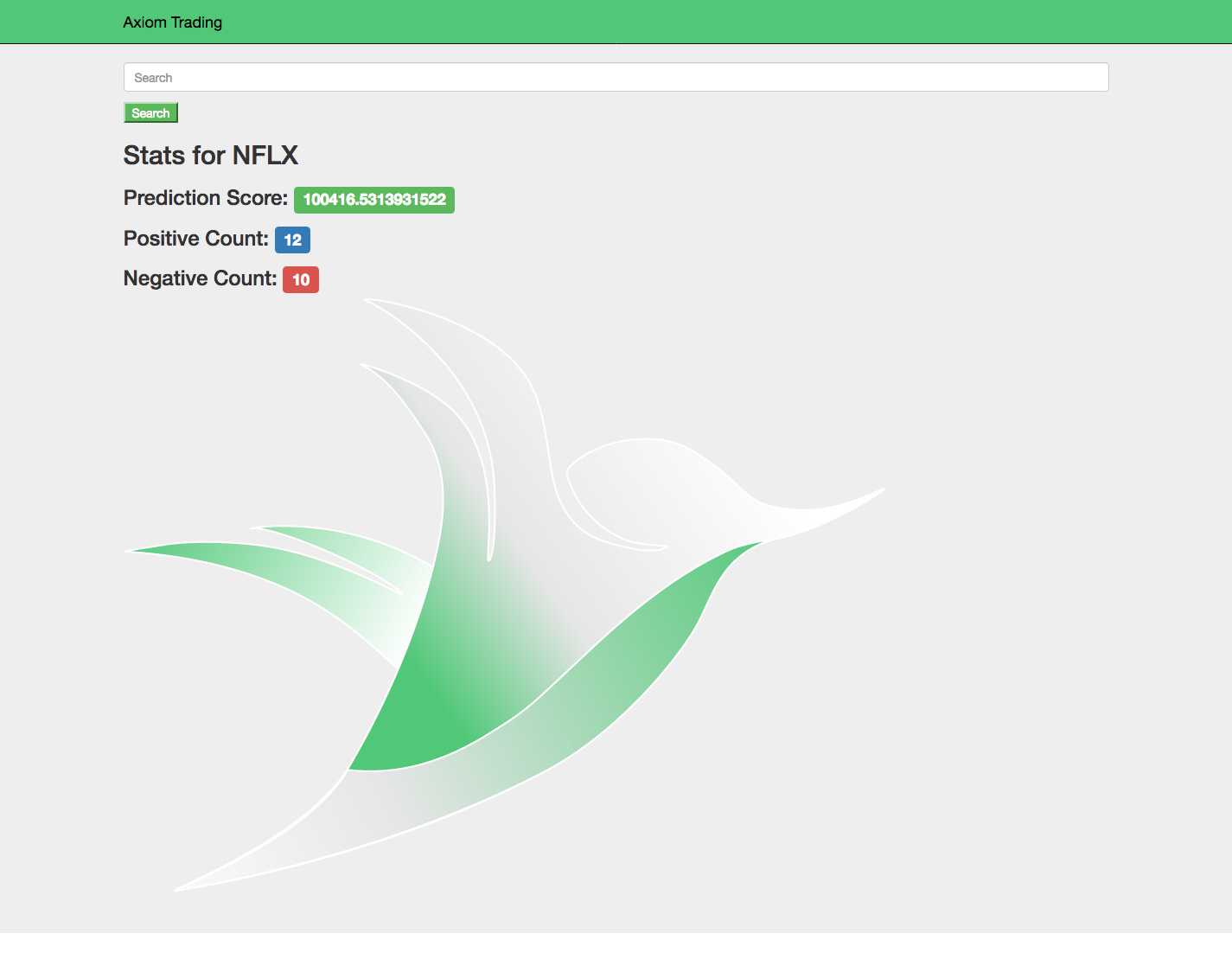
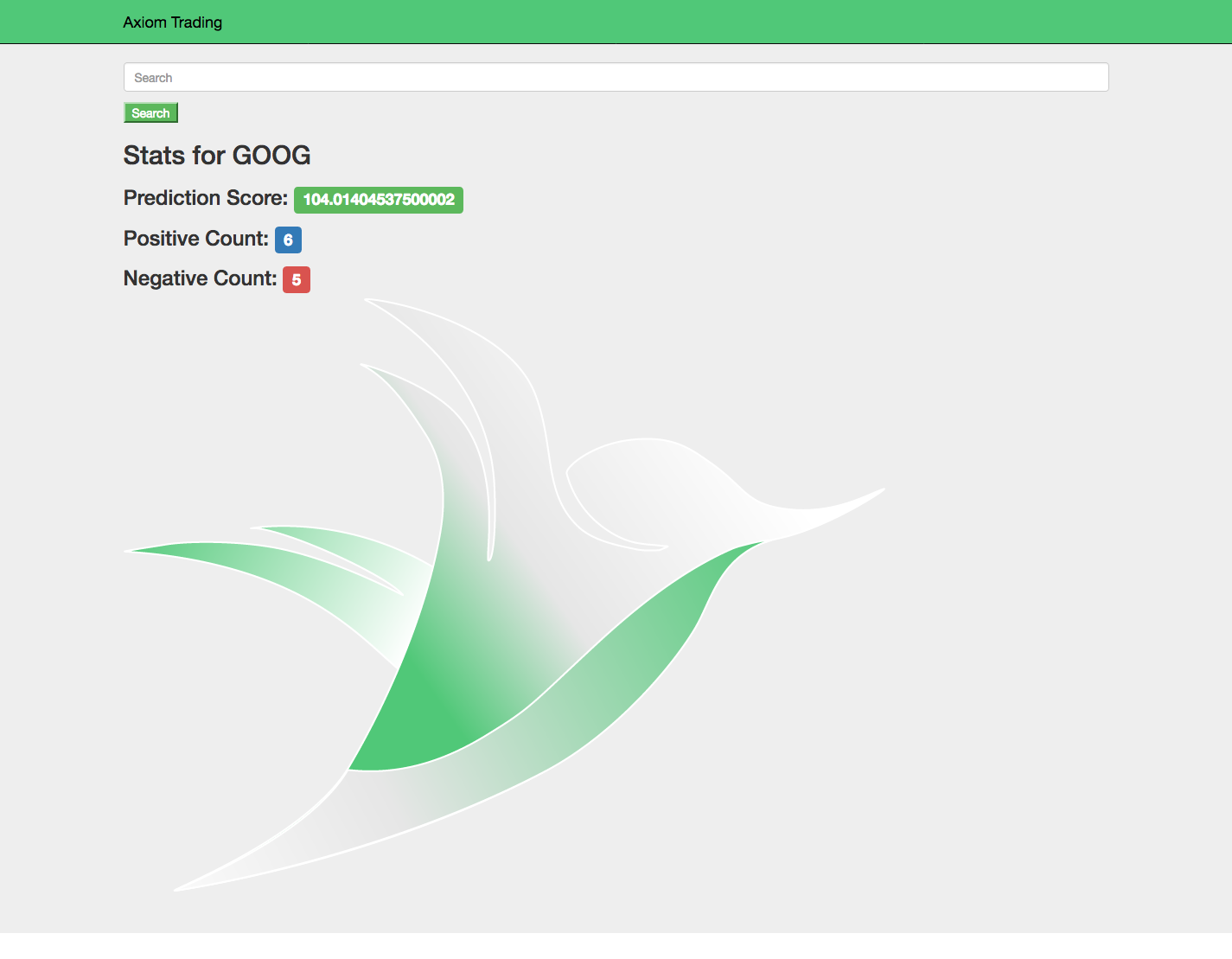
The application takes in a company stock ticker and then uses our artificial intelligence heuristic to give the company a buy or sell score. The score is based on how many positive and negative tweets we have scraped, how recent they are, and how trustworthy the tweeter is.
How we built it
We take the most recent tweets of a user and put them into our Google Cloud database. We then go through that user's friends and put their tweets in our database, and so on in a breadth first search manner. We heuristically decide whether a user is a worthy source based on if they're twitter verified, how many followers they have, and how often and recently they have tweeted. We then give this tweeter a score that we use for our tweet sentiment analysis later on.
The tweets are passed to Watson for sentiment analsys using artificial intelligence and natural language processing. Every tweet gets a score based on that. When a user queries for a company, we take Watson's scores and our tweeter trustworthiness scores to determine a final buy or sell score for the company.
The user interface is built to be a simple and functional way to access our data. When a user searches for a company, it is easy to the prediction we give a stock on whether it's a buy or sell, and how many people are talking positively or negatively about it.
Challenges we ran into
Twitter rate limiting our requests. We couldn't use the official Twitter API because it only allowed about 15 requests per minute, and we are doing many, many more requests than that. Instead we just used the API to get the list of a user's friends, which is 1 request, and then built a web scraper to get all the tweets every user. This was still being rate limited, so we made the code wait a few seconds after each request.
Accomplishments that we're proud of
We're all proud of different things. Most of the technologies we worked on during this hackathon we haven't used before. Ryan is proud on learning how to do Google Cloud deployment. Joel is proud of learning Python and how to use the Twitter API. Jevay is proud of finding a hack to get around the rate limit Twitter put on us. Mark is proud about learning Python and connecting it to a Google Cloud database.
What we learned
We learned how to use the Google Cloud to deploy an application. Most of us also haven't used Python before. We also learned Twitter's API and Watson.
What's next for Axiom Trading
We would like to add caching to the sentiment analysis scores so that receiving stock scores are faster. Right now, every time you get a stock score, it run an analysis in real time instead of pulling the score from the cache. We would also like to add automatic trading. We thought about integrating it with Yahoo Finance and having it do trades in real time based on trending tweets, but did not have enough time to implement that this hackathon.







Log in or sign up for Devpost to join the conversation.