-

home page
-
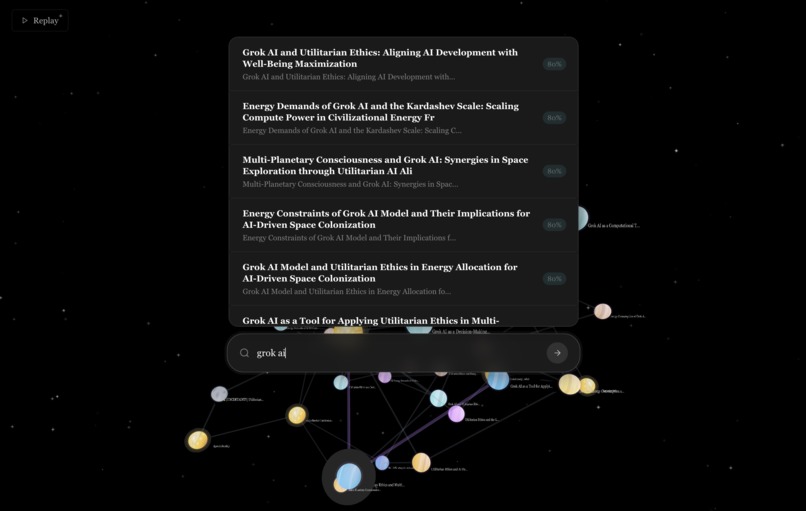
search engine
-
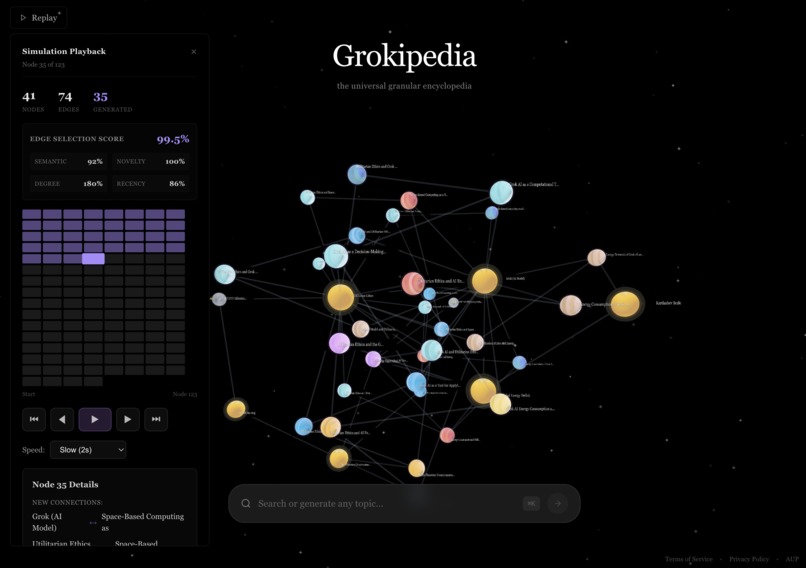
generation algorithm
-
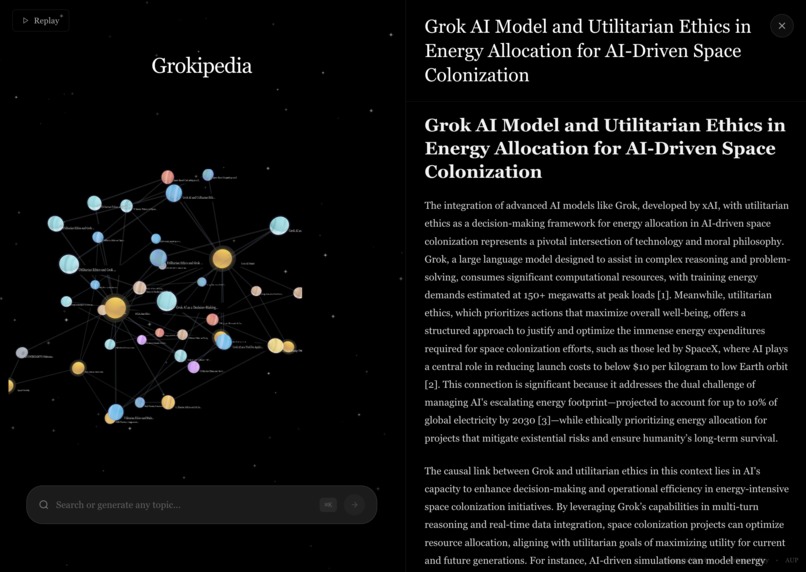
viewing an article

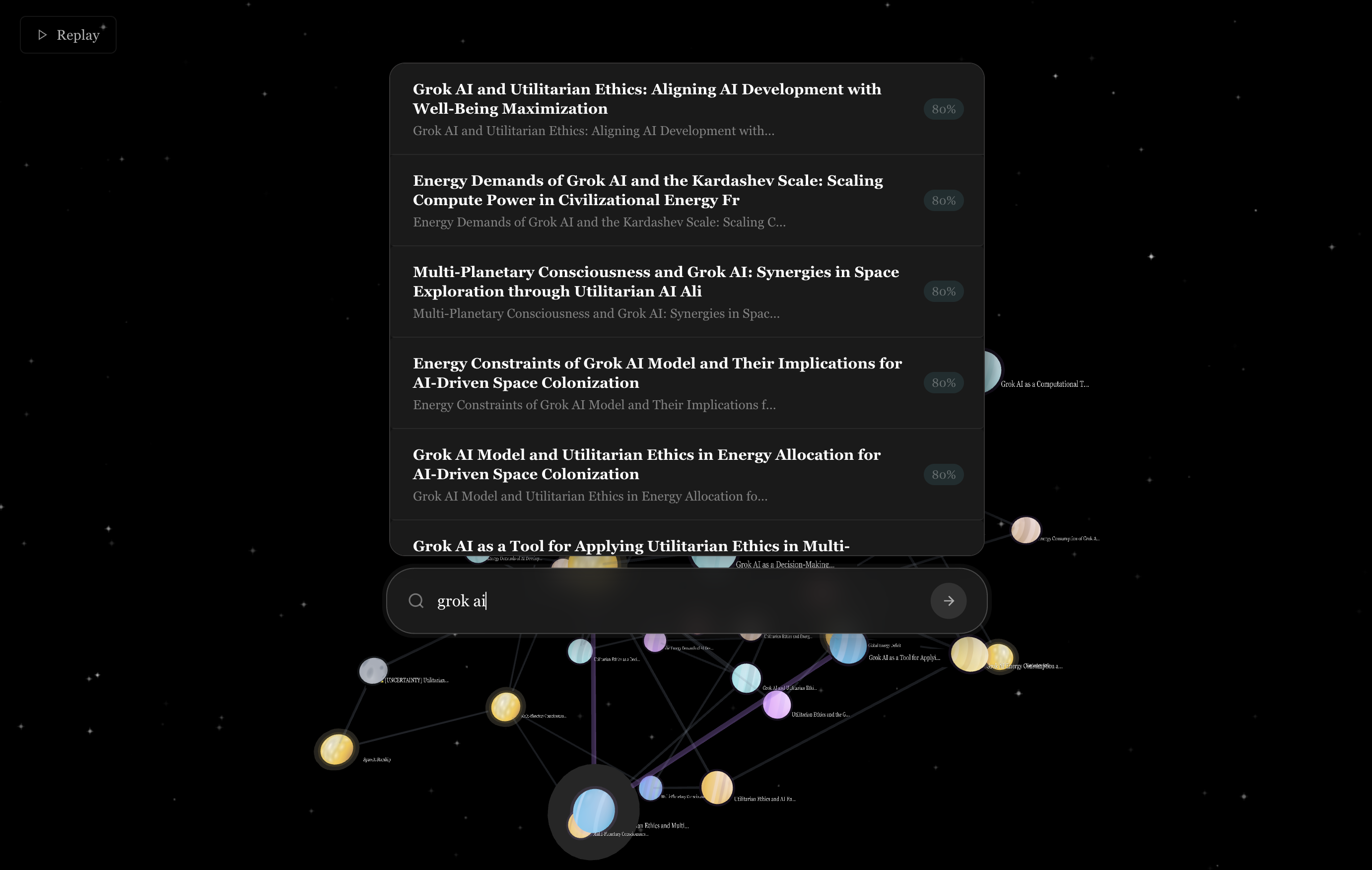
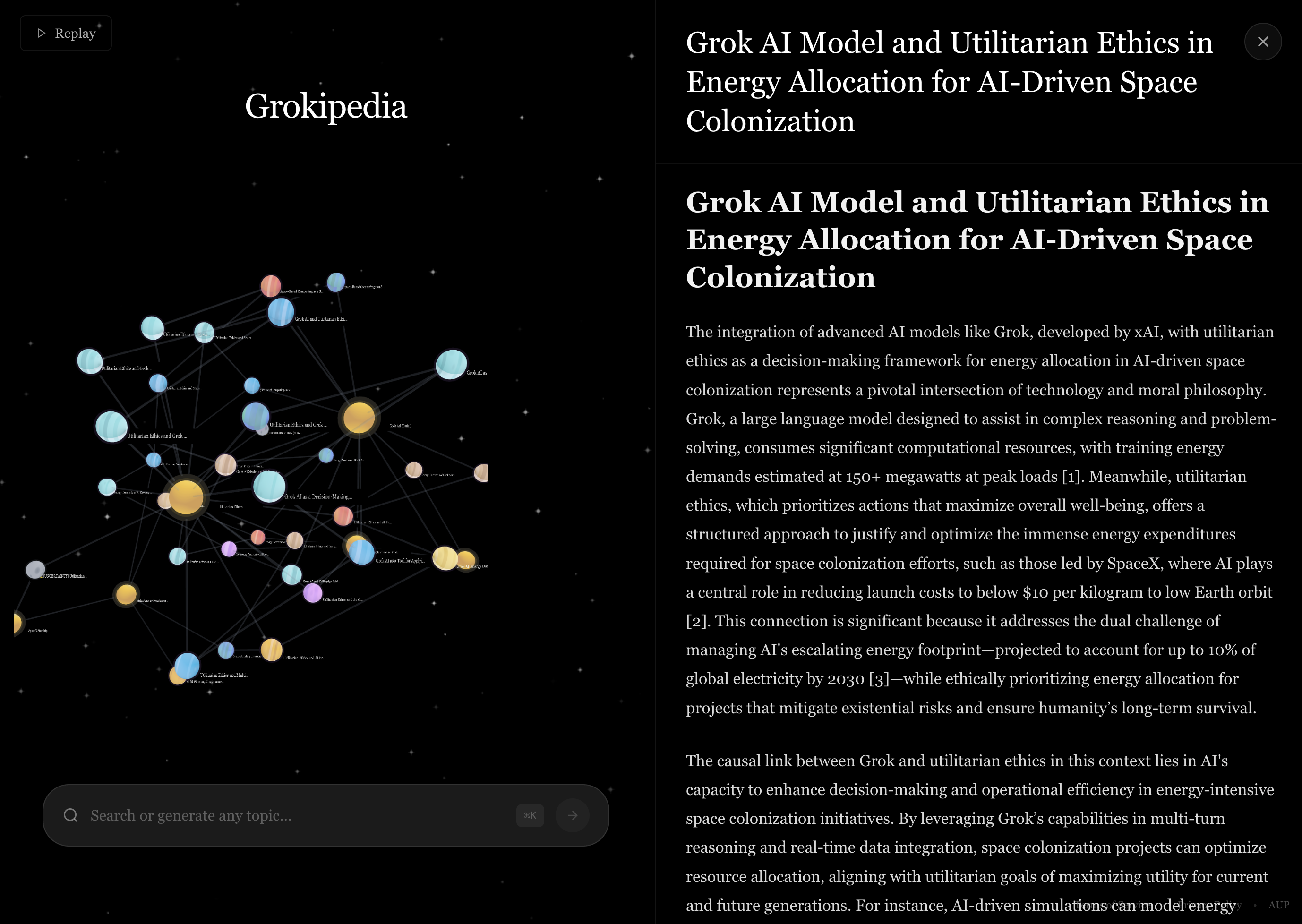
Inspiration
We imagine Grokipedia as a repository of human experience and history since the beginning of time, to be shared across the universe.
What it is
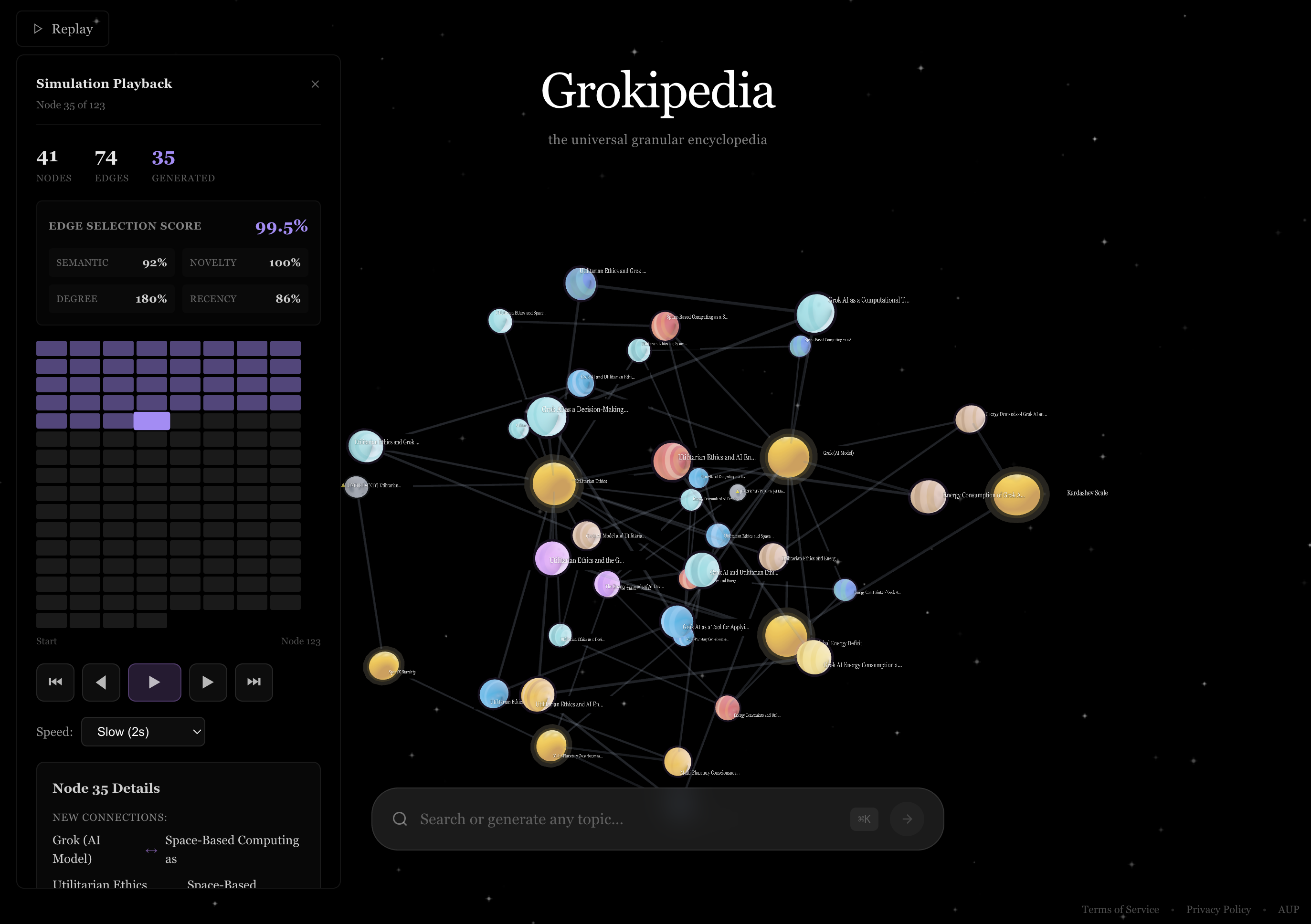
Axiom is an infinite corpus of knowledge, containing information about high-level topics as well as extremely niche minutia. Every aspect of the corpus is based around reinforcing utilitarian ideals, codified into the following three categories: causal distance, integrity tension, and query frequency.
How it works
Axiom's growth is managed by a dual system of prioritization and self-correction.
1. Weighted Prioritization (The P Score)
The Priority Score (P) is the core function that determines which knowledge connections are the most valuable to generate. It ensures Axiom's generative resources (f_LC) are focused on high-impact edges rather than brute-force expansion. The mathematical function is a weighted sum:
$$ \text{P} = \alpha \text{D}_C + \beta \text{T}_I + \gamma \text{F}_Q $$
- D_C (Causal Distance): Fills Gaps. Measures the conceptual or temporal leap required, prioritizing the bridging of large knowledge holes.
- T_I (Integrity Tension): Tests Truth. Measures the difference in Integrity Scores (S_A), forcing the verification of uncertain knowledge against trusted facts.
- F_Q (Query Frequency): Optimizes Utility. Measures how often the two concepts are requested by external users, prioritizing high-demand knowledge.
2. Uncertainty Node (U) Mechanism
The U Node mechanism handles the limitations of the knowledge graph by turning failure into a priority task for self-correction.
- Trigger: If the f_LC process on a high-P edge yields a contradiction, conflict, or low confidence result, an Uncertainty Node (A_U) is created instead of a new article.
- Action: A_U is assigned a high Resolution Score (R_U) that dictates its urgency. This triggers a Resolution Batch, forcing a rerun of the connection with deeper reasoning or external retrieval to resolve the conflict.
- Result: Successful resolution leads to a significant increase in the parents' Integrity Scores (S_A), ensuring failures directly reinforce the graph's overall truthfulness.
3. Generative Phases (G1, G2...)
Axiom's knowledge corpus grows iteratively, guided by the P Score:
- Initial Generation (G1): Start by identifying the Top 5-10 Seed Node pairs with the highest Causal Distance (D_C) to immediately establish key foundational connections.
- Iterative Growth (G2, G3...): In every subsequent cycle, all potential new edges are scored using the full P function. The Top 10 edges are selected for generation. Any resulting conflict triggers the U Node resolution process before the next cycle begins.
Here are some examples of the prioritization schema at work:
Filling a Major Gap
- Article Pair Focus: History/Cause & Effect (e.g., Sputnik Launch to NASA Creation)
- Dominant Metric: Causal Distance (D_C): High
- Why it's a Priority: This connection bridges a wide conceptual or temporal gap. It generates a significant, high-level article that formalizes a critical link in the knowledge chain.
Testing Integrity
- Article Pair Focus: Controversial/Conflicting Concepts (e.g., Established Banking vs. Alternative Economics)
- Dominant Metric: Integrity Tension (T_I): High
- Why it's a Priority: This pair has a high difference in confidence (S_A). Connecting them forces Grok to verify or falsify the shaky concept against the stable one, directly improving graph truthfulness.
Optimizing for Utility
- Article Pair Focus: High-Demand Current Topics (e.g., Core AI Tech vs. Global Regulation)
- Dominant Metric: Query Frequency (F_Q): High
- Why it's a Priority: Users frequently search for information linking these two concepts. Generating this edge optimizes Axiom's output to immediately serve high external demand.
Built With
- grok
- ontology




Log in or sign up for Devpost to join the conversation.