-
-
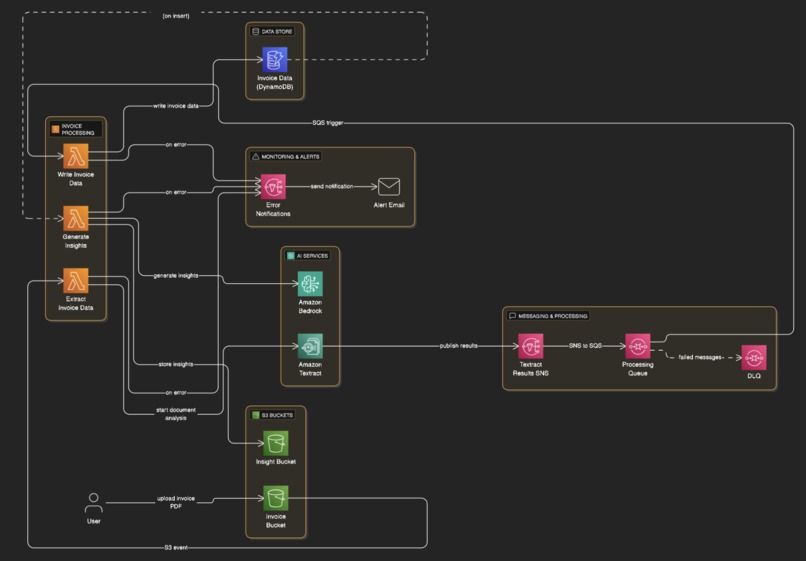
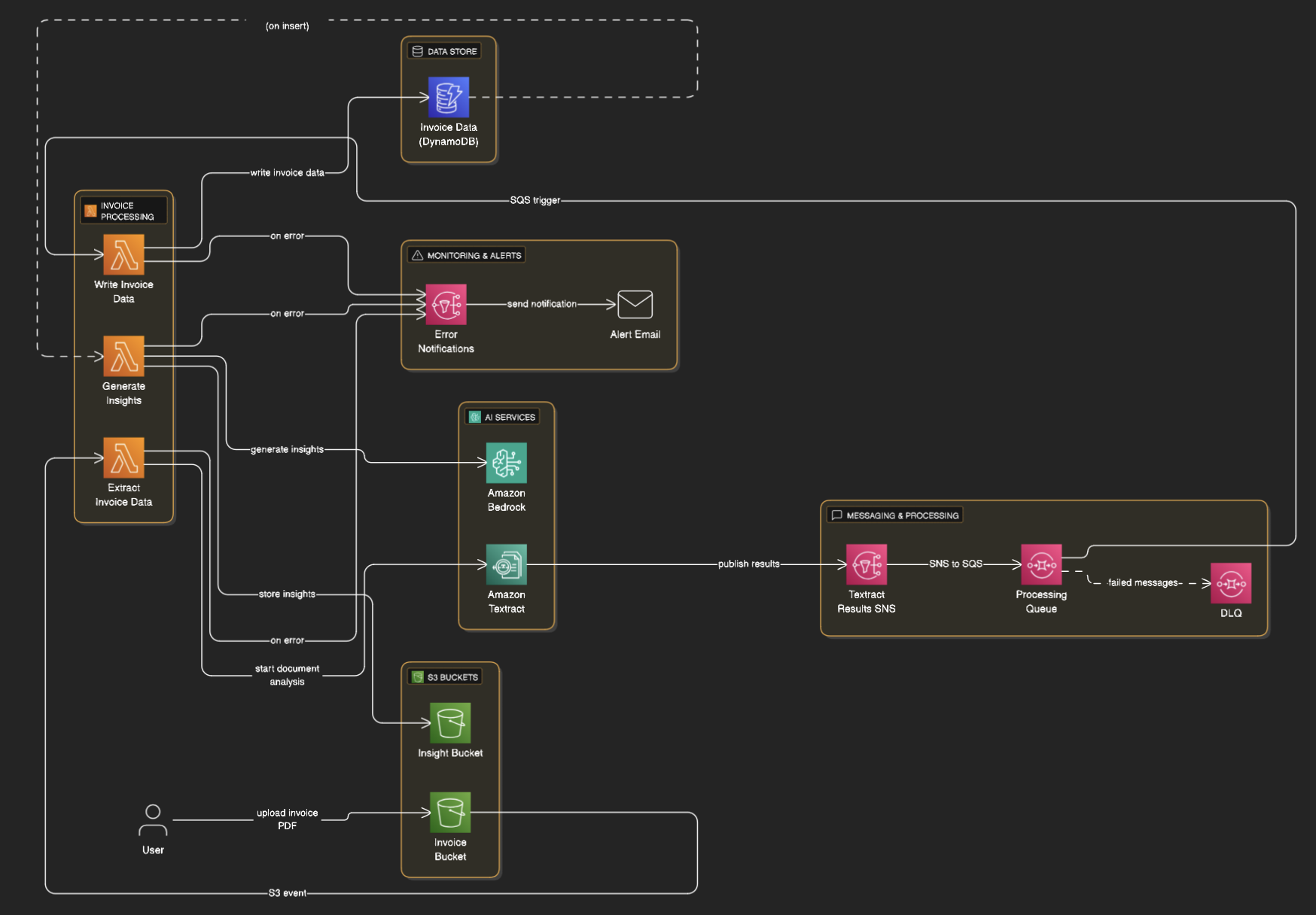
architecture
-

Example of item data in an invoice
-
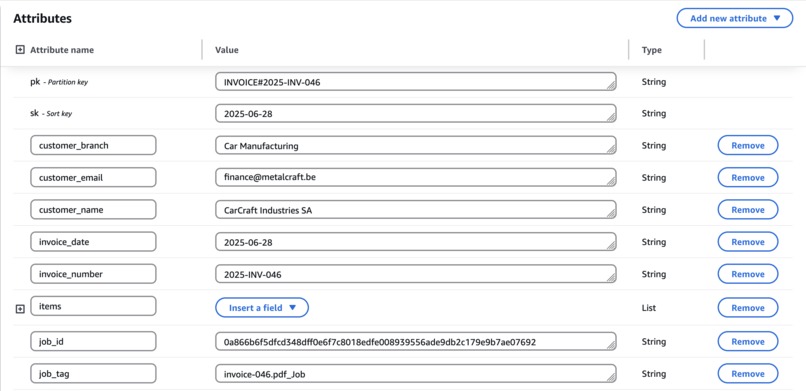
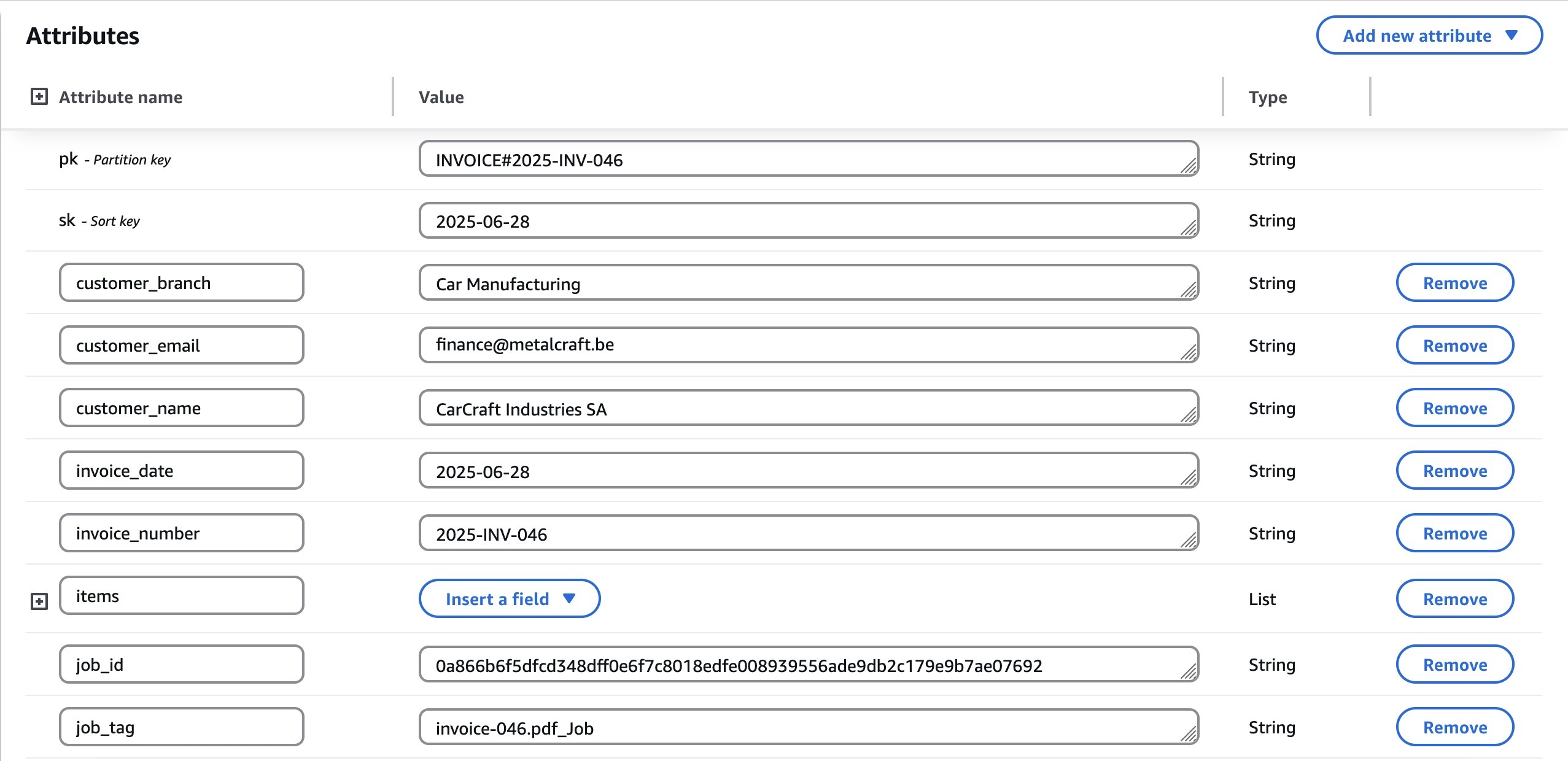
Example of invoice data
-
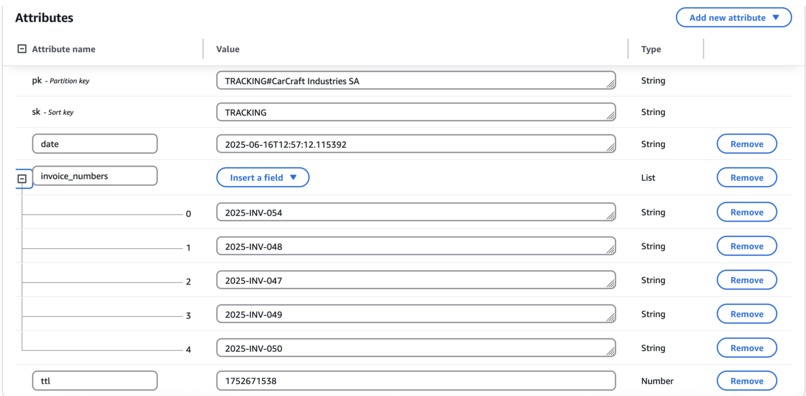
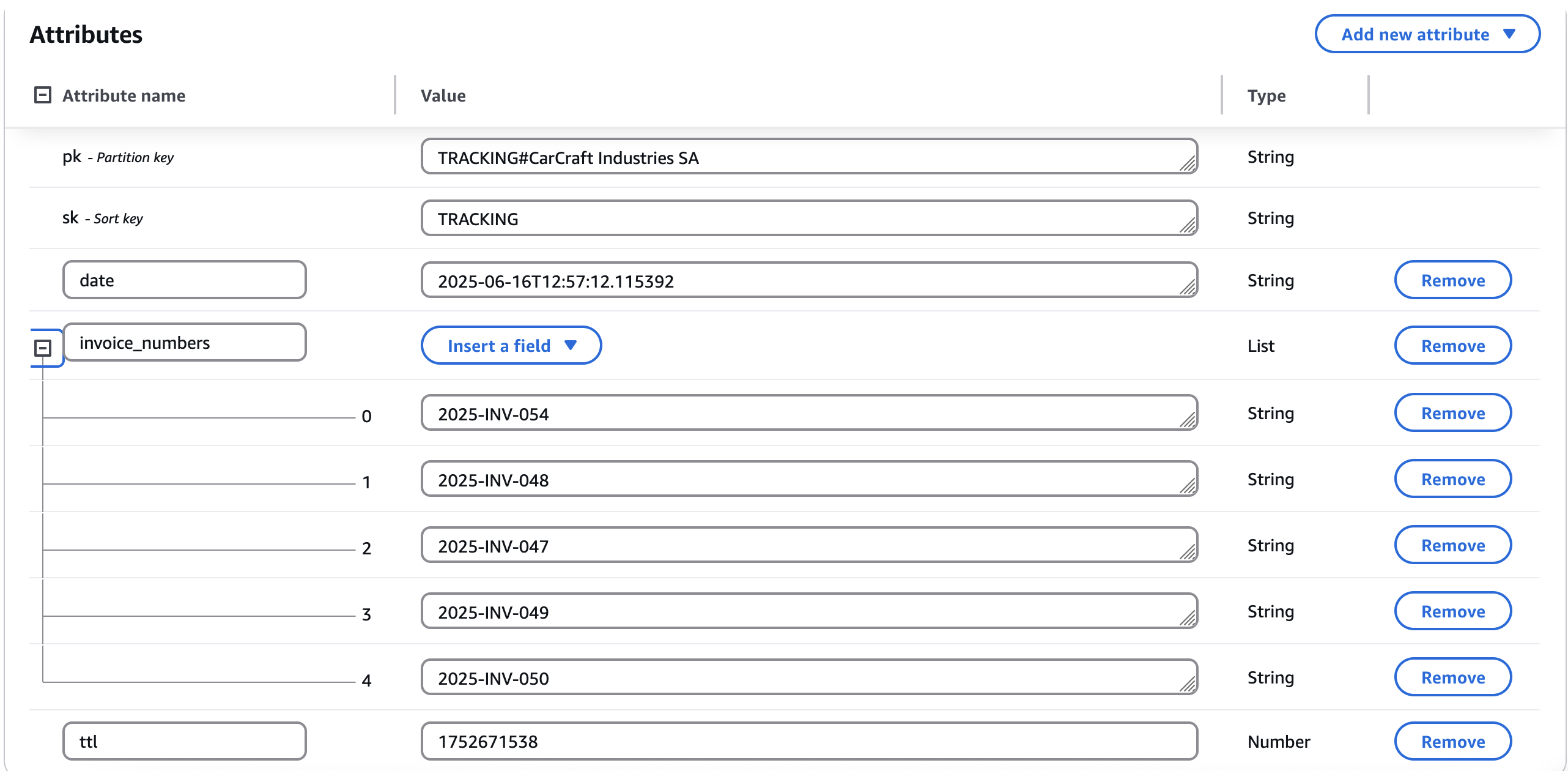
Example of tracking data
-
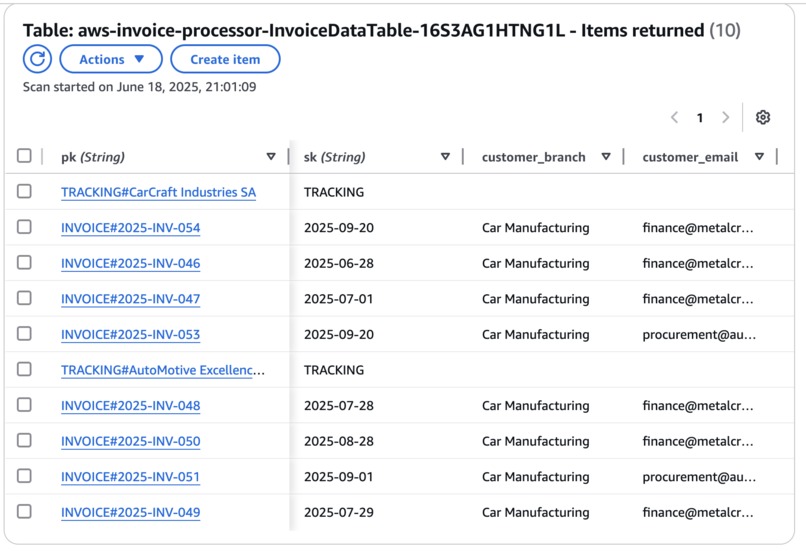
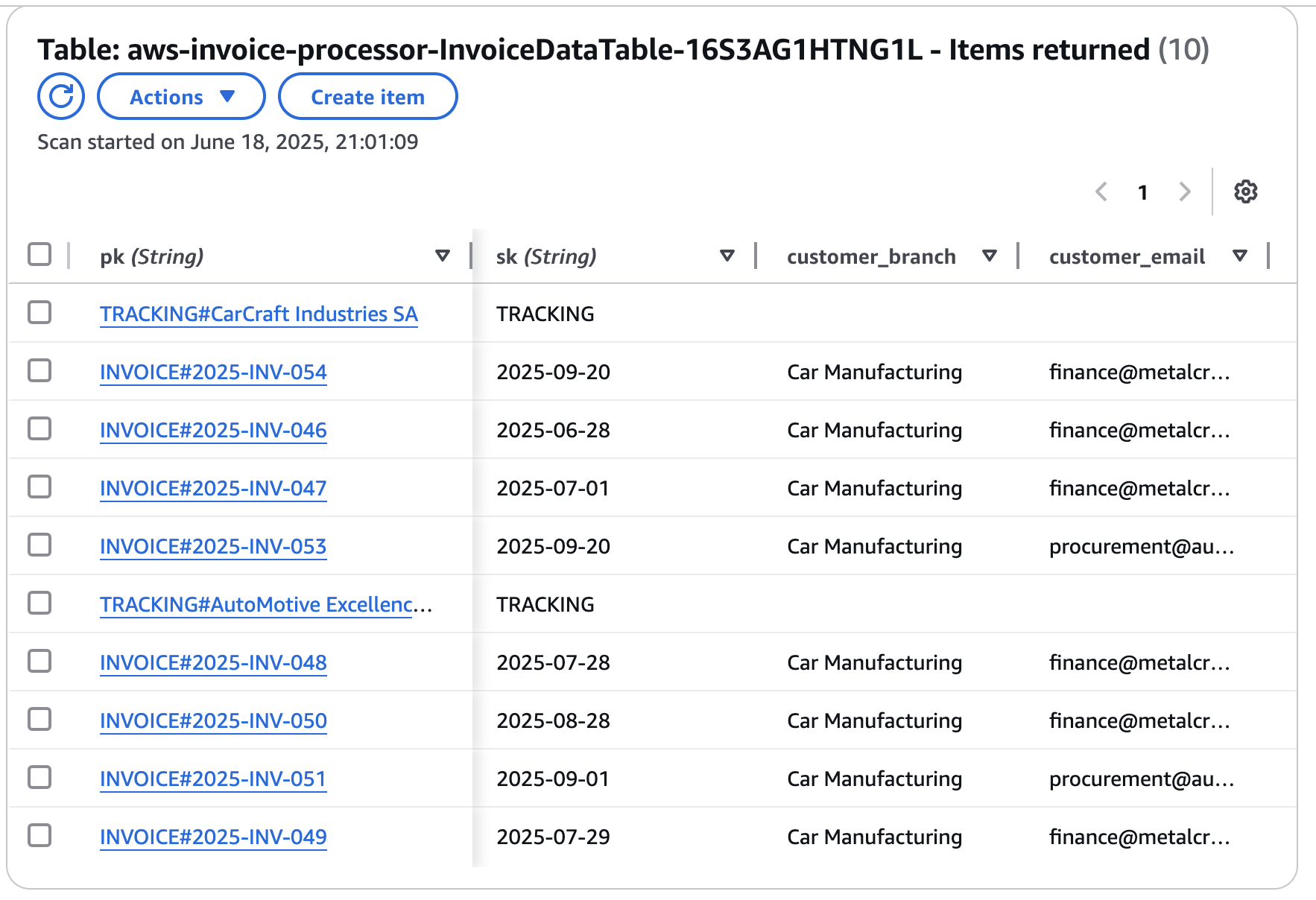
Example of data in DynamoDB (invoices and tracking)
-
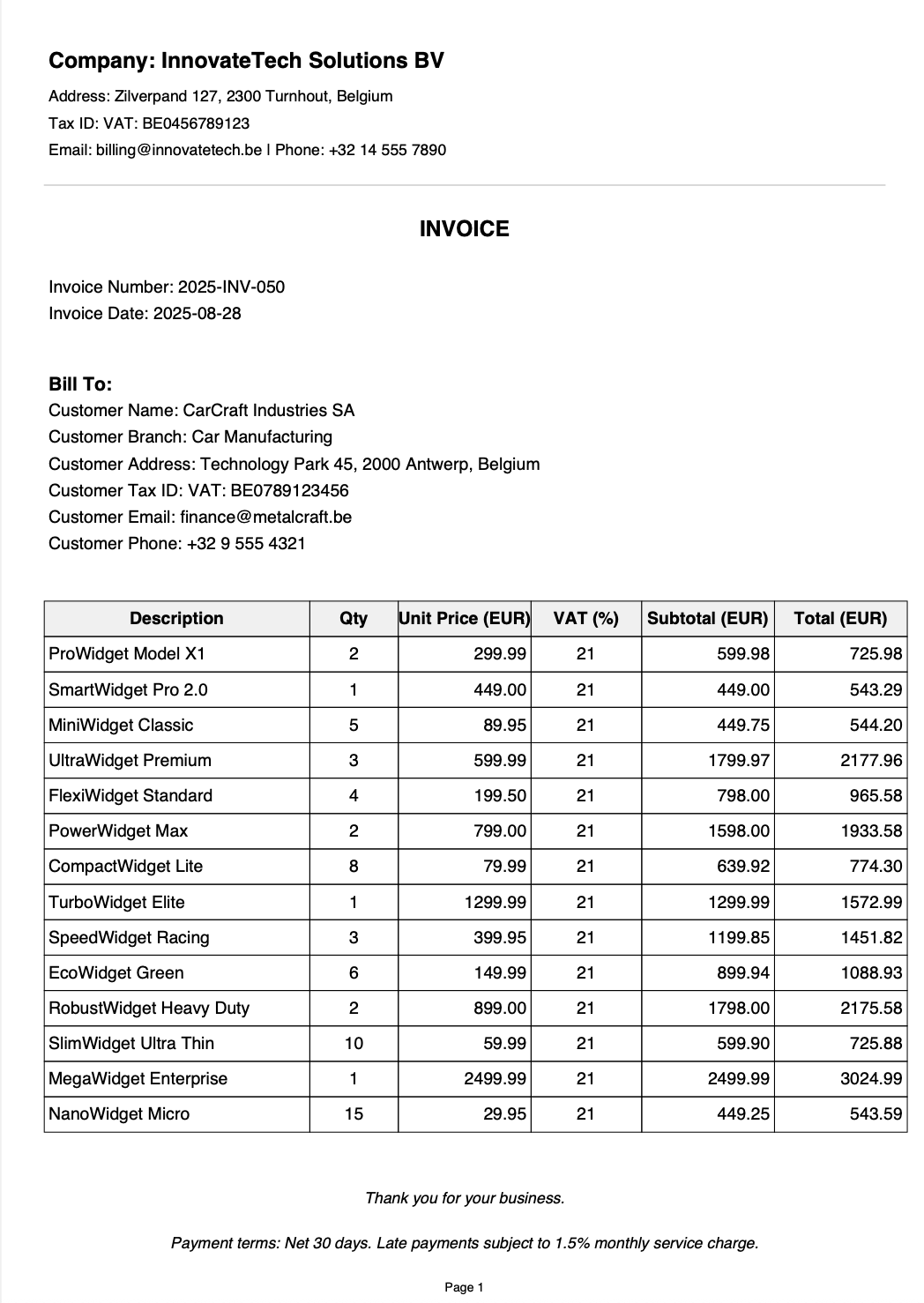
Example invoice page 1
-
Example invoice page 2
-
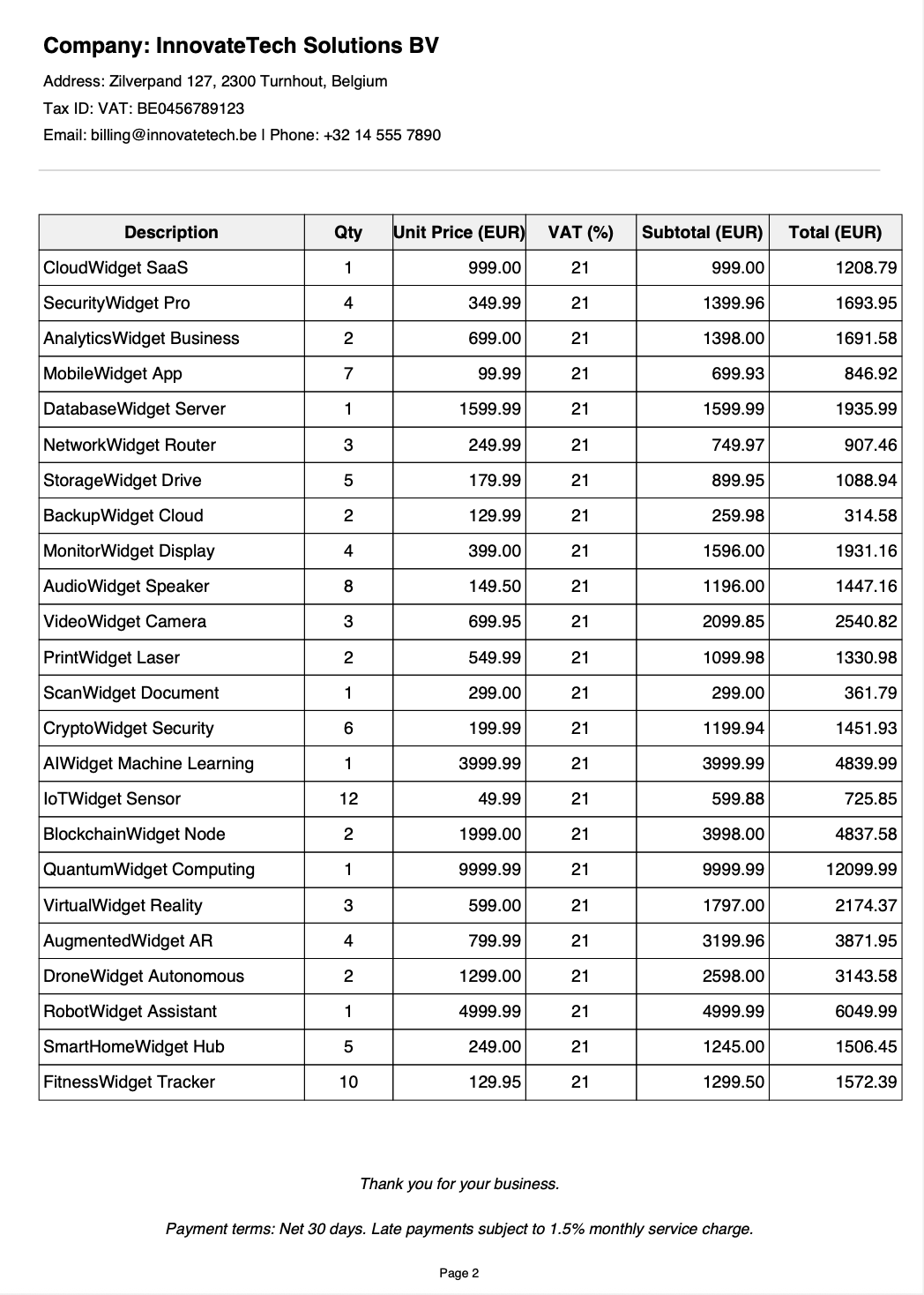
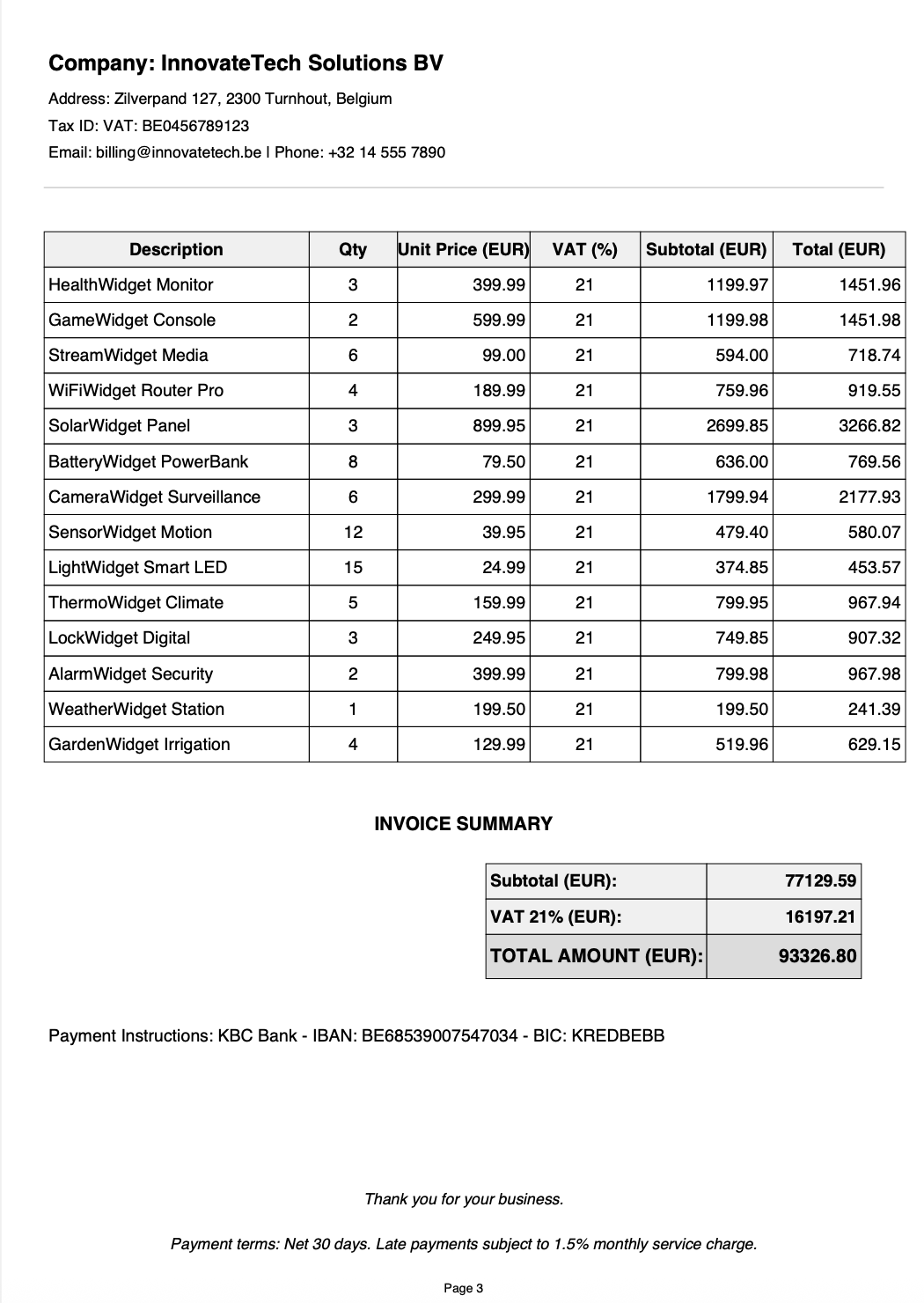
Example invoice page 3

Inspiration
AI is a hot topic right now, and since I haven’t had much hands-on experience with AI-powered AWS services in my professional work yet, I saw this as a great opportunity to explore them. I chose to integrate my Lambdas into an event-driven architecture using services like Textract and Bedrock. This led to a real-world business idea: automatically extracting deeper insights and analysis from historical invoice data from customers, and comparing it with the latest invoice.
Based on that data, businesses could receive automated feedback on how a specific customer’s purchasing behavior is evolving over time — whether they’re buying more or fewer products, what types of products they purchase, how often they place orders, and more. Since every company deals with invoices, this solution could be valuable to many organizations. It provides meaningful insights without requiring complex or large-scale data infrastructure, making it a relevant and broadly applicable use case.
What it does
The solution can be used by a company to process invoices it sends to its customers. When someone uploads a PDF invoice to an S3 bucket—for example, for Customer A—the solution extracts the data using AWS Textract and stores it in DynamoDB.
If it’s the first invoice for that customer, no insights will be generated, as there is no historical data yet. For the second and subsequent invoices, the solution generates insights based on the customer's historical data—up to the last five invoices. It will always compare the newest invoice with the four previous ones. These insights are created using Amazon Bedrock and stored in S3.
From a more technical perspective:
- Upload Invoice:
- The user uploads one or more PDF invoices from one or more customers to the S3 bucket specified in the
InvoiceBucketparameter. Old PDFs expire after 90 days.
- The user uploads one or more PDF invoices from one or more customers to the S3 bucket specified in the
- Extract Data:
- The
InvoiceTextractFunctionis triggered by the S3 upload event. - It uses AWS Textract (async) to extract data from the PDF invoice.
- Textract will read tables and forms in the PDF.
- Textract will publish the result to an SNS topic.
- An SQS queue is subscribed to the SNS topic to to reliably buffer and deliver messages to the Lambda function.
- The
- Store Data:
- The
InvoiceDataWriteris polling messages from the SQS queue. - It processes the Textract result and stores the invoice data in DynamoDB. It supports multi-page invoices. It will fail when there is missing data in the invoice. It will not fail but send a warning when a duplicate invoice is uploaded. An invoice should be unique and can not be updated.
- we make use of the Textract response parser to extract the correct data.
- The
- Generate Insights:
- The
InsightGeneratorFunctionis triggered by the DynamoDB stream (when a new invoice is added to DynamoDB). It's only triggered when invoice data is added, not when other data is inserted. - It gets the last five invoices for a customer from DynamoDB.
- It checks if the customer has at least 2 invoices for analysis.
- It tracks processed invoices to avoid duplicate analysis.
- For new customers: Creates tracking record with initial invoice numbers
- For existing customers: Compares new invoice numbers with already processed ones. If a new recent invoice is found, it will update the tracking record and generate insights.
- It uses Amazon Bedrock to generate insights for the most recent invoice compared with the 4 previous invoices and writes it to S3.
- The insights are generated for each most recent invoice for each customer.
- The
For more details about parallel processing and Edge Cases, see the README in the repository.
How we built it
See Architecture Overview above for the high-level architecture. We used AWS SAM to build the solution, which is a serverless application model that simplifies the deployment of serverless applications on AWS. All Lambda functions are written in Python and use the AWS SDK for Python (Boto3) to interact with AWS services.
We created an event-driven architecture in which a PDF upload to the InvoiceBucket triggers an S3 event. This event invokes the InvoiceTextractFunction, which starts a Textract job to extract data from the document. Once the Textract job is complete, the result is published to an SNS topic. An SQS queue subscribed to this topic buffers the message and triggers the InvoiceDataWriter, which retrieves the extracted data and stores it in DynamoDB. A DynamoDB stream monitors this table and triggers the InsightGeneratorFunction whenever new invoice data is added. This function checks whether new insights need to be generated based on data changes, and if so, it uses Bedrock to generate them and stores the results in the InsightBucket.
Challenges we ran into
The main challenge was ensuring the solution could handle multiple invoices for the same customer being uploaded simultaneously. This required careful design of the DynamoDB data model and Lambda functions to guarantee that insights are generated accurately based on the latest invoice data. A simpler approach would have been to decouple the insight generation from the event-driven flow and run it once daily using an EventBridge scheduler. However, I wanted to keep everything tightly integrated within a single event chain to deliver insights as quickly as possible.
Accomplishments that I'm proud of
I'm particularly proud of successfully integrating modern AI services (Amazon Textract and Bedrock) into a single event-driven flow, despite having limited prior experience with these technologies. The solution demonstrates how AI can add real business value through automated document processing and intelligent analysis.
The focus on efficient data processing stands out - implementing batch processing for multiple records within a single Lambda execution, and using AWS Powertools' batch processing capabilities to handle partial failures gracefully. This, combined with the fact that every function is idempotent, makes the solution efficient and scalable.
From a non-technical perspective, I’m proud to have built something that could be very useful for many companies—without requiring them to rely on large volumes of data or special sources. With just a few minimal adjustments based on a company's specific invoice data, this solution should be easy to get up and running.
What I learned
This project led to valuable new learnings about:
- AWS Powertools' batch processing capabilities.
- Using Amazon Bedrock for generating insights from structured data.
- The Textract Response Parser library for robust document analysis.
- Filtering DynamoDB Stream data at the IaC level rather than in Lambda code.
These technical choices make the solution both scalable and maintainable while keeping the code clean and focused on business logic.
What's next for aws-invoice-processor
The solution can be extended with additional features:
- Visualize the data in a dashboard using Amazon QuickSight.
- Improve CloudWatch monitoring (very basic for now).
- Make the solution smarter:
- An example is to not only use historical customer-specific invoice data to generate insights, but you can extend this by comparing data from other customers withing the same industry sector (= same
customer_branchattribute in DynamoDB). Create a GSI on thecustomer_branchin DynamoDB and query this in theInsightGeneratorLambda function. Use this data to generate and compare insights for a specific customer with other customers within the same industry sector. This way you can inform the customer that other customers within the same sector frequently purchase product X.
- An example is to not only use historical customer-specific invoice data to generate insights, but you can extend this by comparing data from other customers withing the same industry sector (= same
- Make use of Lambda Context to check how long before the Lambda times out to improve processing batches. For now we limit on max 5 records per batch so we don't run into timeout issues during one Lambda execution.
Built With
- aws-sam
- bedrock
- dynamodb
- lambda
- lambda-powertools
- python
- s3
- sns
- sqs
- textract


Log in or sign up for Devpost to join the conversation.