Inspiration
Before now, I had been working as a Software Engineer building applications using Java, Python, and Node.js. By the last quarter of 2023, I began looking into transitioning to cloud development to advance my career. During my research, I discovered AWS services and quickly got drawn to Serverless technologies.
Why Serverless? I noticed that very few developers and engineers in Africa, especially Nigeria, are using Serverless architecture and many companies are yet to adopt Serverless. It felt like a great opportunity to explore a less saturated space with strong career potential.
By early 2024, I made the decision to focus fully on Serverless, learning on my own, enrolling in courses, and building projects to reinforce my understanding. Along the way, I became curious about how I could get only Serverless-related news and updates from AWS, especially after noticing how some significant updates from re:Invent and others (like the End of Support for Node.js 18.x us-east-1 or JSONata support in Step Functions) didn’t get my attention.
That curiosity sparked the idea for this project: a system that helps users Stay Updated On AWS news. It also served as a way to go deeper into several AWS services by building a practical, end-to-end system.
What it does
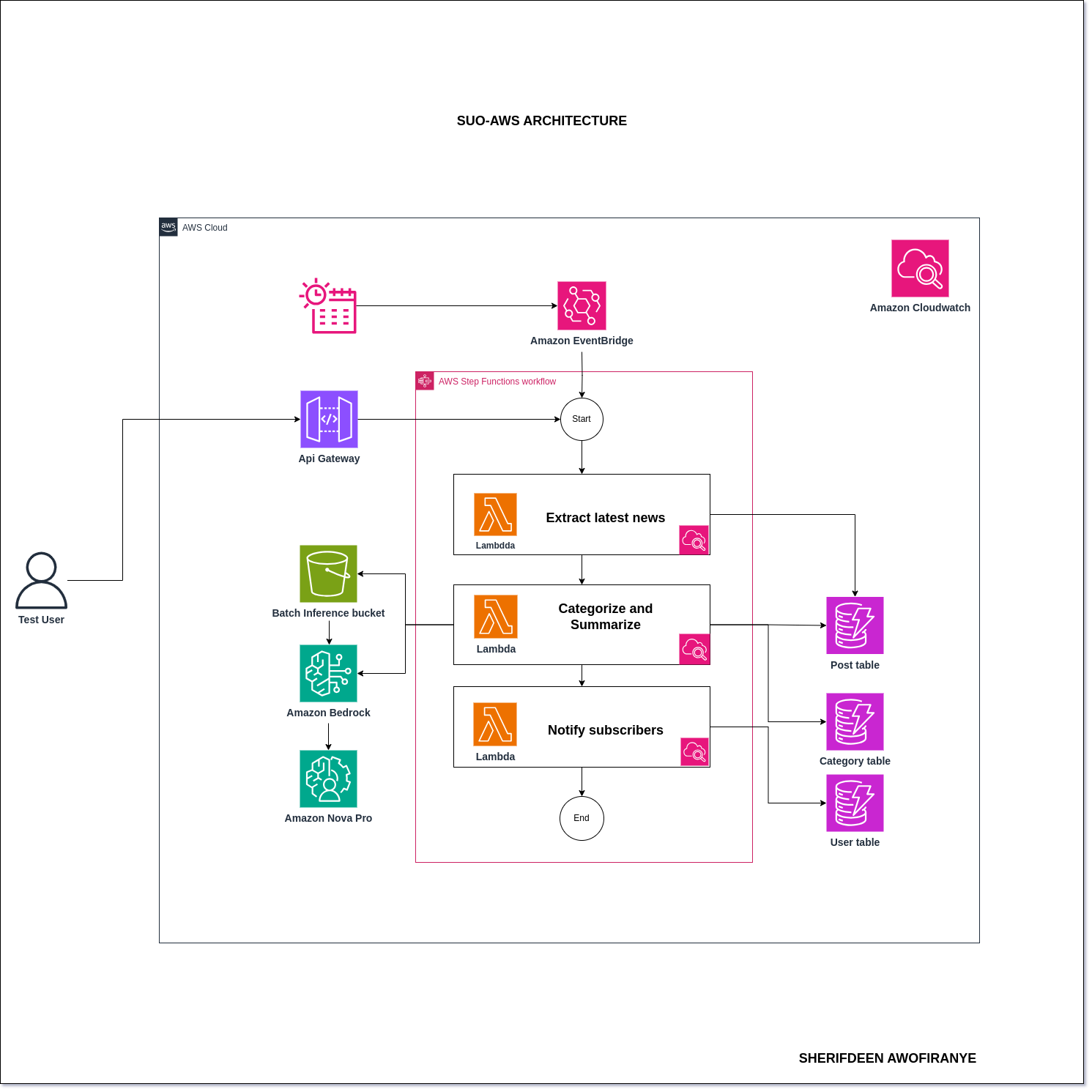
The project is a fully serverless news delivery system that keeps users updated with the latest AWS news based on their interests.
Users subscribe by selecting their preferred news categories (e.g., Serverless, AI, Databases). Every morning, the system automatically scrapes the latest news from official AWS blog sources, categorizes the updates, and sends personalized email digests to each subscriber with news relevant to their chosen categories.
The workflow is fully automated using AWS Step Functions, and it is triggered daily via an EventBridge cron schedule. For testing purposes, there’s also a manual API endpoint that can trigger the workflow on demand while preventing duplicate data extraction.
In short, the system ensures that users stay informed with timely, category-specific AWS news — without having to manually browse through blogs or filter out irrelevant updates.
How we built it
The system has four main parts:
User Subscription Users subscribe by selecting the news categories they’re interested in. I built a Node.js Lambda function to handle this, exposed via Lambda Function URL since it's a direct call inside my code base and also enabled CORS. I avoided using validation plugins to reduce package size and instead wrote custom input validation. User data (name, email, categories) is stored in a DynamoDB table.
News Extraction I built a Python-based Lambda function that uses Playwright to scrape AWS blog news. The function is containerized using Docker, pushed to ECR, and deployed with AWS CLI scripts. The extracted news is then stored in another DynamoDB table.
Categorization & Summarization Initially, I wanted to use Amazon Bedrock with Nova Pro or Claude to auto-categorize and summarize the news but I got into an account permission roadblock that requires raising a ticket, which i did and yet to be solved. My goal for wanting to use AI was to categorize updates into meaningful tags like "Serverless" rather than generic ones like "Compute" because a compute news can be about an EC2 update which a serverless subscriber don't really care about and we would want an Amazon Aurora DSQL news in Serverless instead of just storage. And using AI to summarize news in short, insightful sentences. However, I faced account permissions and regional restrictions that blocked Bedrock/Nova Pro usage. As a workaround, I categorized news based on the URL resource prefix and extracted titles and descriptions directly from the news articles.
Notification System A Node.js Lambda function handles notifications using
nodemailerwith Gmail SMTP. It fetches user preferences and sends them only the relevant news updates.
To orchestrate these functions, I used AWS Step Functions. The workflow handles each stage as state, from scraping, to categorizing and summarizing, and finally to email notification.
The system sends the previous day’s news to subscribed users every morning. I implemented this using a cron-based EventBridge scheduler that triggers the startExecution state in the Step Function daily at 7:00 AM UTC+1. And I also used CloudWatch extensively for logs and monitoring.
For hackathon Judges testing purposes, I also set up an API Gateway endpoint to allow manual triggering of the Step Function. Within my scraping code, I perform a check to see if the workflow has already run that day and if news has already been extracted, to avoid populating the database with duplicate content.
Challenges we ran into
Playwright on Lambda Running Playwright in a Lambda environment was tough. I encountered some issues of some missing dependencies caused Lambda system-level dependencies and headless browser limitations. After a lot of research and trial-and-error, I managed to bundle everything needed using Docker and containerised it in Lambda.
Amazon Bedrock & Nova Pro My original plan was to use Nova Act for scraping and Nova Pro or Claude for summarization and categorization. But I hit some limitations:
- Nova Act was in review and not available in my region.
- Bedrock returned rate-limit errors for multiple simultaneous requests. I found batch-inference as a workaround, but.
- Batch inference required IAM CreateModelInvocationJob authorization that my account didn’t have (support ticket needed).
I had to pivot to a simpler, rule-based implementation, which, while not perfect; still met the project's goal anyways.
- AWS SAM Build Issues AWS SAM gave me trouble when building functions with different runtimes (Node.js and Python). My building keeps stucking and didn’t have enough time to dig deep. As a workaround, I deployed one function via the AWS Console and the other using AWS SAM.
Accomplishments that we're proud of
End-to-End Serverless Implementation: Successfully built a fully functional, event-driven system using only AWS Serverless services from data ingestion to processing and delivery without relying on traditional compute infrastructure.
Playwright on AWS Lambda: Overcame the technical challenge of running Playwright in a Lambda environment. After extensive debugging and packaging, I was able to containerize it using Docker and deploy it successfully using ECR and AWS CLI.
Custom Categorization Without AI Models: Despite access restrictions to Amazon Bedrock models like Claude and Nova Pro, I designed a custom rule-based categorization system that accurately tags AWS news based on content and URL structure.
Cost Optimization and Cold Start Reduction: Implemented best practices like using Lambda Function URLs for internal APIs and avoided unnecessary plugins to reduce artifact size, resulting in faster cold starts and lower execution cost.
Seamless Workflow Orchestration: Leveraged AWS Step Functions and EventBridge to build a reliable and automated daily workflow, ensuring timely delivery of AWS updates to users.
Fallback Planning and Resilience: Where tools or services failed (e.g., Bedrock model access or SAM build issues), alternative solutions were implemented without blocking the project, showing adaptability and commitment to delivering results.
What we learned
I learned a lot from this project, not just how to build with services like Lambda, API Gateway, DynamoDB, Step Functions, and more but also about resilience. I had to solve problems creatively, manage costs effectively (e.g., using Lambda Function URLs for internal APIs instead of API Gateway), and avoid overcomplicating designs.
It also taught me to optimize for performance, for instance, avoiding unnecessary dependencies and plugins to keep Lambda packages small and reduce cold start times.
What's next for SUO-AWS
If I’m eventually granted the necessary IAM permissions, I plan to implement AI-based summarization and categorization using Amazon Bedrock. This will allow for more intelligent and context-aware classification of AWS news beyond basic rule-based tagging.
I also intend to build an admin dashboard to monitor user engagement and system activity in real-time, providing better visibility into subscriptions, news delivery metrics, and system health.
Currently, Playwright works well for scraping, but execution time averages around 20 seconds, depending on how many updates AWS publishes. Once Amazon Nova Act becomes fully available, I plan to compare its performance and efficiency with the current implementation and potentially switch over.
Another key improvement on the roadmap is integrating Amazon SNS for failure notifications. In the event of any system errors, I want to receive immediate alerts via email to ensure faster issue resolution. Use Systems Manager Parameter Store to safely store keys.
Beyond technical improvements, I plan to promote SUO-AWS so that other developers and curious minds can benefit from staying informed about AWS services, just like I intended from the start.
Although this project was built out of passion, it may eventually incur operational costs. When that happens, I’ll consider either monetizing it by introducing marketable features or seeking community support through donations to keep it sustainable.
Built With
- amazon-dynamodb
- amazon-web-services
- api-gateway
- aws-sam
- bedrock
- cli
- cloudwatch
- docker
- ecr
- eventbridge
- github
- gmail
- iam
- lambda
- nextjs
- node.js
- nodemailer
- playwright
- python
- s3
- step-functions
- vercel

Log in or sign up for Devpost to join the conversation.