-
-

Splash Screen
-
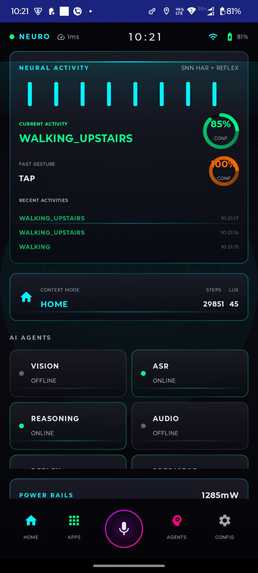
SNN based SLM detecting the Activity Gesture
-
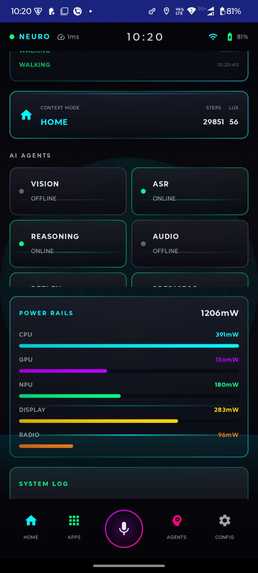
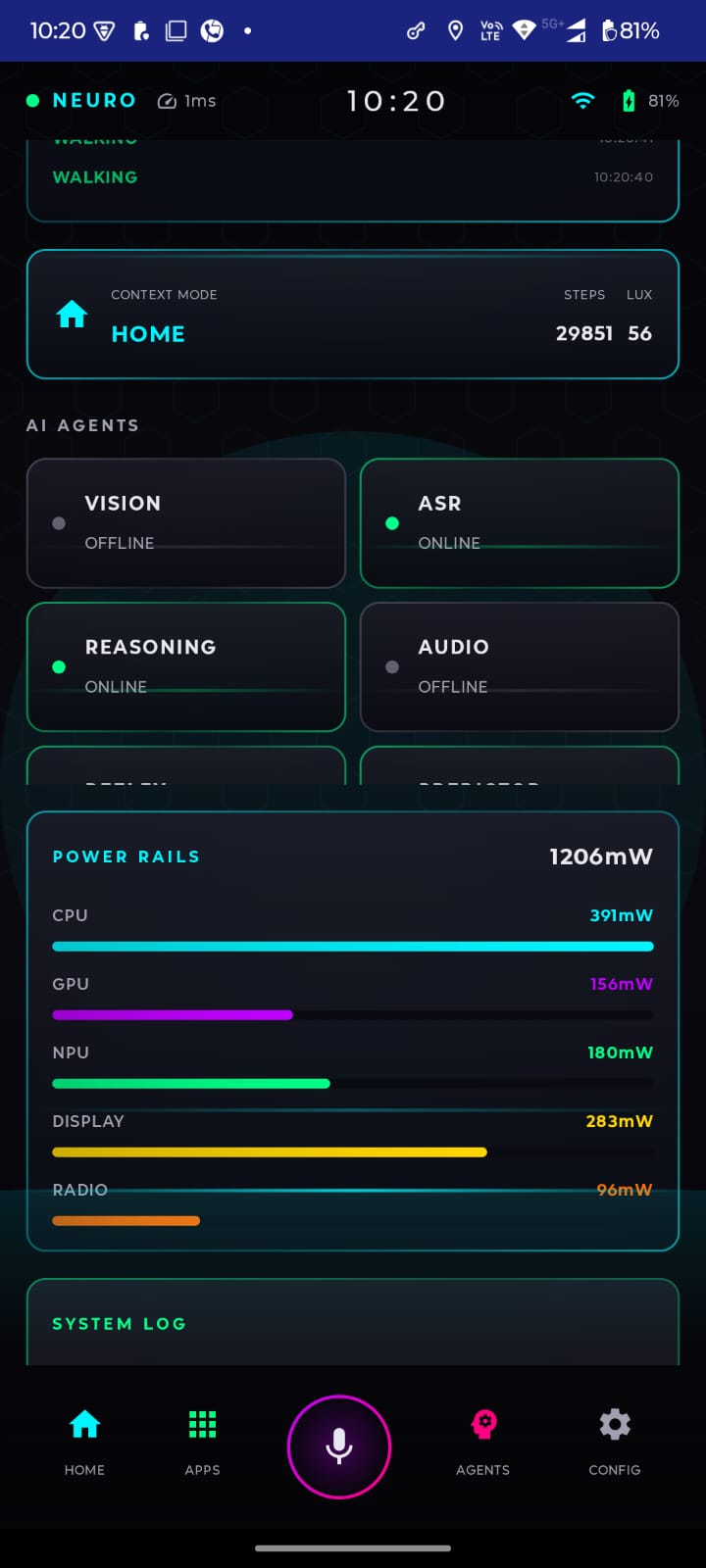
Showing Power Rails using ODPM
-

Suggesting the Apps with the Real time 3 days based prediction
-
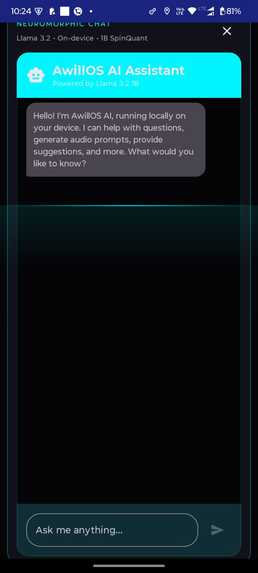
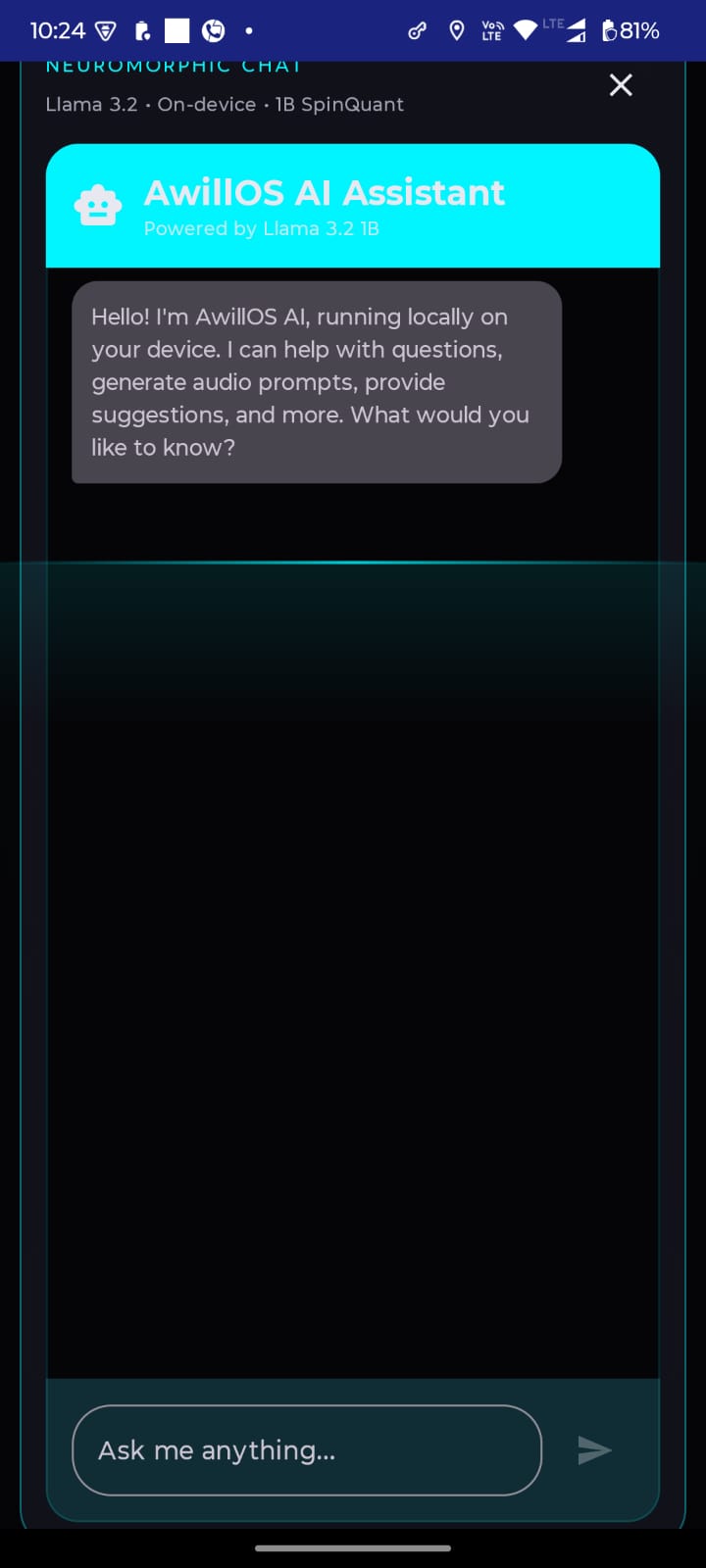
Backend AwillVoiceAssistant testing


Inspiration & Vision
We started from a simple, slightly annoying question:
Why does a phone that already has powerful Arm CPUs still need the cloud to feel “smart”?
In 2025, the AI spotlight is dominated by:
- Nvidia GPUs and CUDA
- Proprietary NPUs from Apple and Qualcomm
- Fast-rising RISC-V accelerators
Meanwhile, Arm powers billions of devices, yet most of that silicon is treated as a host for someone else’s AI workloads rather than a primary AI engine.
We saw a clear gap:
- Mobile AI is fragmented across vendor-specific NPUs.
- Cloud assistants are slow, dependent on connectivity, and not truly private.
- Arm risks being overshadowed unless it can host brain-like, always-on intelligence directly on its CPUs.
So we imagined something different:
“A biological nervous system inside every Arm device.”
A phone that learns like a brain, stays private like a diary, and reacts in real time like a reflex.
This vision became AwillOS / Cortex-N — an agentic, neuromorphic, contextual AI layer living on top of Android, running entirely on Arm Cortex-A CPUs.
- No cloud.
- No proprietary NPU lock-in.
- Just smart software transforming commodity Arm CPUs into a neuromorphic AI fabric.
About the Project
We set out to prove a phone could run a full “cognitive loop” entirely offline:
wake word → ASR → local LLM → TTS → sensor-aware actions
—without any cloud help.
Inspiration came from:
- privacy-first assistants,
- wearables that must survive bad connectivity, and
- a desire to blend classical sensing (IMU/vision) with modern generative models in one stack.
What We Built
We built an Android app (Jetpack Compose + classic views) that orchestrates multiple on-device AI agents:
- Wake word:
OpenWakeWord(ONNX) - Speech-to-text (ASR):
Whisper-smallINT8 (ONNX) - Local LLM:
Llama 3.2via ExecuTorch.pte - TTS:
Piper(ONNX) - Embeddings:
MiniLMINT8 (ONNX) - Gesture/activity SNN: custom C++/ONNX spiking model
- AudioGen: TensorFlow Lite for creative sound generation
Feature modules include:
- Vision agent (YOLO via ONNX)
- ASR agent
- Predictor/context agent (Room + DataStore + WorkManager + Play Services Location)
- Telemetry overlay
aura-runtimefor centralized task routing
Native layers are implemented via NDK/CMake (C++17, NEON/SME2 paths) for:
- SNN kernels
- AudioGen JNI bridge
We use:
- A unified ONNX Runtime 1.17.1 across modules
- ExecuTorch AAR for on-device LLM inference
How We Built It
Android stack:
- Gradle Kotlin DSL + AGP 8.13.1
- Kotlin 1.9.22
- Jetpack Compose BOM for UI
- Room / WorkManager / DataStore for state
- Timber + Perfetto for telemetry
- Gradle Kotlin DSL + AGP 8.13.1
Model packaging & export:
- All models bundled under
assets/to avoid network fetches - Export scripts in Python using:
- PyTorch + Transformers
- ONNX Runtime quantization for Whisper
- ExecuTorch exporter for Llama
- All models bundled under
Performance budgeting:
We budgeted latency per stage to keep real-time loops responsive. For camera/gesture loops, we aimed for:
[ \sum_i t_i \leq 33\,\text{ms} ]
to maintain roughly 30 FPS.
This drove us toward INT8 quantization and use of ARMv8.2 dotprod for YOLO and Whisper.
- Native & build config:
- CMake projects for SNN and AudioGen
- Tuned flags:
-march=armv8.2-a+fp16+dotprod, optional SME2 - JNI glue for SNN and AudioGen
- TensorFlow Lite JNI integrated into native builds for AudioGen
What We Learned
- A single, unified runtime version (ONNX Runtime 1.17.1) dramatically reduces JNI/provider conflicts; dependency drift was a hidden cost.
- ExecuTorch is viable for mid-size LLMs on mobile when:
- weights are pre-quantized, and
- context windows are small.
Memory layout mattered more than raw FLOPs.
- Quantization and operator availability drive design:
- Some transforms required patching export graphs
- We had to stay within supported opsets (≤ 17).
- Sensor fusion for context (IMU + location + foreground app) benefits from small SNNs:
- Tiny spiking models can add meaningful intent signals without heavy compute.
Challenges We Faced
Build bloat & disk pressure:
- 3.1 GB APK with 2.7 GB of models.
- Required disabling redundant copy tasks and aggressively stripping native libs.
API-level landmines:
- APIs like thermal status and
SOC_MODELvary across devices. - Needed guarded code paths to keep minSdk 26 devices working reliably.
- APIs like thermal status and
JNI/provider conflicts:
- Multiple modules initially pulled different ORT/TFLite versions.
- Solved by centralizing versions in
gradle.propertiesand sharing runtime sessions via DI.
Native build flakiness:
- NEON/SME2 flags and mixed ABIs caused subtle issues.
- Resolved with consistent NDK r27b and CMake 3.22.1 configs.
AudioGen integration:
- Full TFLite path clashed with symbol availability.
- We shipped a simplified synthesis path while keeping models bundled for future enablement.
Why It Matters
- Demonstrates a privacy-preserving assistant that runs the full speech/vision/context loop offline, ideal for edge devices and connectivity-challenged environments.
- Provides a template for mixing heterogeneous ML runtimes:
- ExecuTorch
- ONNX Runtime
- TensorFlow Lite
- ExecuTorch
under one Android app with modular agents and native accelerations—a practical recipe for next-generation on-device AI on Arm.


Log in or sign up for Devpost to join the conversation.