-
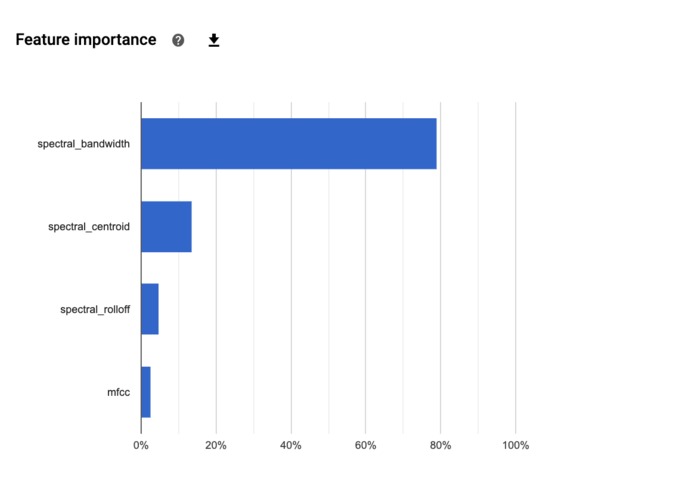
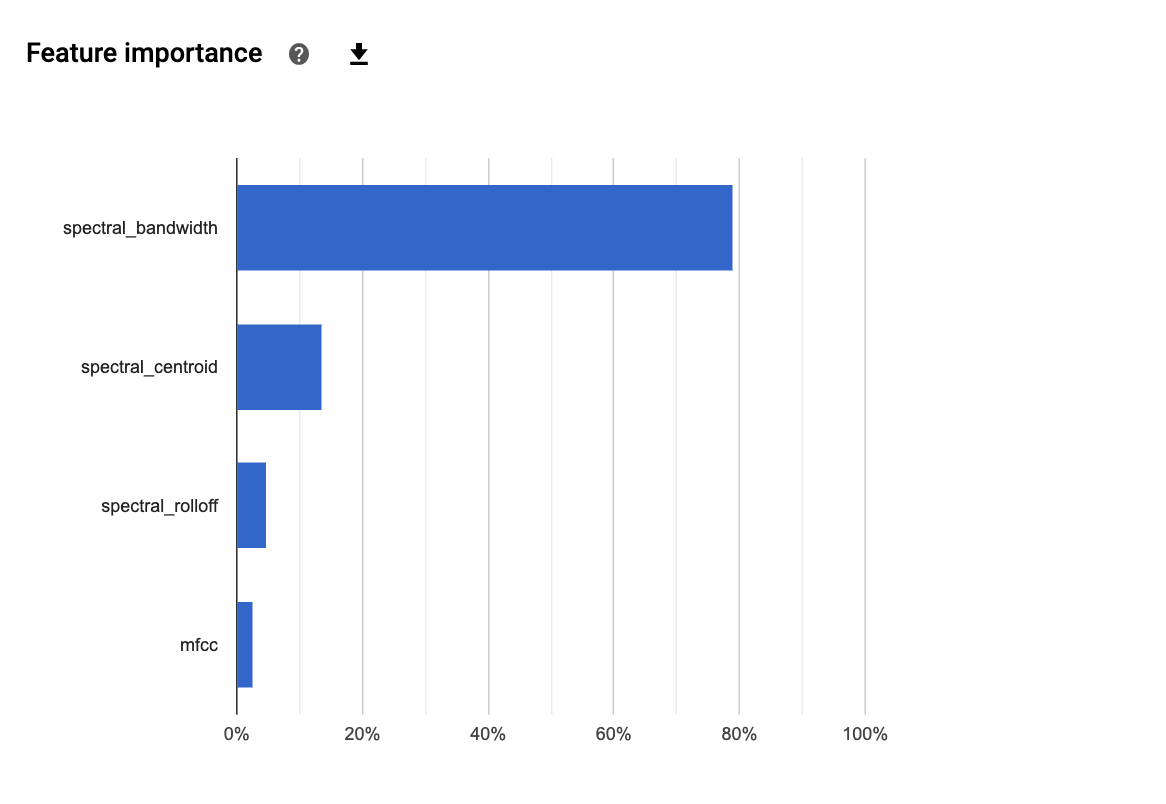
Feature Engineering
-

Confusion Matrix
-
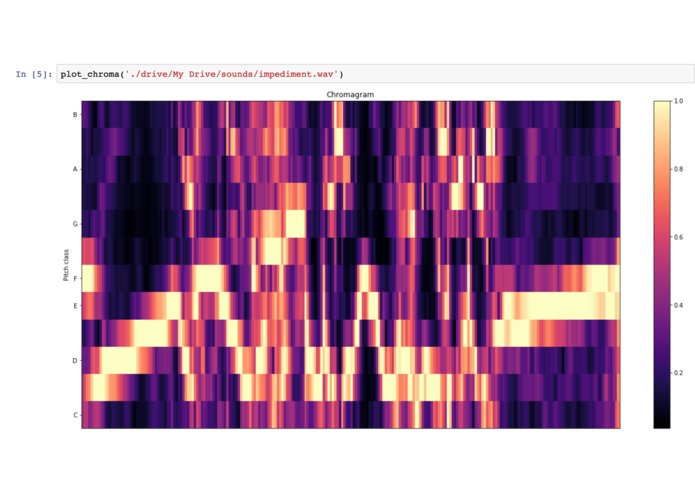
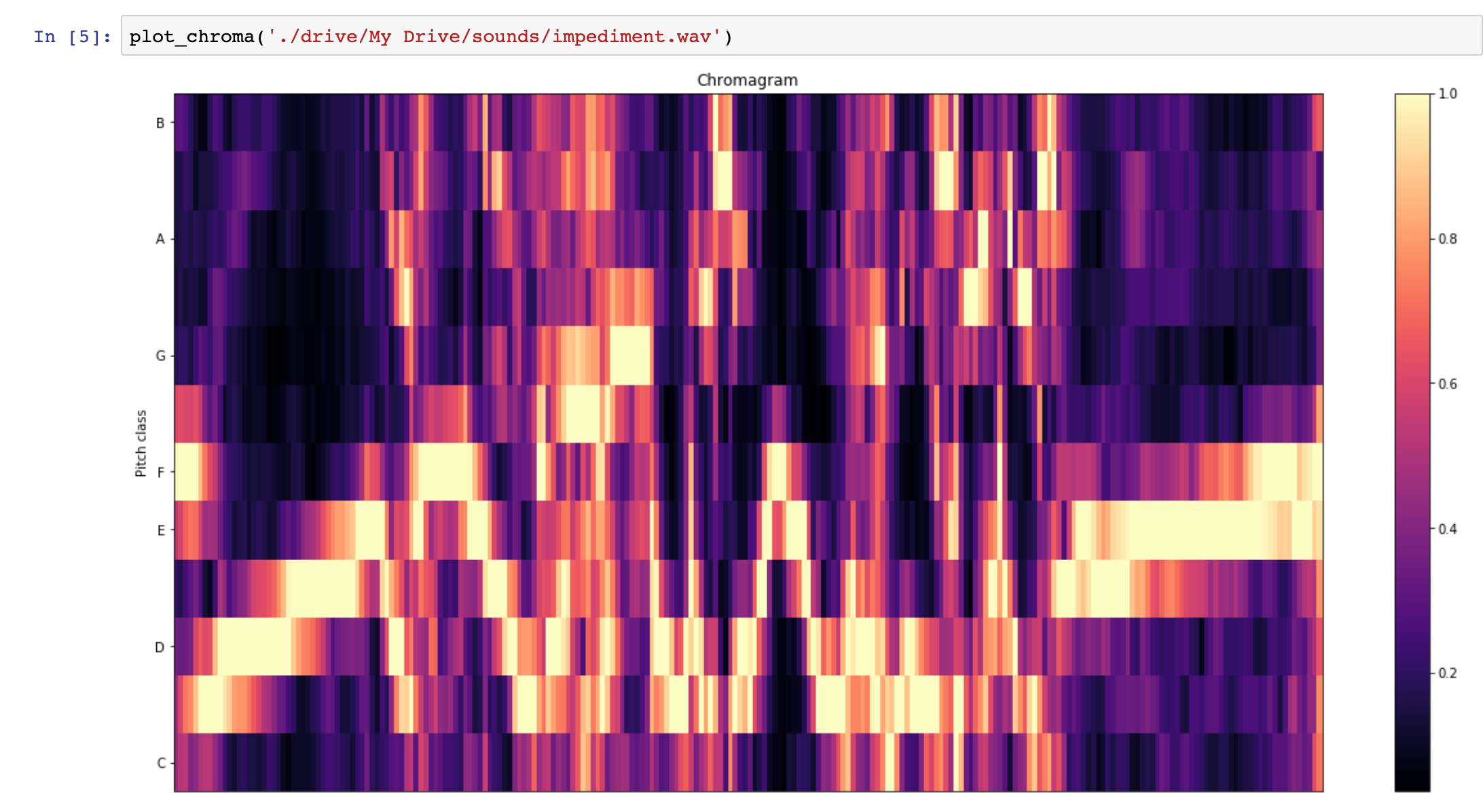
Spectral Decomposition of a user's voice suffering from speech impediment
-
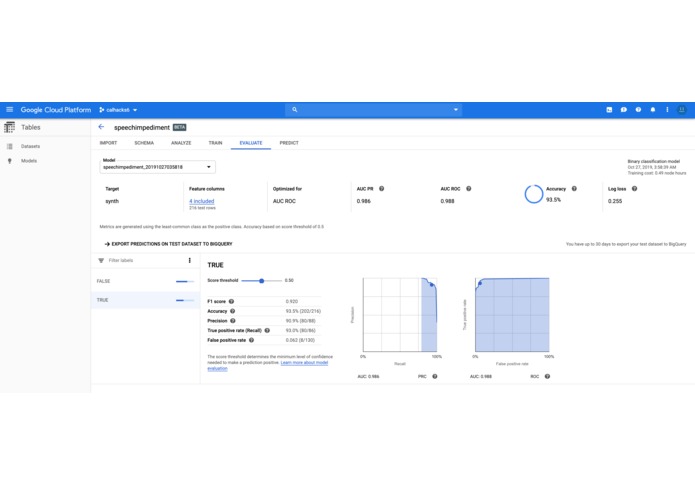
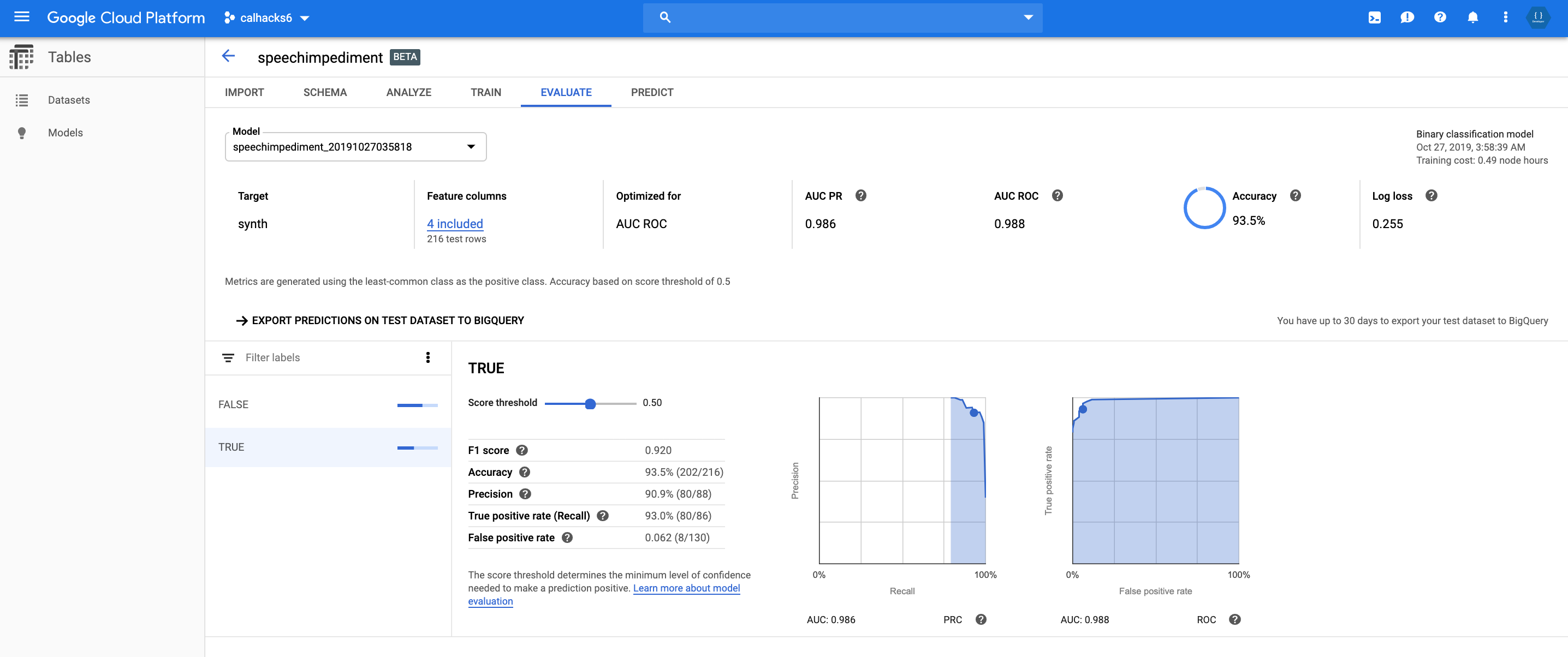
AutoML RUC
-
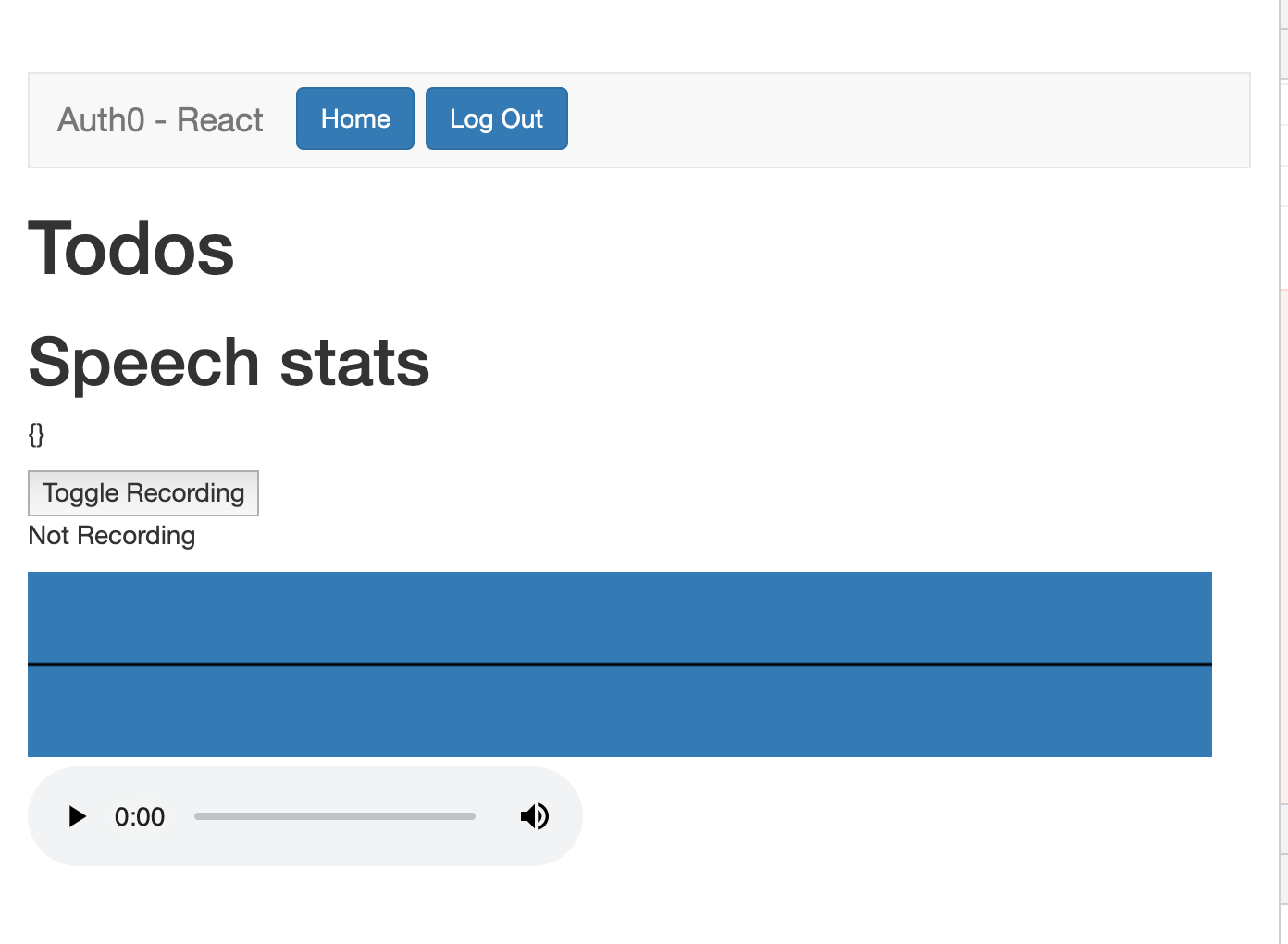
Basic Layout
-
Signup page

Inspiration
Approximately 7.5 million people in the United States have trouble using their voices. Source Speech Therapy is often hard to find, expensive and subjective. Millions suffer over many years by speech impediments either caused by stroke or acquired via birth such as stutter.
"Spasmodic dysphonia (a voice disorder caused by involuntary movements of one or more muscles of the larynx or voice box) can affect anyone. The first signs of this disorder are found most often in individuals between 30 and 50 years of age. More women appear to be affected by spasmodic dysphonia than men." Source
For patients not covered by health insurance, speech therapy typically costs $200-$250 for an initial assessment, then about $100 to almost $250 per hour. Source Speech therapy can easily be over 2 years causing significant levels of money being spent.
Bringing affordable speech impediment diagnosis and therapy will democratize this common problem and give access to low cost therapy to everyone. It'll also allow users to track their speech "scores" over time to catch any relapses and help doctors to check improvements.
What it does
A simple frontend app records your voice and posts it to a backend app. The app runs multiple signal processing tasks such as spectral rolloff, Mel-frequency cepstral coefficients and centroid computation. These scores are then fed into a machine learning algorithm trained on a dataset of speech impediment audio recordings and their synthesized versions. The backend app also uses Google's Speech to Text to transcribe the audio and Text To Speech to get a machine benchmark for voice. A person's voice metrics are gauged against the synthetic voice that's generated by the combination of Google Speech to Text and Google Text To Speech.
These benchmarks form the basis of an ML classifying model that returns back the certainty of a speech impairment. These metrics are also surfaced to the user to allow them to track their speech therapy over time.
How I built it
- Google Cloud AutoML
- GCP Speech to Text and Text to Speech apis
- Hasura GraphQL
- React
- Pandas and Principal Component Analysis analysis using scikit-learn.
- Auth0 for Google SSO
Challenges I ran into
- Finding the dataset. I had to scrape through research blogs to find a speech impediment dataset.
- Data cleaning: Audio files come in different formats and a significant time went to converting audio files from webm to wav to lossless codecs.
- Feature Engineering: There are many ways to run audio signal processing but I needed to find those that gave the largest classifier accuracy. I used PCA to pick the top 4 audio processing functions.
Accomplishments that I'm proud of
- Developed an end to end ML pipeline!
- Worked on healthcare and tech for social good.
What I learned
- Feature Engineering
- ML data pipeline setup
What's next for AwaazApp
- Better classification scores
- Better UX to track speech therapy
Built With
- automl
- google-cloud
- graphql
- javascript
- numpy
- pandas
- python
- react
- sklearn


Log in or sign up for Devpost to join the conversation.