-
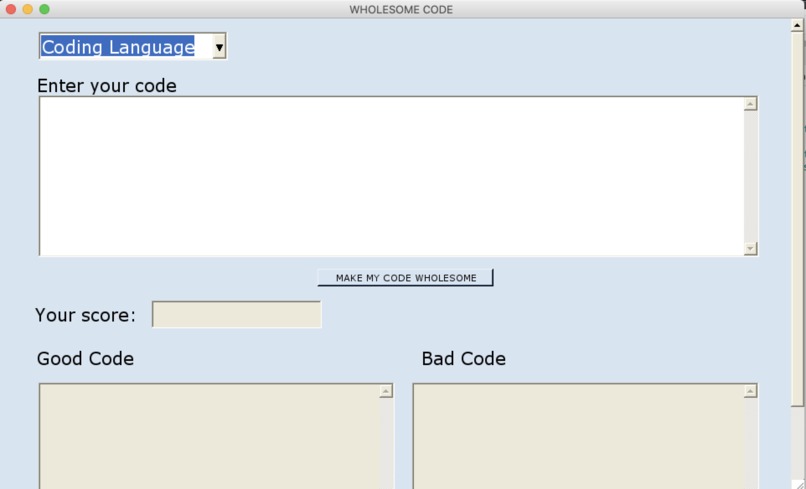
The main screen
-
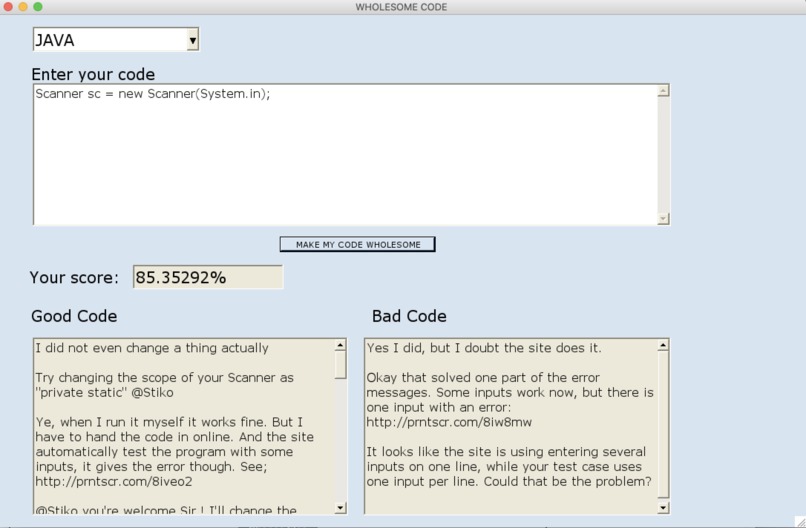
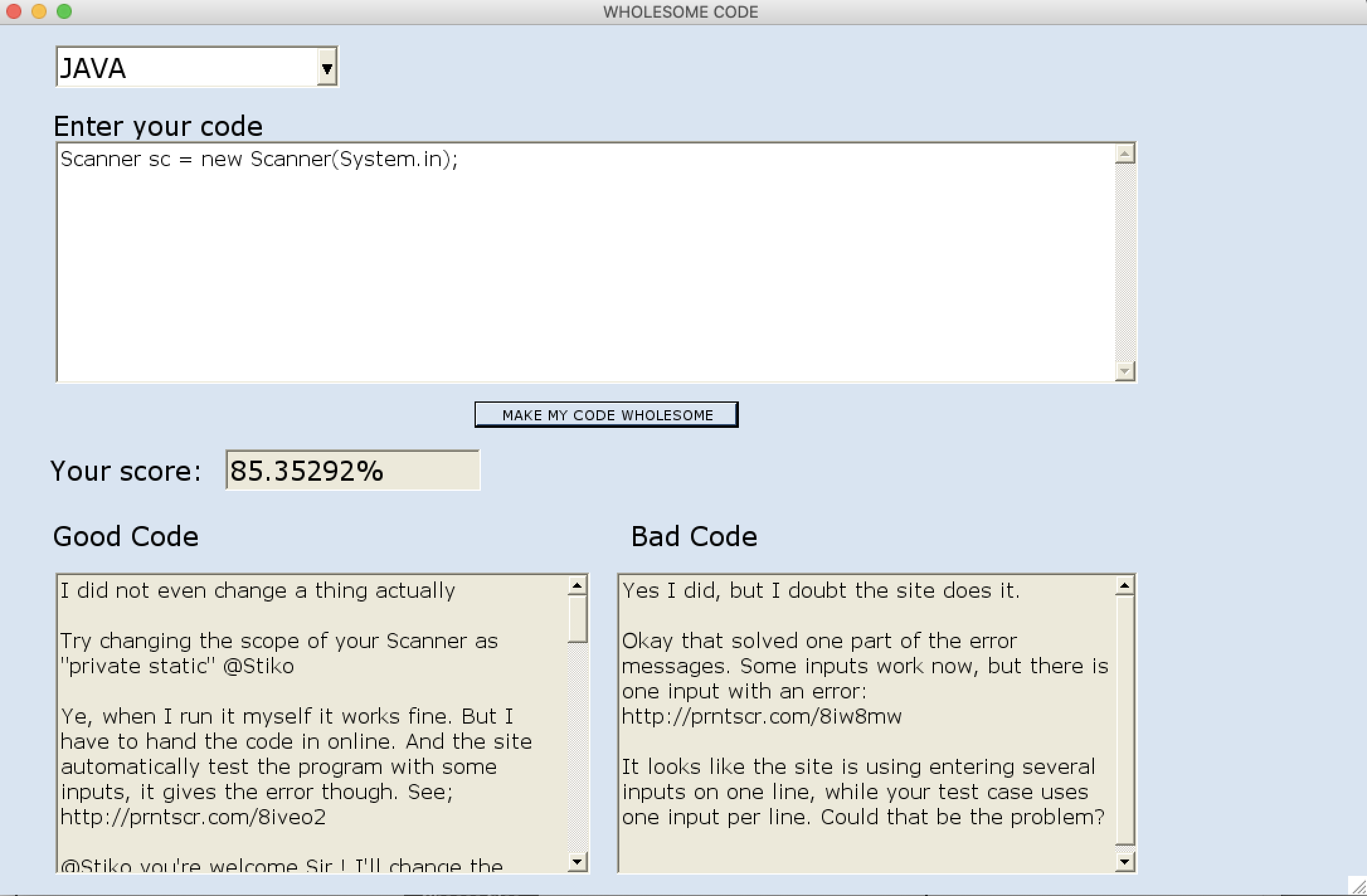
Output example
Inspiration
As a group of programmers who have been coding for a number of years, we have inevitably used StackOverflow quite a bit. At some point, some of us may even have posted our own questions on the website. It may have been noticed that some people on the website can be rather demeaning without providing much help. We wanted to figure out a way to fetch the useful data from the website and see whether our coding practices were considered good or bad in general by the online community.
What it does
It allows the user to enter short snippets of their code which is then compared against all the code of the relevant language on StackOverflow. We then rate our user's code on the basis of this (0 - 100%), and provide the top 10 comments that support the coding style and the top 10 that are opposed to it.
How we built it
The code provided by the user is matched against all the code written in the particular language on StackOverflow. If the match percentage is over a certain point (we took an arbitrary 60% which seemed to make sense for the purposes of the hackathon), we get the score (upvotes/downvotes) for the particular answer and its top comments. We then run a sentiment analysis on the text in the comments of the associated answer and find out if it has a positive or negative connotation along with its magnitude (using a scale from -1 to 1). We then find the cumulative scores using our equation and machine learning which factor in the match percentage, the sentiment analysis score on the comments, and the Answer Score provided on the StackOverflow by other users. We used MySQL, Big Query, and the Google Cloud Platform to download the dataset, Python to process the data and put it in the required format, and C# for the main algorithm and the application display itself.
Challenges we ran into
The first challenge we ran into was downloading the dataset itself. The data was roughly 360 GB and none of our computers could support this kind of memory for development purposes. So, we decided to cut down and, for the purposes of this hackathon, only make the product for one language (Java). Additionally, we also cut down all the columns in the dataset that we didn't need and carried out large amounts of Abstraction. Once we had downloaded the dataset, it first needed to be processed in Python so that we could extract the code tags from it. We found a library called BeautifulSoup which was able to help us with this. After this, reading the CSV data file in C# was another challenge in itself since the language provides no support for this and using the ',' delimiter was not an option (since some of the columns had this as a character. We had to find ways around this. Beyond this, things including running the main algorithm along with the sentiment analysis did not really prove to be much of a challenge. We tried working on a better GUI using HTML but were unable to link that to the algorithm in C#.
Accomplishments that we're proud of
The whole idea and its implementation. Worked in an efficient manner as a team, and were able to get tasks out of the way at a good pace.
What we learned
Machine learning, sentiment analysis, big query.
What's next for Avocado
Using a larger dataset and expanding into other languages. Also, using a better GUI.
Built With
- .net
- big-data
- big-query
- c#
- google-cloud-sql
- machine-learning
- mysql
- natural-language-processing
- python
- sentiment-analysis
- stack-overflow
- visual-studio



Log in or sign up for Devpost to join the conversation.