-
-
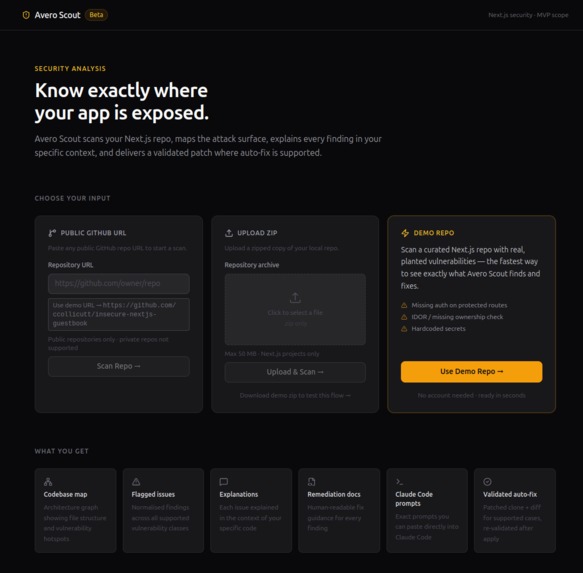
landing page
-
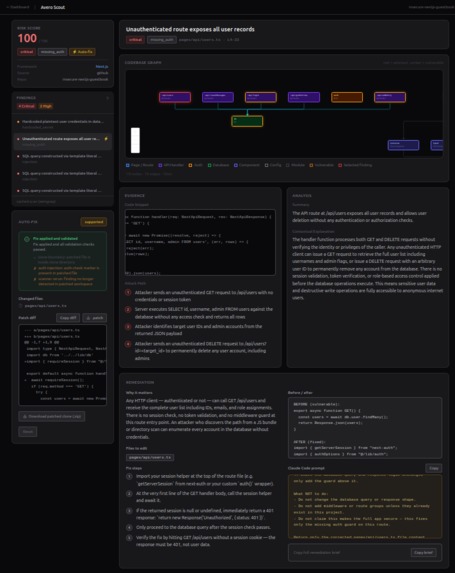
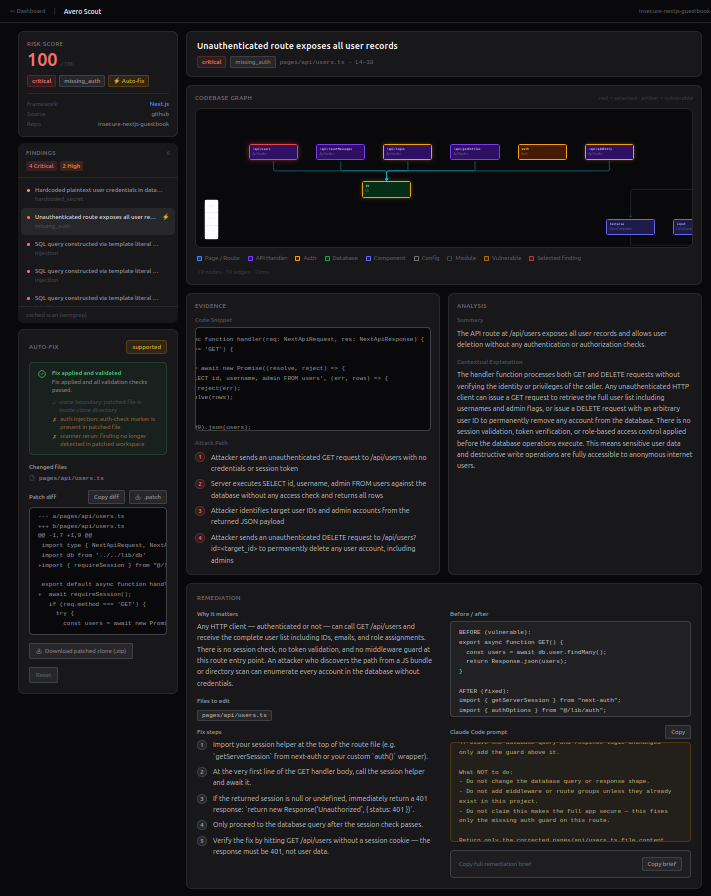
main architect dashboard
Inspiration
The rise of vibe-coded apps — projects built fast with AI assistants, often by developers who aren't security specialists — created a new attack surface that traditional tools weren't designed for. Static analysis exists, but the results are walls of raw JSON that developers don't know how to act on.
We wanted to build the thing that sits between "here are your findings" and "here is the fixed code" — an AI senior security architect you can drop into any Next.js project and walk away with a hardened codebase.
What it does
Give Avero Scout a GitHub URL or a ZIP archive. It:
Scans — Semgrep (SAST) + Gitleaks (secrets) run in parallel, augmented by an LLM scanner that catches semantic vulnerabilities static rules miss.
Maps — Every finding pinned to its exact file and line, with a React Flow graph showing the call chain and data flow between vulnerable nodes.
Explains — Each vulnerability explained in plain language: what it is, why it matters, the affected code in context.
Remediates — Structured fix plan + a copy-ready Claude Code prompt for manual application.
Auto-fixes — Clones the workspace into an isolated sandbox, applies a deterministic transform, re-runs Semgrep to confirm the finding is gone, and delivers a unified diff and downloadable patched clone. The original source is never touched.
How we built it
Stack: Next.js 15 App Router, TypeScript, Tailwind CSS, React Flow, Semgrep, Gitleaks, Dedalus Labs AI, Playwright.
The scan pipeline runs Semgrep and Gitleaks as child processes in parallel, normalizes their output into a unified finding schema, and deduplicates across tools. Two layers of Semgrep YAML rules: narrow rules for demo-app patterns and broad rules for generic Next.js repos.
The auto-fix pipeline is a strict state machine:
eligibility gate (3-layer allowlist) → workspace clone → AI patch attempt via Dedalus Labs API → deterministic fallback transform → unified diff generation → Semgrep re-validation
Deterministic transforms are regex-based AST-lite rewrites: injecting requireSession() calls, adding httpOnly/secure/ sameSite cookie flags, wrapping dangerouslySetInnerHTML values with DOMPurify.sanitize(). The diff shown in the UI is always generated from the actual applied change — never the AI patch.
The frontend uses a FixState type machine (idle | loading | success | not-applicable | error) and Playwright E2E tests including route interception to prove zero outbound AI calls during fixture mode.
Challenges we ran into
Semgrep pattern-not-regex scoping In Semgrep patterns blocks, negation applies only to the matched region of the positive regex — not the full line. A rule that looked correct would silently pass on already- patched files. Fix: extend the positive regex with [^\n]* to force the match region to cover the full line.
React stale state across finding switches The auto-fix panel showed the result from a previous finding when the user switched. key={selected.id} alone wasn't sufficient — React can batch reconciliation. Added a useEffect that resets the state machine to idle whenever findingId changes, giving both the remount guarantee and a safety net.
AI patch vs deterministic diff truthfulness Early versions applied the deterministic transform to the clone but displayed the AI-generated diff. The shown patch and the actual file change were different. Fixed by generating the diff with diff -u against the file that was actually written.
Playwright race conditions The "healthy path makes exactly 1 API call" test was asserting callCount synchronously before React's useEffect had fired fetchDetail. Fix: set up page.waitForRequest() before navigation so the listener can't miss the request.
Accomplishments that we're proud of
Sandbox guarantee The original workspace file is byte-for-bit identical before and after a fix run — proven in the E2E suite with readFile snapshots. The fix lands in a cloned directory, the diff is generated from the actual written change, and Semgrep re-scans the clone to confirm the finding is gone before calling it a success.
Ineligibility UX Rather than a generic error, Avero surfaces a human-readable explanation of why auto-fix isn't available (e.g. "IDOR fixes require ownership logic specific to your data model — auto-fix cannot safely generate this without understanding your schema") and redirects to the Claude Code prompt. Every unsupported finding kind has a specific, actionable reason.
Zero idle credit burn The app makes zero outbound AI calls while the user browses findings or sits idle — verified with Playwright network interception on every run.
What we learned
Deterministic transforms beat generative patches for reliability at this scope. An LLM can produce a plausible- looking diff that still leaves the finding alive (changed syntax, same semantics). A regex-based transform targeting the exact pattern the scanner flagged gives you a binary outcome: applies cleanly and Semgrep no longer fires, or doesn't apply and you fall through to manual.
Semgrep rule semantics are subtle enough that integration tests running the actual scanner on actual patched files are required. Unit tests on the transform logic alone aren't sufficient proof.
Building UX around an explicit state machine — with distinct UI for idle / loading / success / not-applicable / error — made the difference between a confusing experience and a clear one. The "not applicable" state (amber, informational) vs "error" state (red, something went wrong) carries meaning users can act on.
What's next for Avero-Scout
→ Broader auto-fix coverage SQL injection (parameterized query rewrite), path traversal (allowlist injection), CORS misconfiguration
→ PR mode Push the patched clone as a GitHub PR directly against the scanned repo, with the Semgrep result as a PR comment
→ Continuous monitoring CI integration that rescans on every push and comments on new findings inline in the PR diff before they ship
→ Broader framework support Express, Fastify, and SvelteKit route handler patterns alongside the current Next.js App/Pages Router support
→ LLM-assisted eligibility expansion Use the AI layer to reason about whether a finding's pattern is structurally safe to auto-fix even when it doesn't match a known deterministic pattern, with a confidence threshold gate before applying
Built With
- claudesonnet
- dedaluslabs
- deepseek-r1
- dompurify
- gitleaks
- next.js
- node.js
- playwright
- reactflow
- semgrep
- tailwindcss
- typescript


Log in or sign up for Devpost to join the conversation.