Inspiration
Technology is only useful when people have access to it.
"Our whole company is founded on the principle that there is something very different that happens with one person, one computer... What we're trying to do is remove the barrier of having to learn to use a computer." Steve Jobs believed that revolutions in society came from the accessibility and adoptability of technology. And he carried this vision throughout his entire career. From the transition from mainframes to personal computers, from the CLI to GUI, from fixed width characters to beautiful typography. Without improvements in accessibility, breakthroughs in research, globalization of culture, and distribution of new ideas would never have been possible.
And similar to personal computers, we believe that access to frontier AI systems are a necessity for driving societal growth.
AI systems have been widely distributed thanks to existing computer infrastructures. However, there are still many instances around the world where the benefit of AI is inaccessible. In domains where privacy, cost efficiency, reliability, deep domain knowledge, or offline access are critical, SOTA models fall short or are outright unusable. Open source models fill this gap, but rely on post-training methods to match SOTA models in accuracy. However, post-training methods are difficult to implement and set up for non-technical audiences. In a world where access to AI systems fundamentally changes how people approach their field, lack of access to technology can leave entire communities behind.
What it does
And similar to the efforts in the computing industry, we believe that post-training open source models should be as easy as possible. AutoTune allows anyone to fine-tune a model for any use case. From automating clinic patient information to organizing hundreds of confidential legal files, with just a simple text prompt, users can build and interact with models specialized for their tasks and deploy their models through Modal with one click.
How we built it
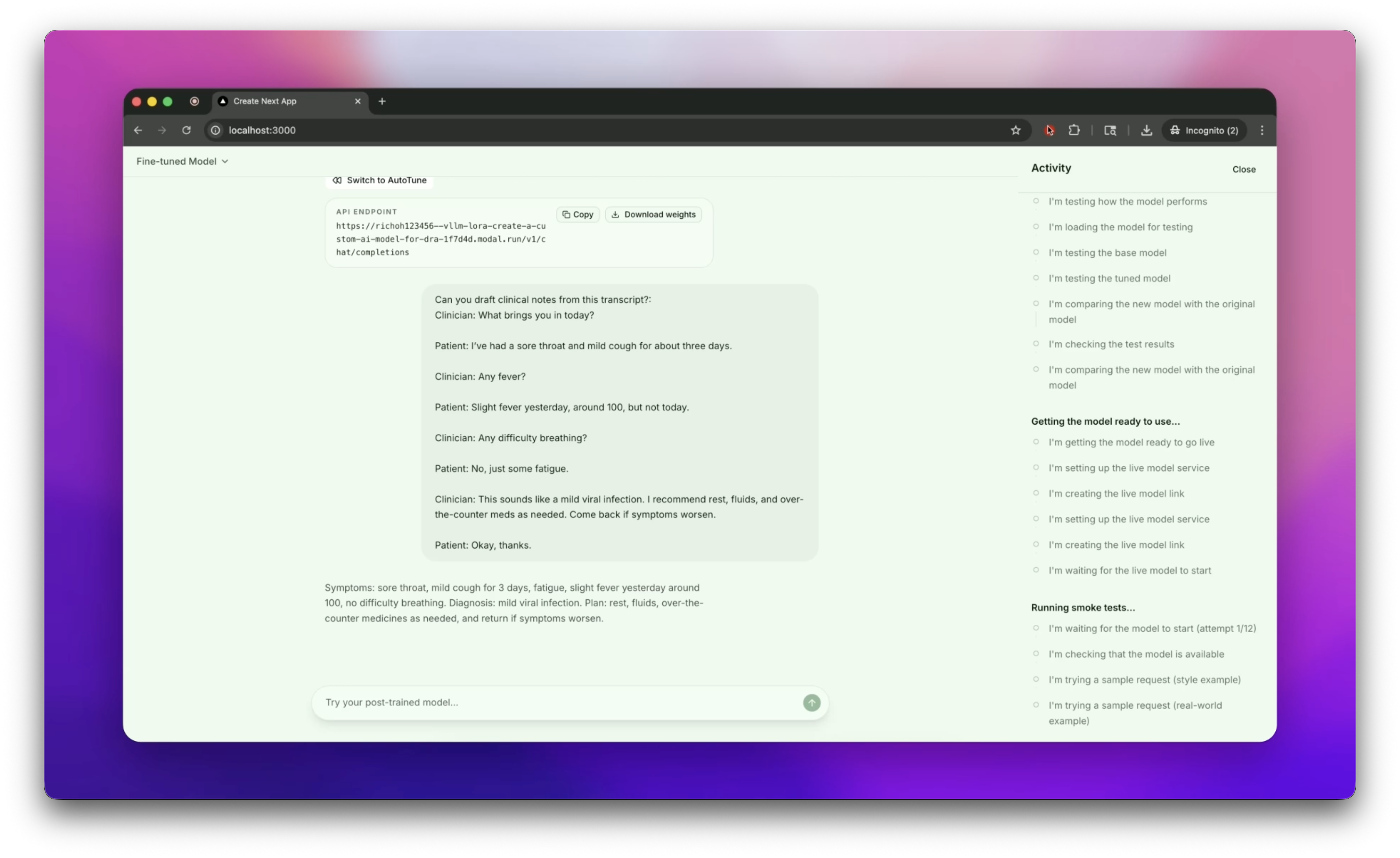
We built AutoTune as a chat-first post-training interface.
To train, we use:
Huggingface for open datasets for fine-tuning
GPT-5-mini to convert prompts into training configs, datasets, and evaluation
Modal for cloud GPU infrastructure
Transformers Reinforcement Learning (TRL), a library to train transformer language models, handles the supervised fine-tuning (SFT) loop
Low-Rank Adaptation (LoRA) enables us to adapt our base Qwen3 model
vLLM to host the tuned model with an OpenAI-compatible endpoint
We evaluate the model quality with an LLM-based judge for generative tasks and accuracy for classification tasks
Once training is completed, the models are deployed on Modal, along with downloadable final weights.
Our frontend mirrors ChatGPT, creating a natural interface for a user to begin creating their own fine-tuned models.
Challenges we ran into
For our dataset search process, we ran into issues with Huggingface because of the lack of a standard for dataset headers. So, we had to put a lot of work into mapping the headers into usable fields, while filtering out unusable data.
Deploying with LoRA adapters on the cloud required working through compatibility issues with the trained artifacts, vLLM, and the Modal environments. Also, to properly appeal to non-technical users, we had to filter the jargon in our log statements to be more user-friendly in the actual UI.
Accomplishments that we're proud of
Truly intuitive framework. Similar to existing chat interfaces, users are able to truly abstract their ideas into words and AutoTune is able to find the datasets and train models with the correct training methods without any human intervention or supervision.
Easy deployment. With a single click, you have an api endpoint running through Modal or download the model, allowing other high level development platforms to easily interact with your model.
What we learned
We learned how fine-tuning really works and how real the limitations of easily picking up post-training workflows are. Additionally, we learned that the performance of open source models is highly malleable with the proper fine-tuning techniques and datasets, even comparable to frontier closed models on specific tasks.
What's next for AutoTune
AutoTune really allows anyone to fine-tune and deploy a model. We hope we can distribute this technology to as many people as possible allowing frontier technology to be able to serve anyone who needs it.
We also want to add more experimental fine-tuning techniques and experiment with synthetic datasets generated by SOTA models, adding features from frontier of research to take our training to the next level.
We also hope to integrate our project with claude code or codex, to fully build out a working end to end product from just a chat interface.
Built With
- huggingface
- modal
- nextjs
- react

Log in or sign up for Devpost to join the conversation.