-
-
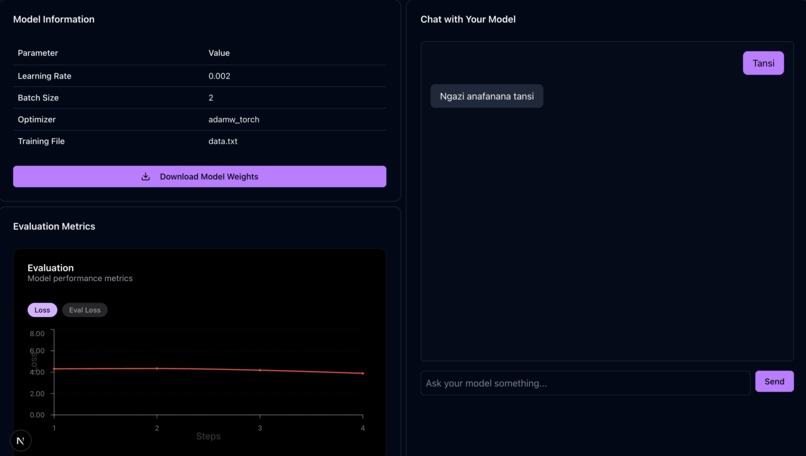
Model deployment
-
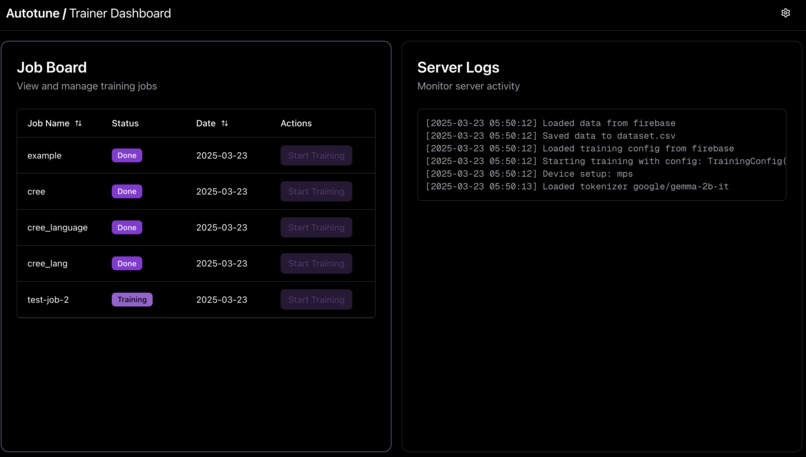
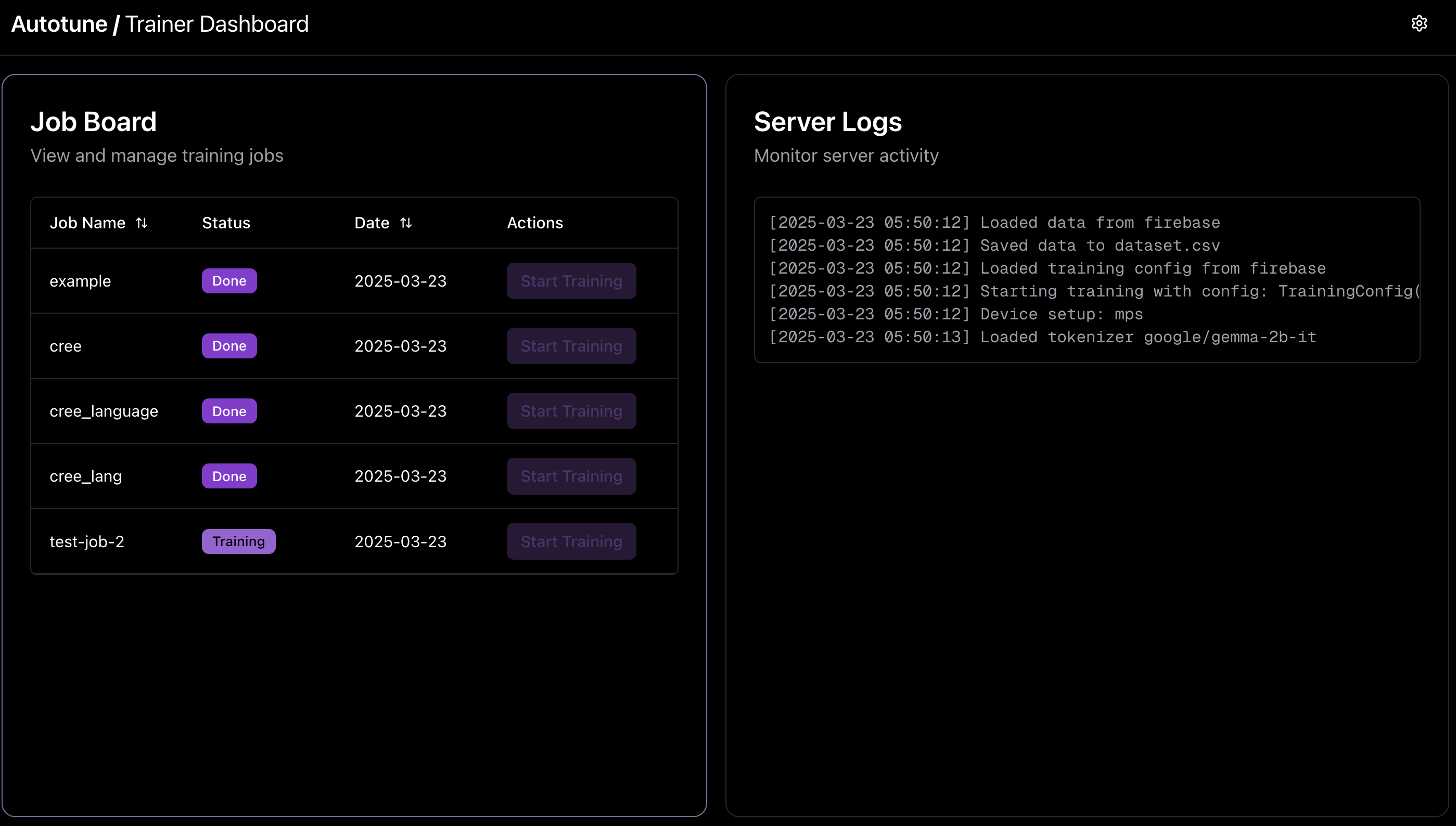
Trainer-side page
-
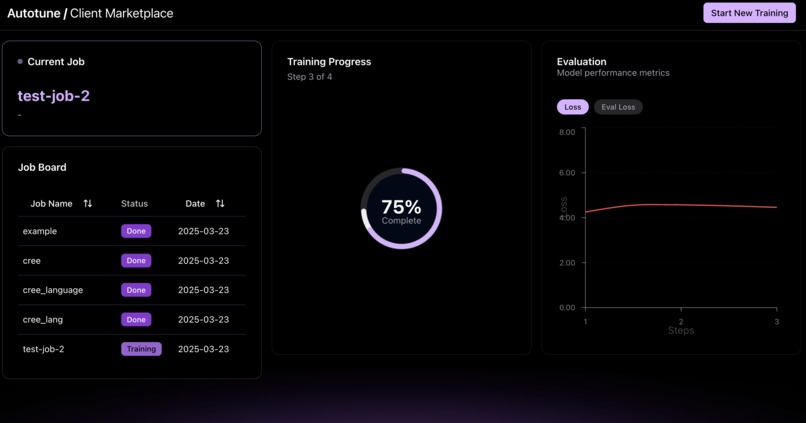
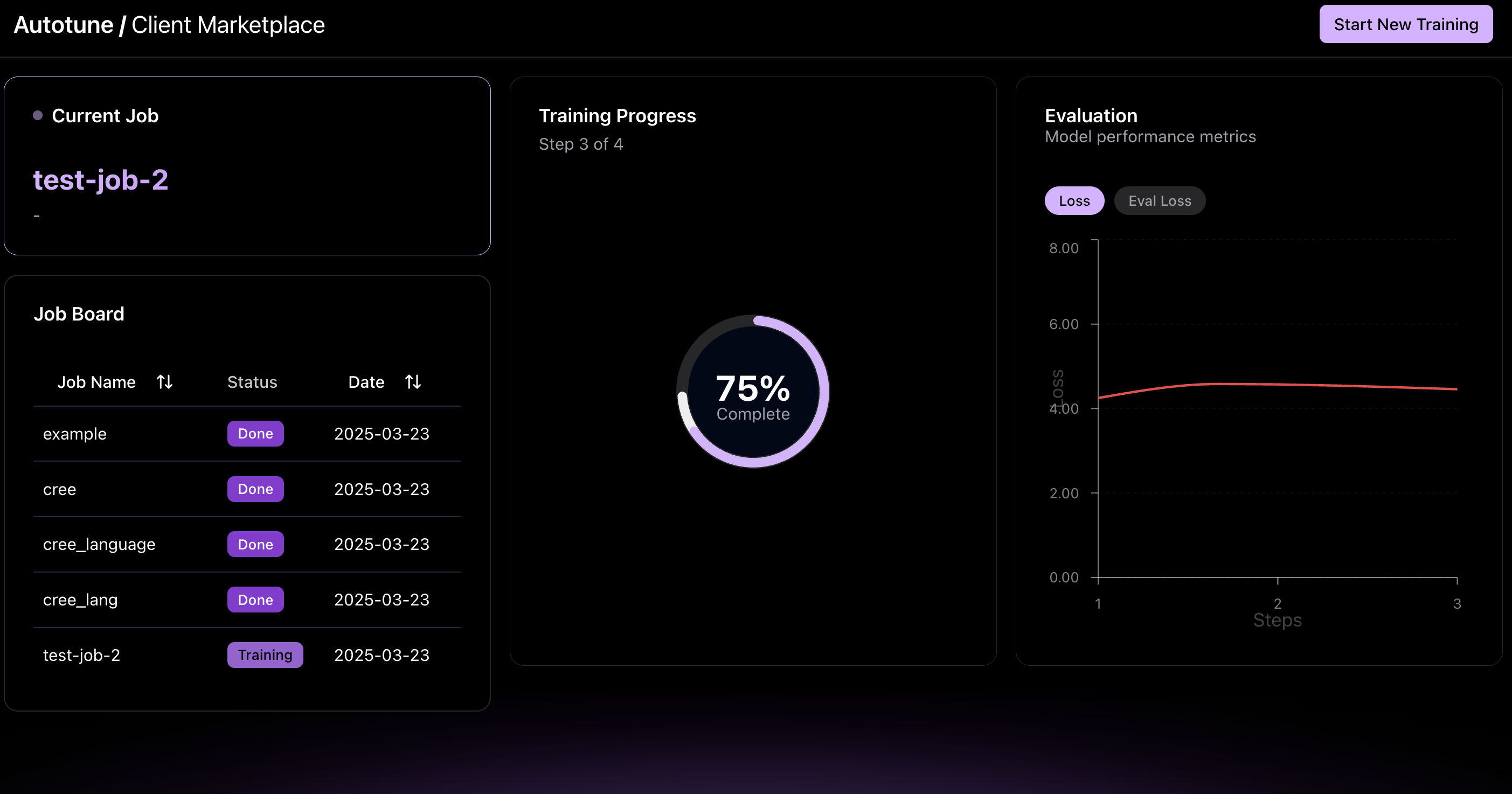
Client-side page
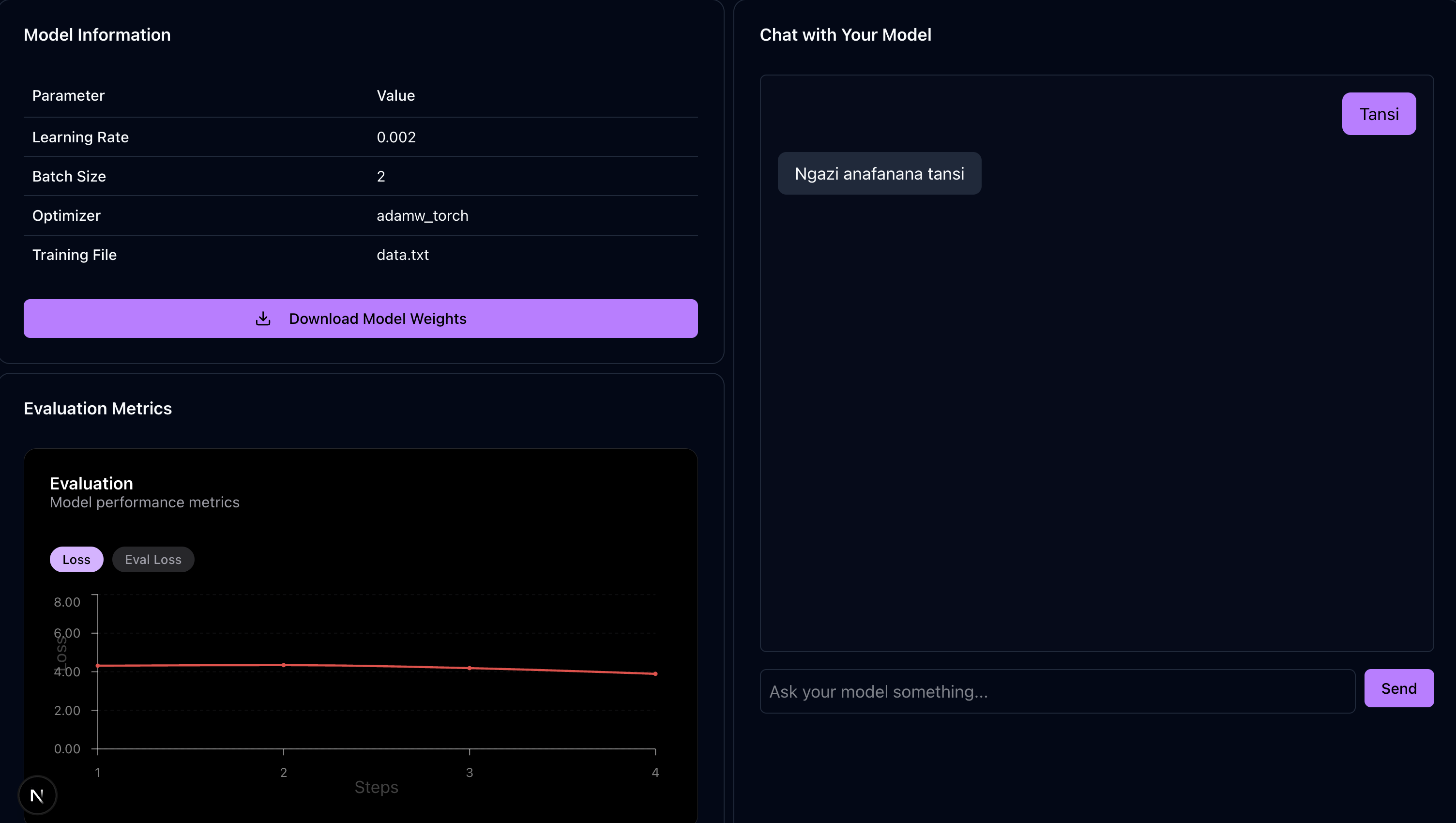
Autotune
Inspiration
Autotune was built with two core goals in mind:
- Empowering non-technical creators to fine-tune and deploy their own models for self-inference.
- Democratizing access to LLM computing by making training and fine-tuning more affordable. Our platform streamlines the entire process. Clients can create a "job" by uploading their data and selecting a model to fine-tune. Trainers—anyone signed up to provide computer resources—can pick up these jobs and run the fine-tuning process. Once complete, the model is automatically deployed, giving clients full control to use it however they need. By decentralizing compute power and simplifying AI customization, Autotune makes high-quality model fine-tuning accessible to everyone.
Technology Stack
Languages: Python: **Used for back end development, AI model fine-tuning, and handling inference logic. **Docker: Containerized training environments to ensure consistent and scalable deployments. Type Script: Used for front-end and back-end integration.
Frameworks and Libraries: ** **PyTorch: Enabled deep learning model fine-tuning and inference. Hugging Face: Provided pre-trained models and APIs for fine-tuning. Google Cloud Platform: Hosted compute resources, storage, and deployment infrastructure. Convex: **Simplified backend data management with real-time syncing using web-sockets for front-end diagrams. **Next.js: **Powered the frontend with server-side rendering and optimized performance. **React: Built the interactive user interface for clients and trainers.
Platform Hugging Face + Google Cloud: Provided a platform to deploy the fine tuned parameters for inference and load the model weights
Product Summary
Autotune is an AI-powered platform designed to empower non-technical creators and democratize access to LLM computing by making model fine-tuning and deployment more affordable and accessible. Key Features & Experience 🔹 For Clients (Model Owners): Easily upload datasets and select models for fine-tuning. Real-time job tracking with detailed updates, including evaluation metrics (loss, eval loss) and training progress over time steps. Automatic deployment of fine-tuned models for seamless self-inference.
🔹 For Trainers (Compute Providers): Pick up training jobs and contribute computing power. Live job status & logging for full transparency. Priority queue system to optimize job allocation.
Innovative Approach Decentralized Compute: Lowers training costs by distributing jobs to available compute providers. Seamless AI Customization: No coding expertise required to fine-tune and deploy models. Real-Time Insights: Live updates ensure transparency in model performance and progress. Once fine-tuned, users can immediately chat with their custom model—unlocking powerful, tailored AI capabilities without technical barriers.
Accomplishments
-Successfully built a decentralized AI fine-tuning platform that connects clients with trainers to optimize model training efficiency. -Streamlined the model fine-tuning process, allowing non-technical users to customize AI models with ease. -Lowered the cost of LLM fine-tuning by enabling users to leverage decentralized compute resources. Automated deployment of fine-tuned models, giving clients full control over their AI solutions.
What We Learned
-Optimizing Compute Distribution: We explored how to allocate training jobs across distributed machines efficiently -Automating the Deployment Pipeline: We streamlined the process of automatically deploying fine-tuned models to cloud platforms, removing manual intervention for end users










Log in or sign up for Devpost to join the conversation.