Inspiration
AI now writes an enormous share of the text, code, and records we rely on — yet almost none of it gets independently verified. Two questions started this project:
- How do you check AI-generated facts at scale?
- How do you score a verifier so it can't just game the metric?
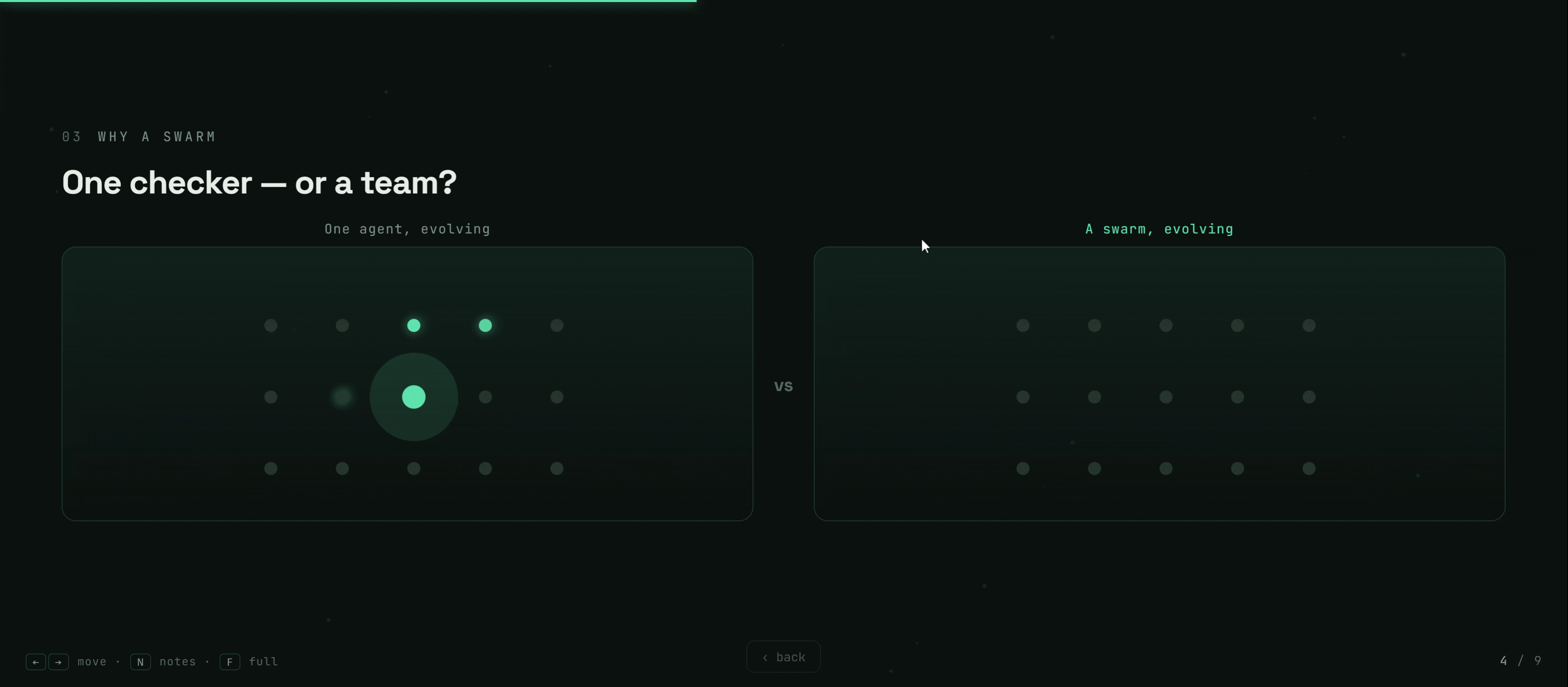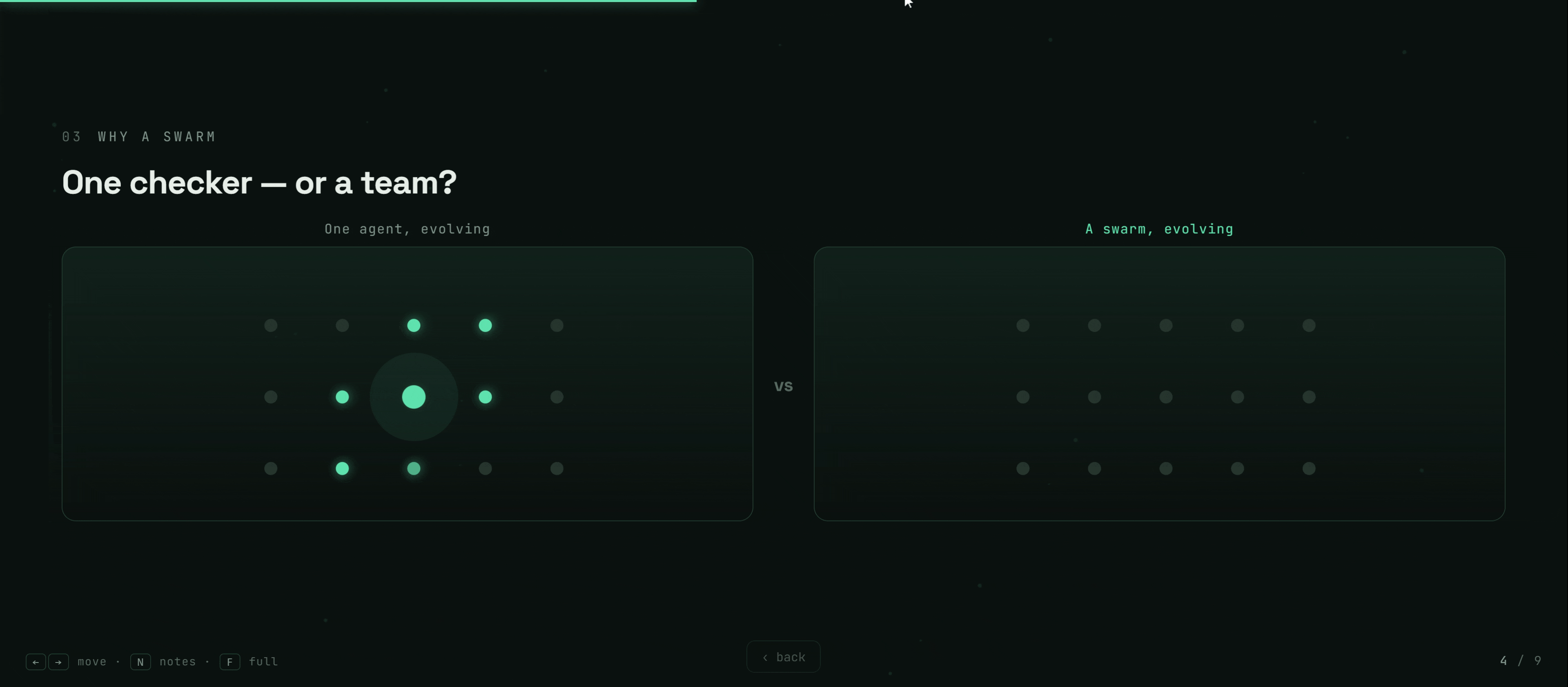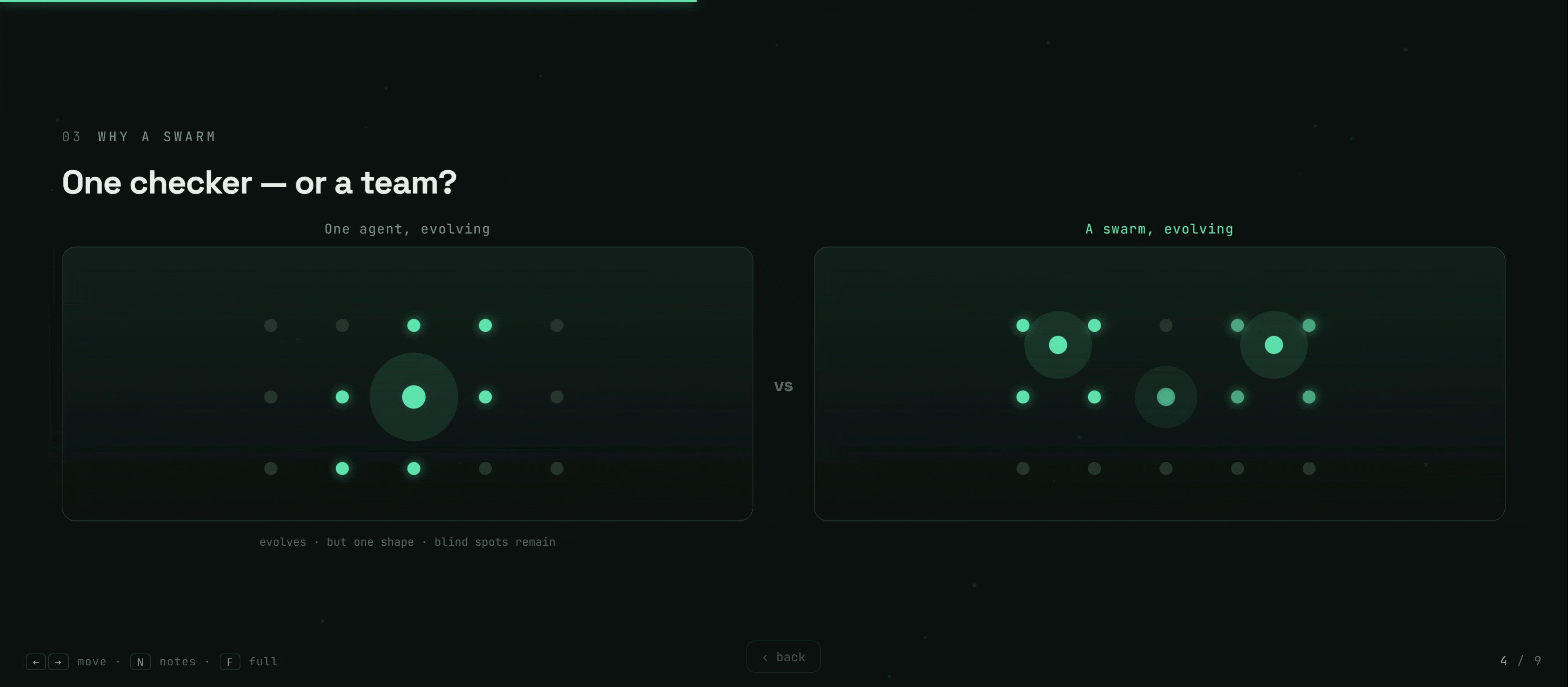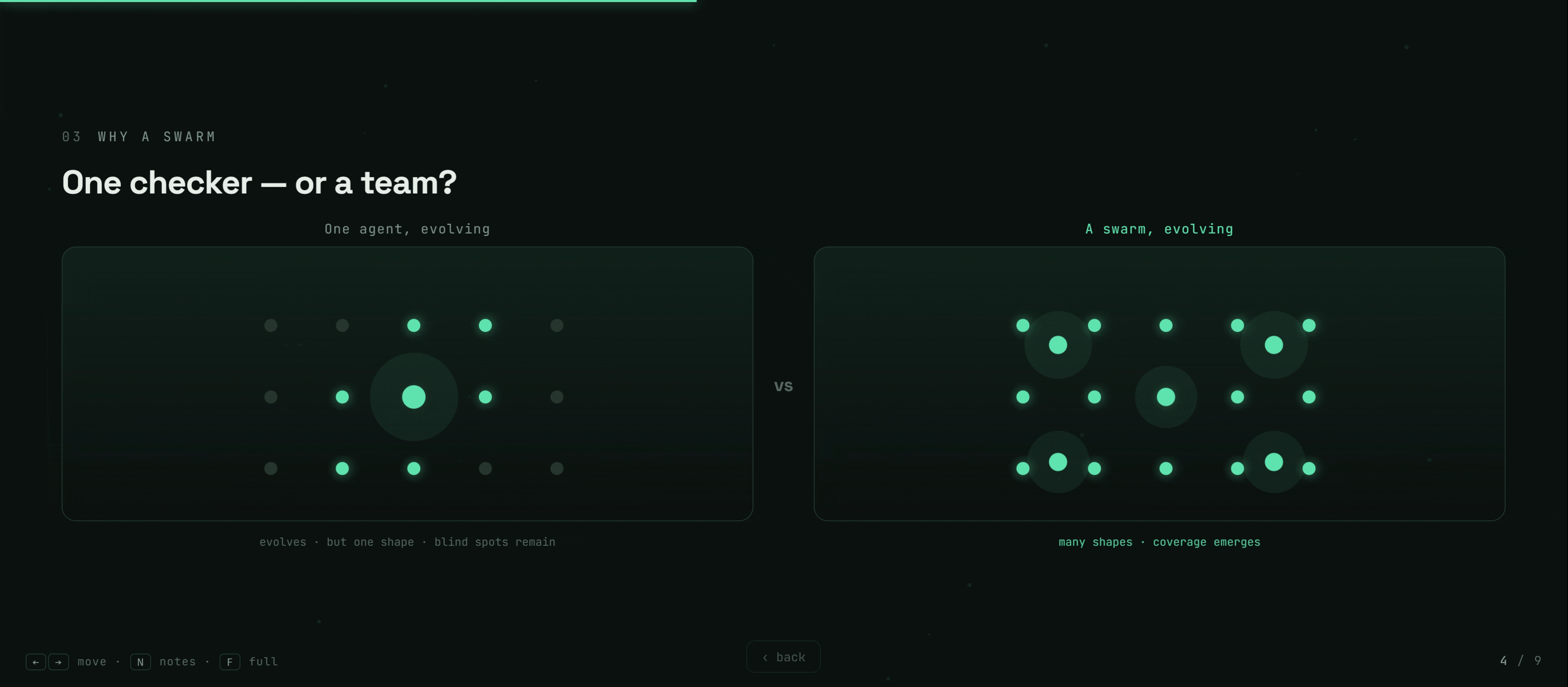
The answer we explored is biological: not one perfect checker, but a swarm of specialists, evolved by selection — like an immune system, where diversity itself is the defense.
What it does
AutoSwarm is a self-evolving swarm of AI auditors with an ungameable score. We plant known errors into synthetic records and hold the answer key, so every detector is graded on an objective test — never its own say-so. Scoring uses $F_1$ on a held-out test set scored exactly once, so "flag everything" loses and the metric can't be reward-hacked:
$$F_1 = \frac{2 \cdot \text{precision} \cdot \text{recall}}{\text{precision} + \text{recall}}$$
The swarm then evolves — mutating, selecting, and merging detectors — to catch more.
We built it across two domains:
- Medical bills — the working proof. Detectors catch planted billing errors, and the swarm measurably improves.
- Supply-chain diversion — a direction, not a deployed tool. A fully synthetic scenario modeled on documented financial-crime signals (FinCEN advisories, C4ADS reporting). No real entities.
The honest boundary: AutoSwarm surfaces leads, not verdicts. It works only on verifiable facts, and a human always makes the call. Metal detector, not judge.
How we built it
- Detectors are LLM "lenses" (OpenAI
gpt-4o-mini), each reading the same records through a different angle. - An $F_1$ scorer + ensemble layer (majority vs. union voting) and an evolution loop (mutate → select → merge), all under a strict train / validation / held-out-test split so we can't fool ourselves.
- The full cat-and-mouse loop runs as a durable, event-driven workflow on Inngest (Python SDK + Flask) — the system watches itself:
evaluate → detect drop → explore → evolve → recover, every step replayable. - A self-contained web demo + animated pitch deck (HTML / CSS / JS / SVG), deployed on Vercel.
Challenges we faced (the negative results we kept)
This was a research project, and the failures were the point:
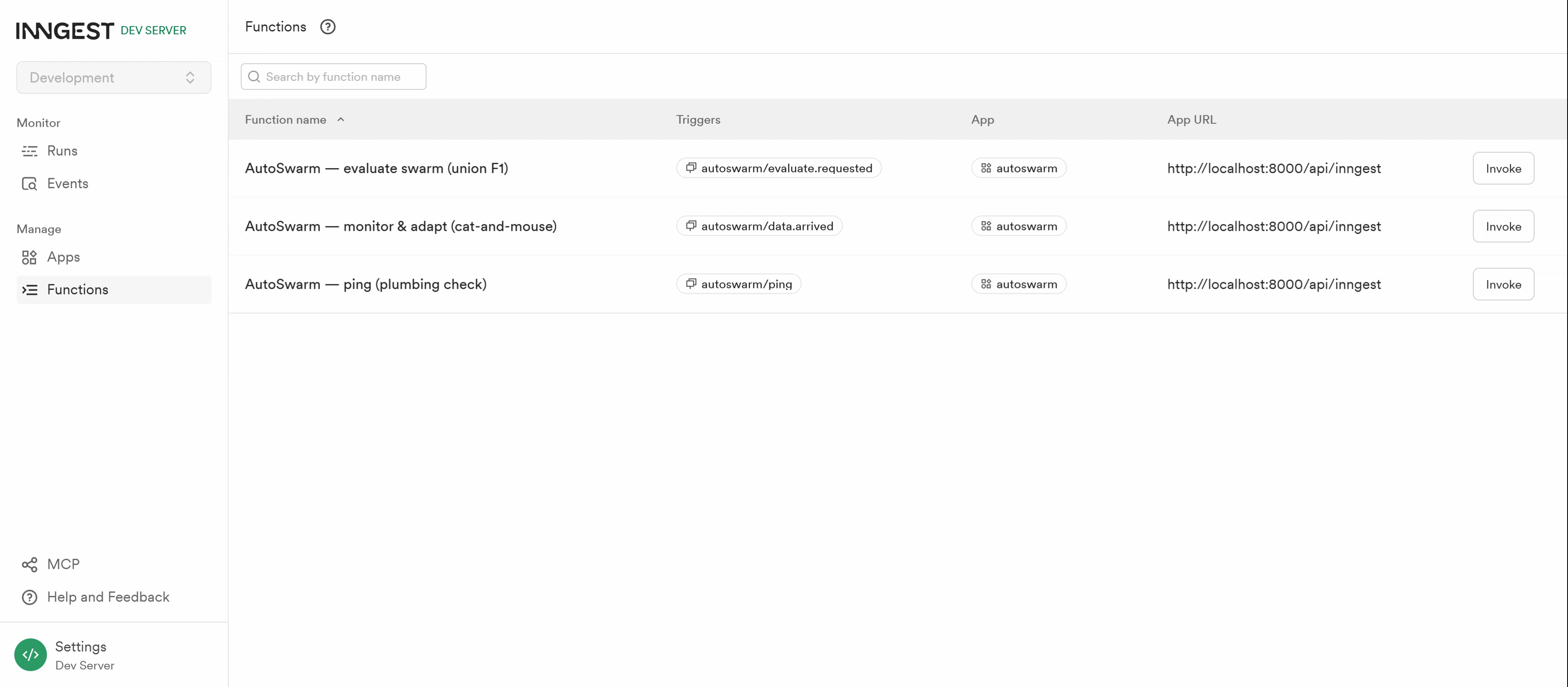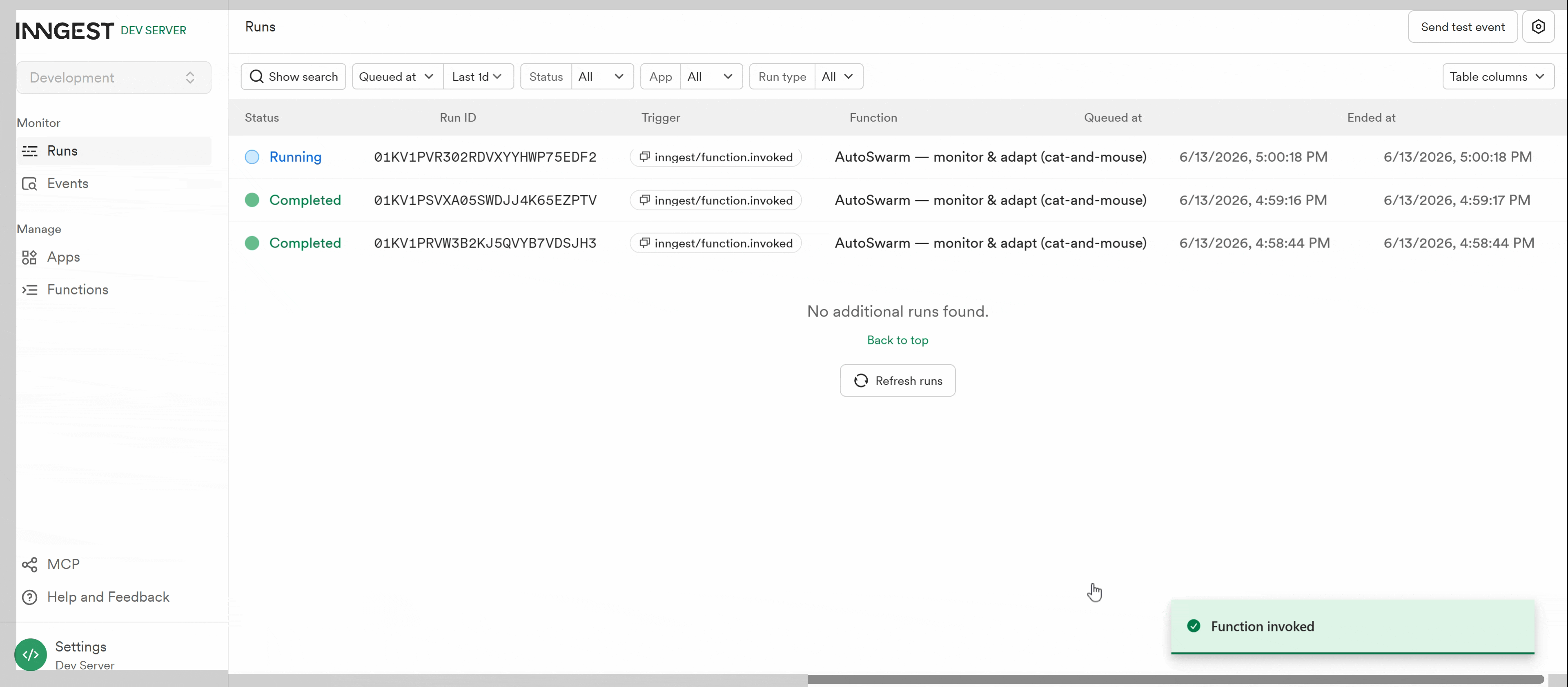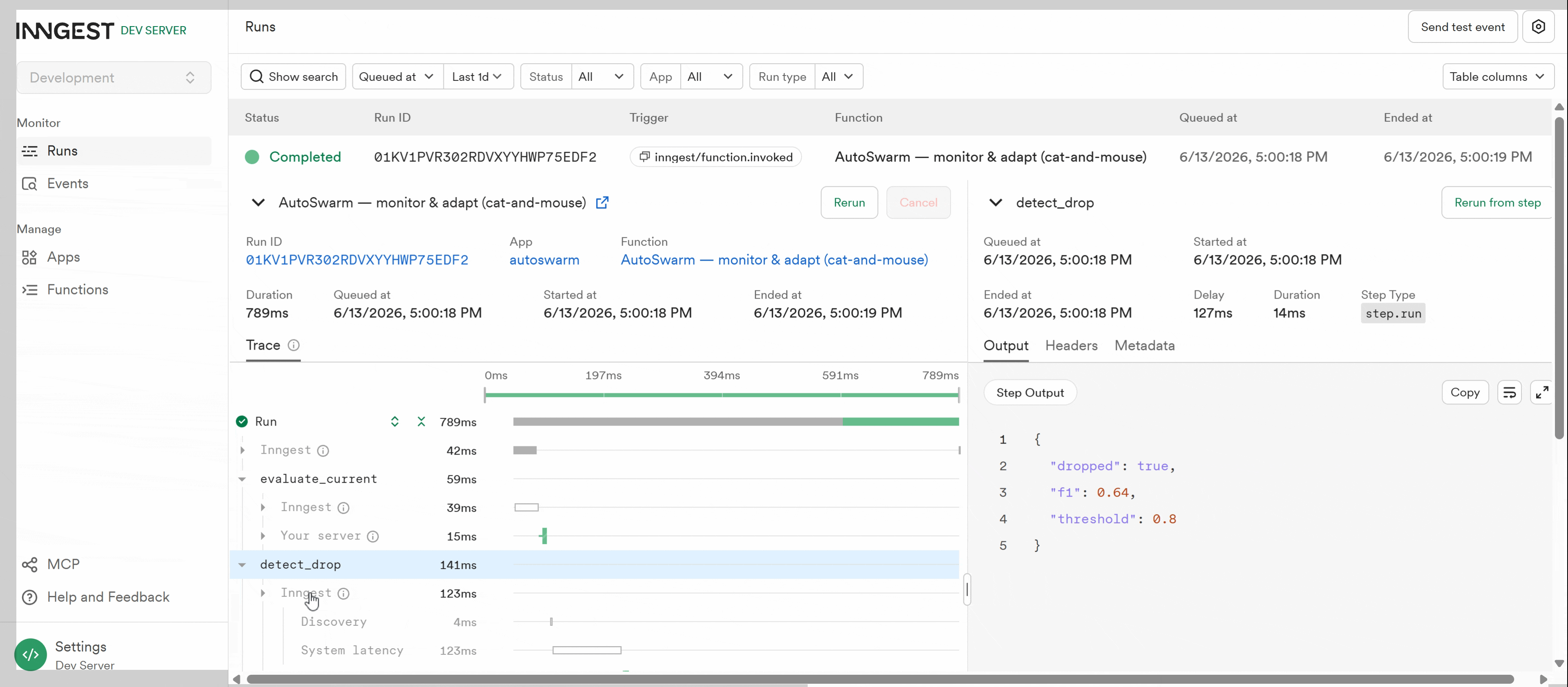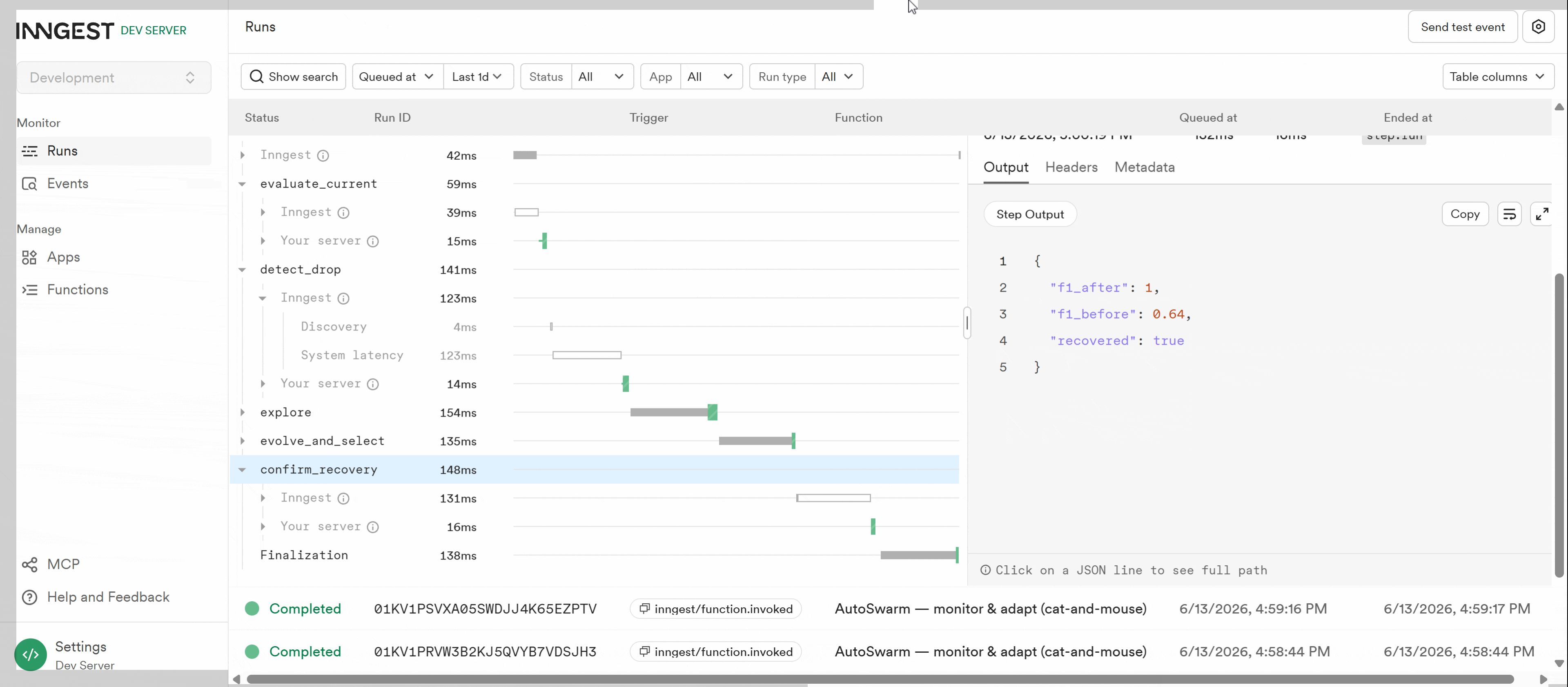
- Majority voting buried our best specialist. The one detector that caught a subtle error got out-voted — held-out $F_1 = 0.00$. Switching to union recovered it ($0.67$).
- Greedy selection eroded the swarm. Picking the highest individual-$F_1$ detectors discarded low-solo-but-unique specialists, dragging the ensemble $0.67 \to 0.50$.
- The fix backfired — then taught us why. Ensemble-fitness selection collapsed to a single precise detector on a too-small validation set. Root cause: the eval set, not the idea. Coverage-aware fixed-size selection + merge fixed it — validation $F_1$ climbed $0.82 \to 0.87$.
- We expose a real generalization gap on purpose: validation $0.87$ vs. held-out test $0.62$ (test scored once).
What we learned
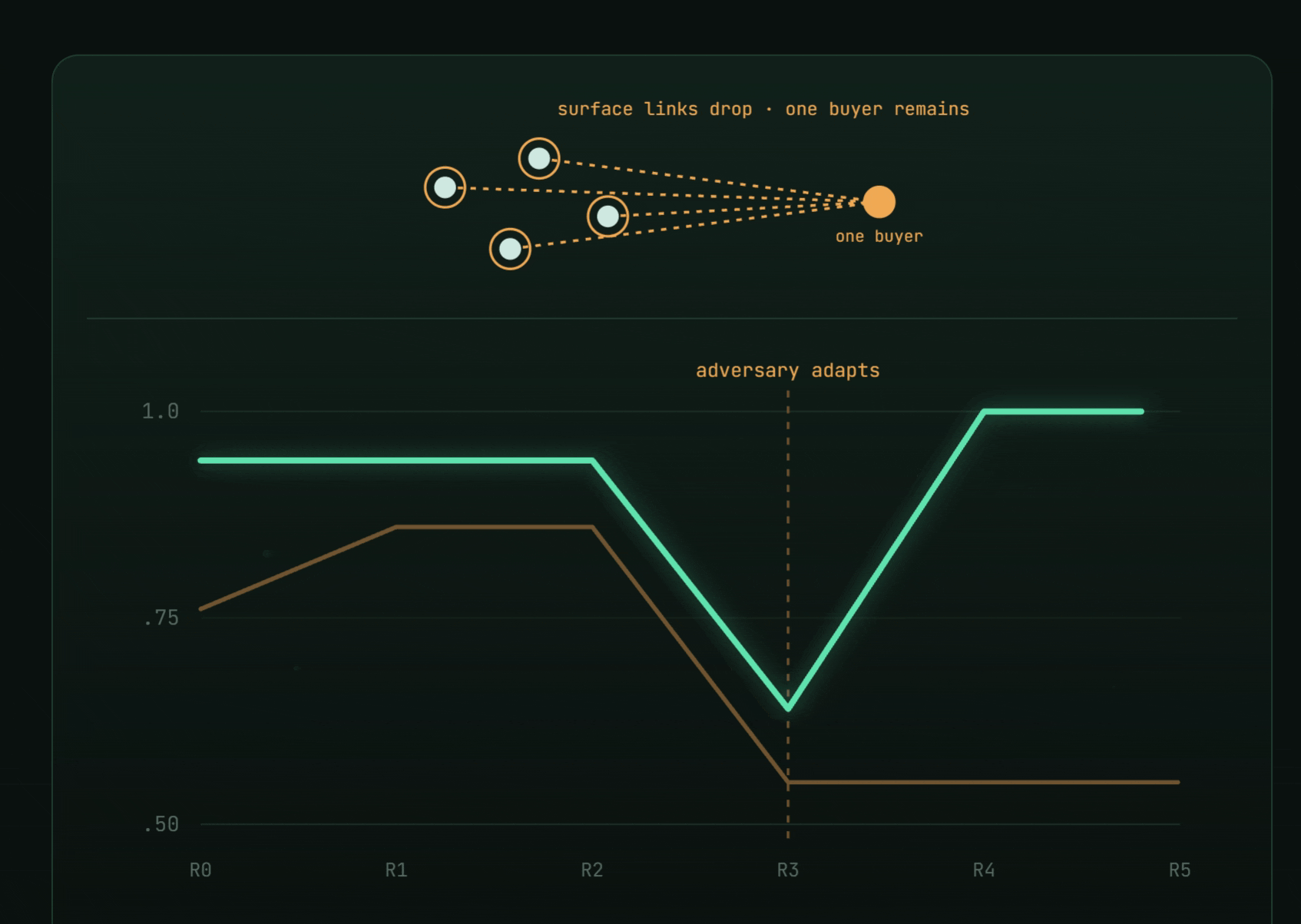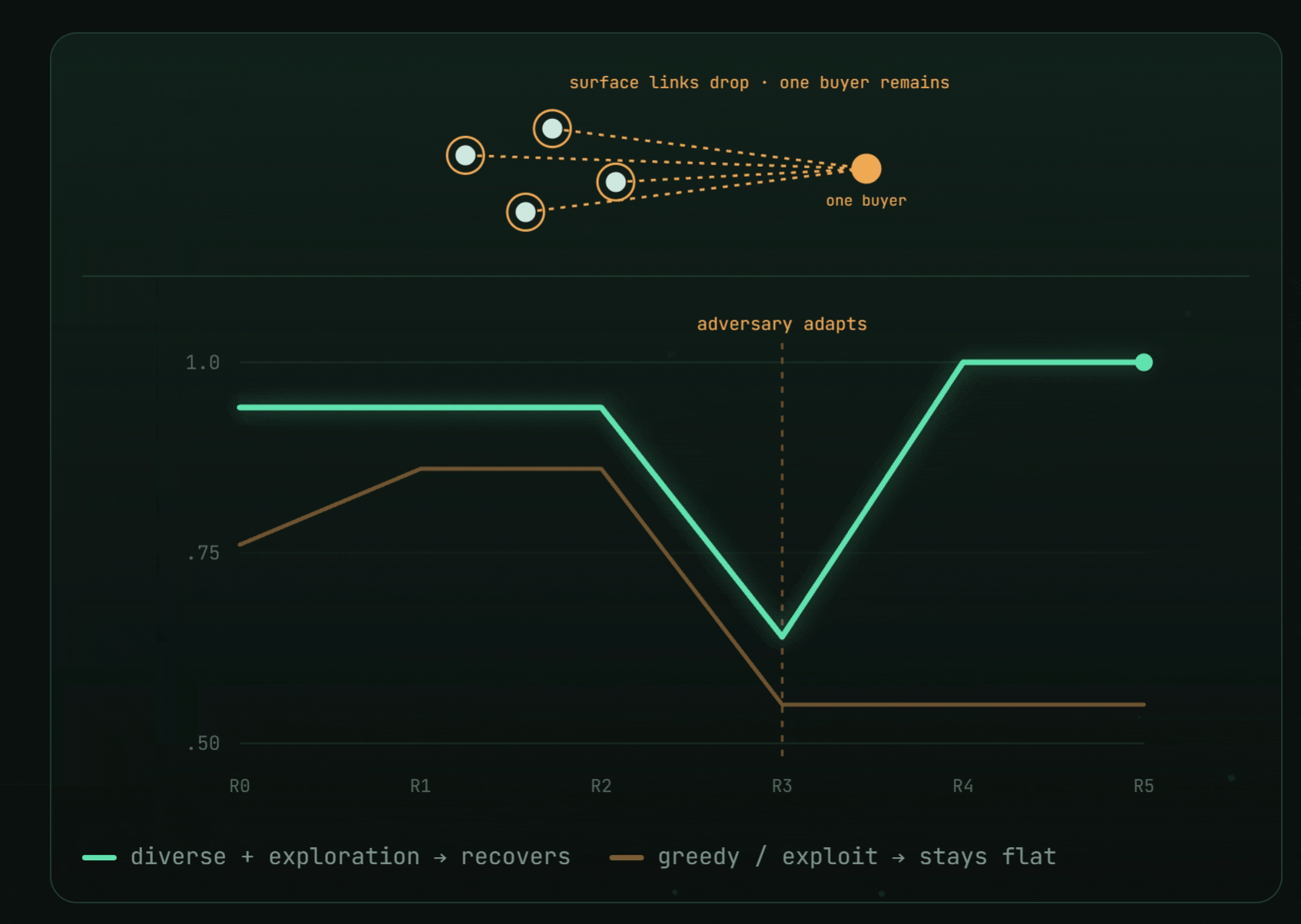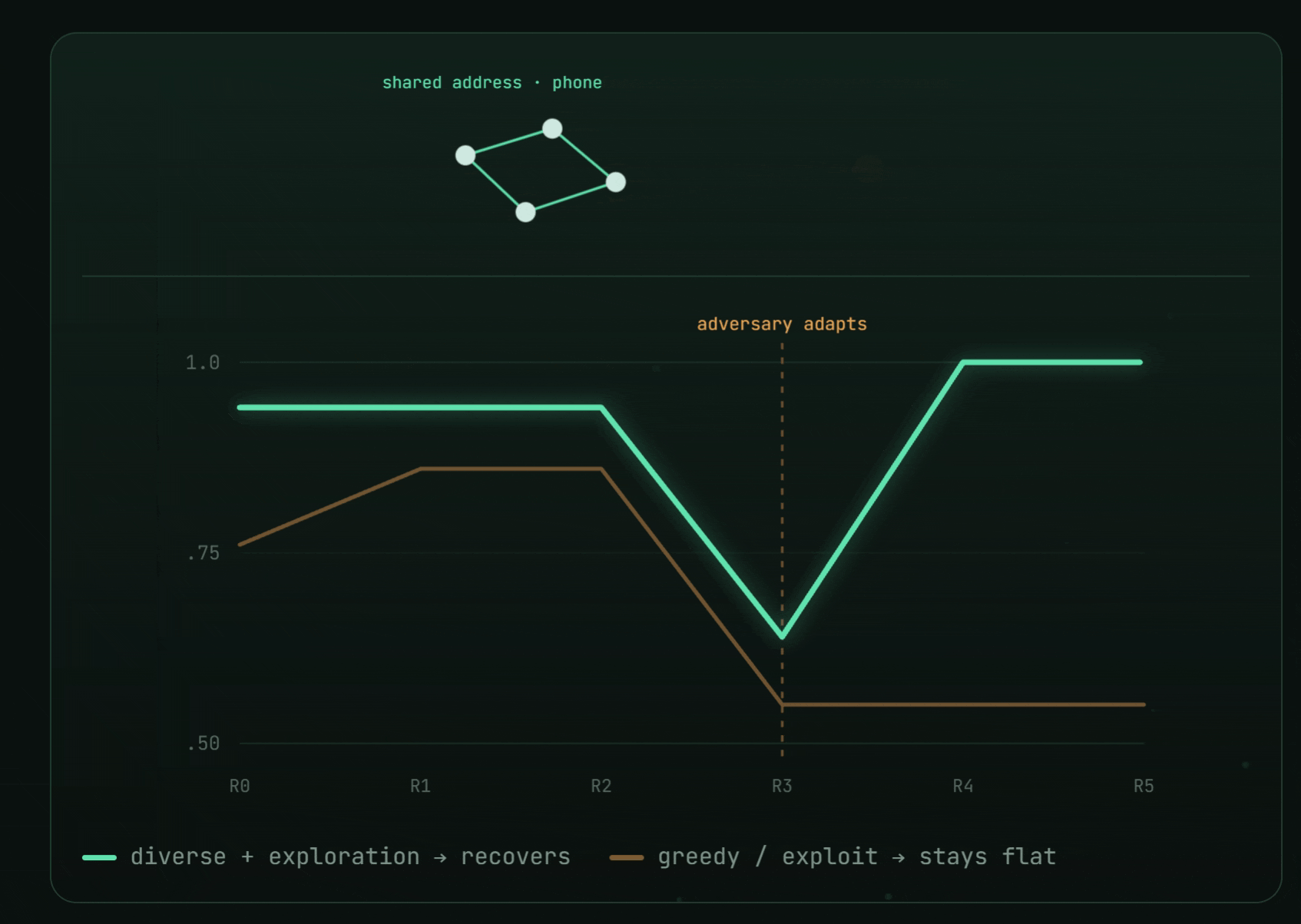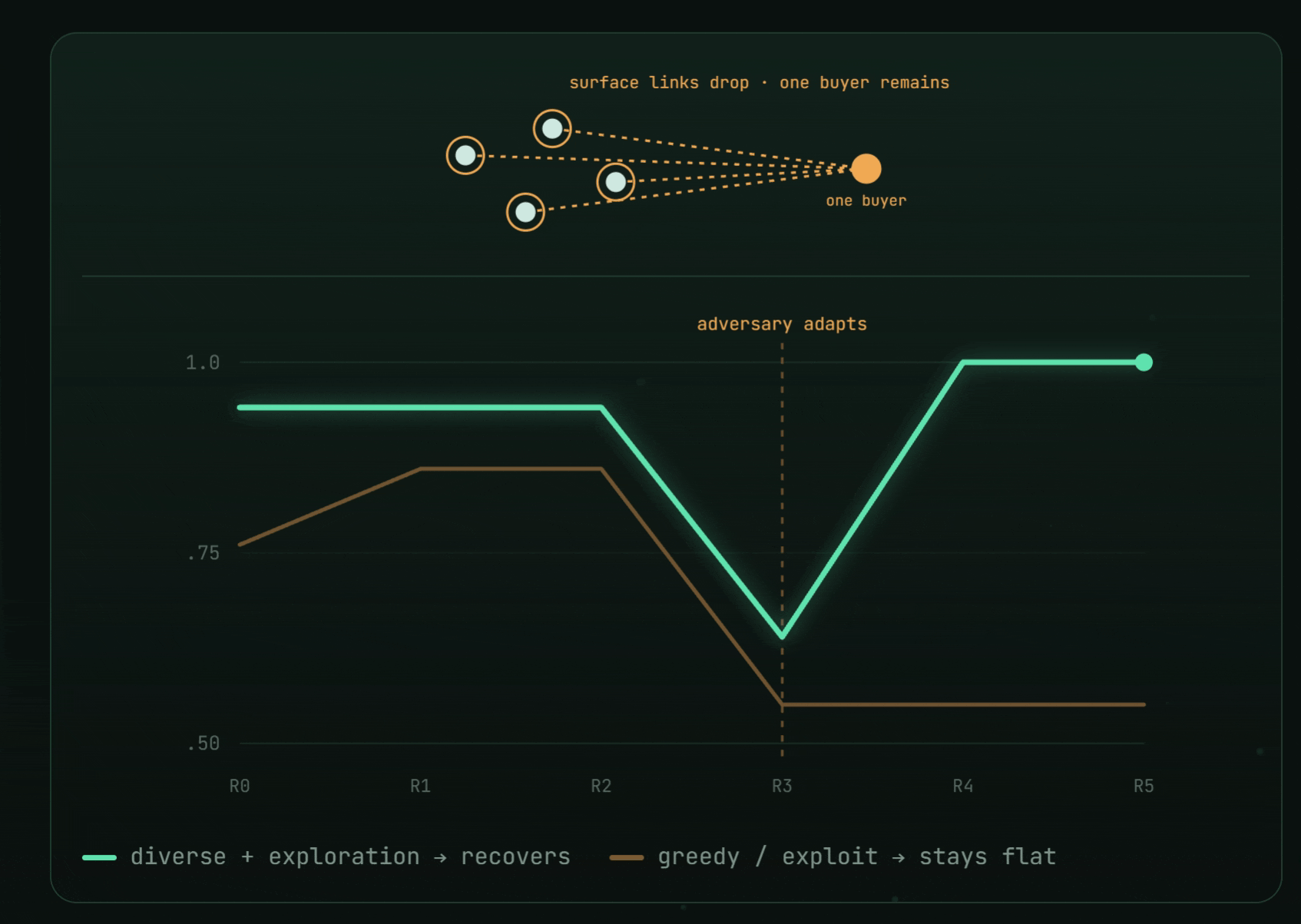
The deepest lesson came from an adapting adversary. A second wave of bad actors evaded every signal the swarm had learned — combined $F_1$ cratered $0.76 \to 0.27$.
- An exploit-only swarm stayed flat after the shift: $[0.76,\ 0.86,\ 0.86,\ 0.55,\ 0.55,\ 0.55]$.
- A diversity + exploration swarm recovered to $1.0$: $[0.94,\ 0.94,\ 0.94,\ 0.64,\ 1.0,\ 1.0]$ — by emergently rediscovering the one invariant the adversary couldn't hide (everything still funneled to a single buyer).
Against a moving target, diversity is insurance. You don't chase the disguise; you detect the invariant backbone underneath. And an ungameable metric is the whole game — plant the errors, hold the key, score once, and no detector can talk its way to a number.
What's next
Extend AutoSwarm to real verifiable-fact domains, widen the exploration operators, and let the swarm propose its own new lenses — always leads, not verdicts, always verifiable facts only.
Built With
- flask
- github
- html/css
- inngest
- javascript
- openai
- python
- svg
- vercel

Log in or sign up for Devpost to join the conversation.