-
-
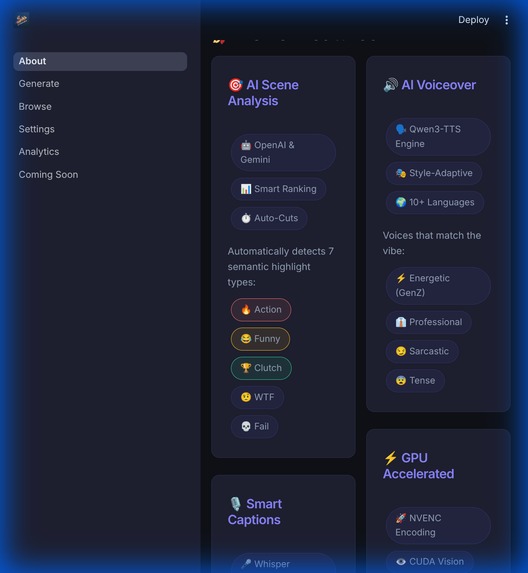
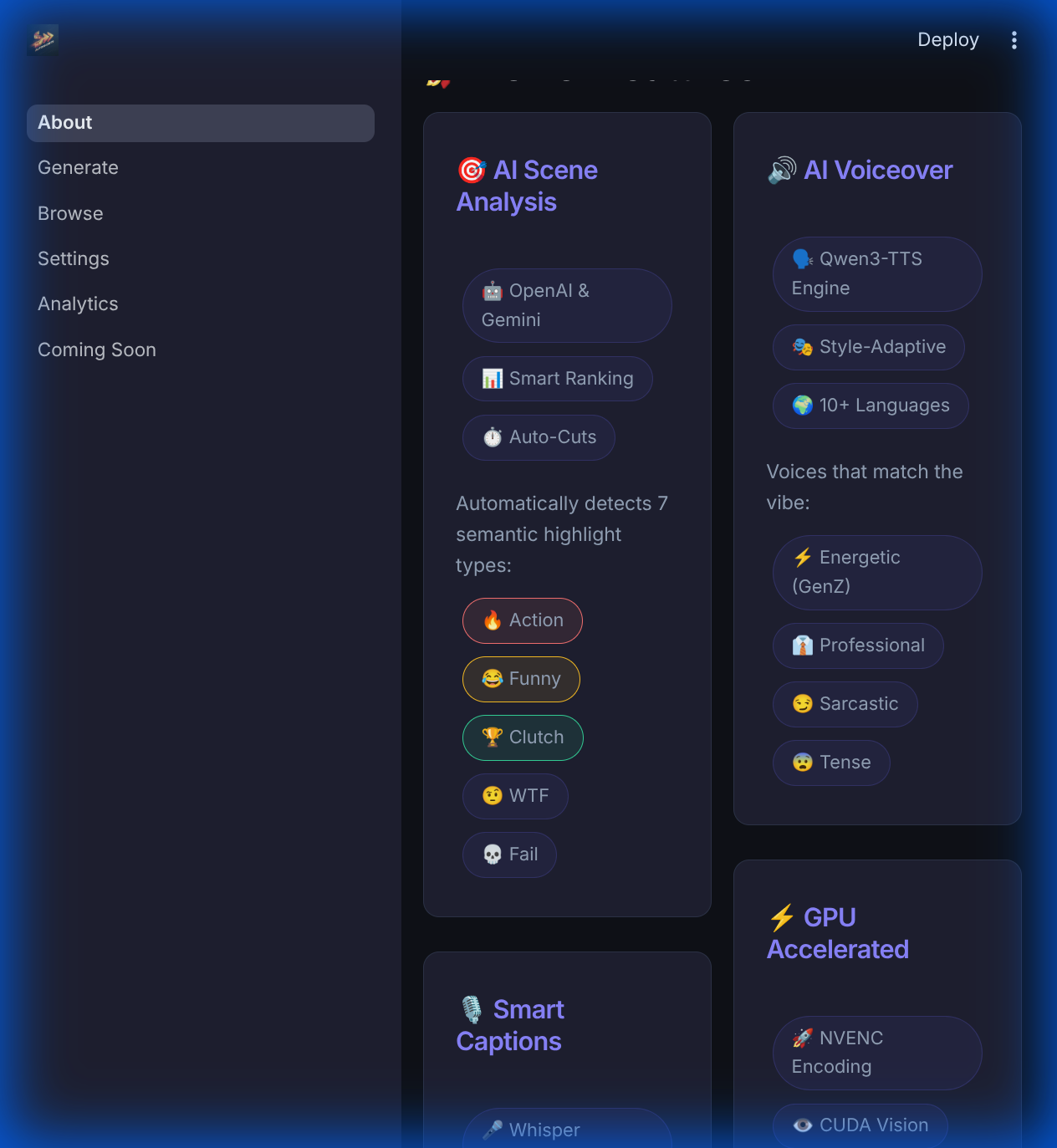
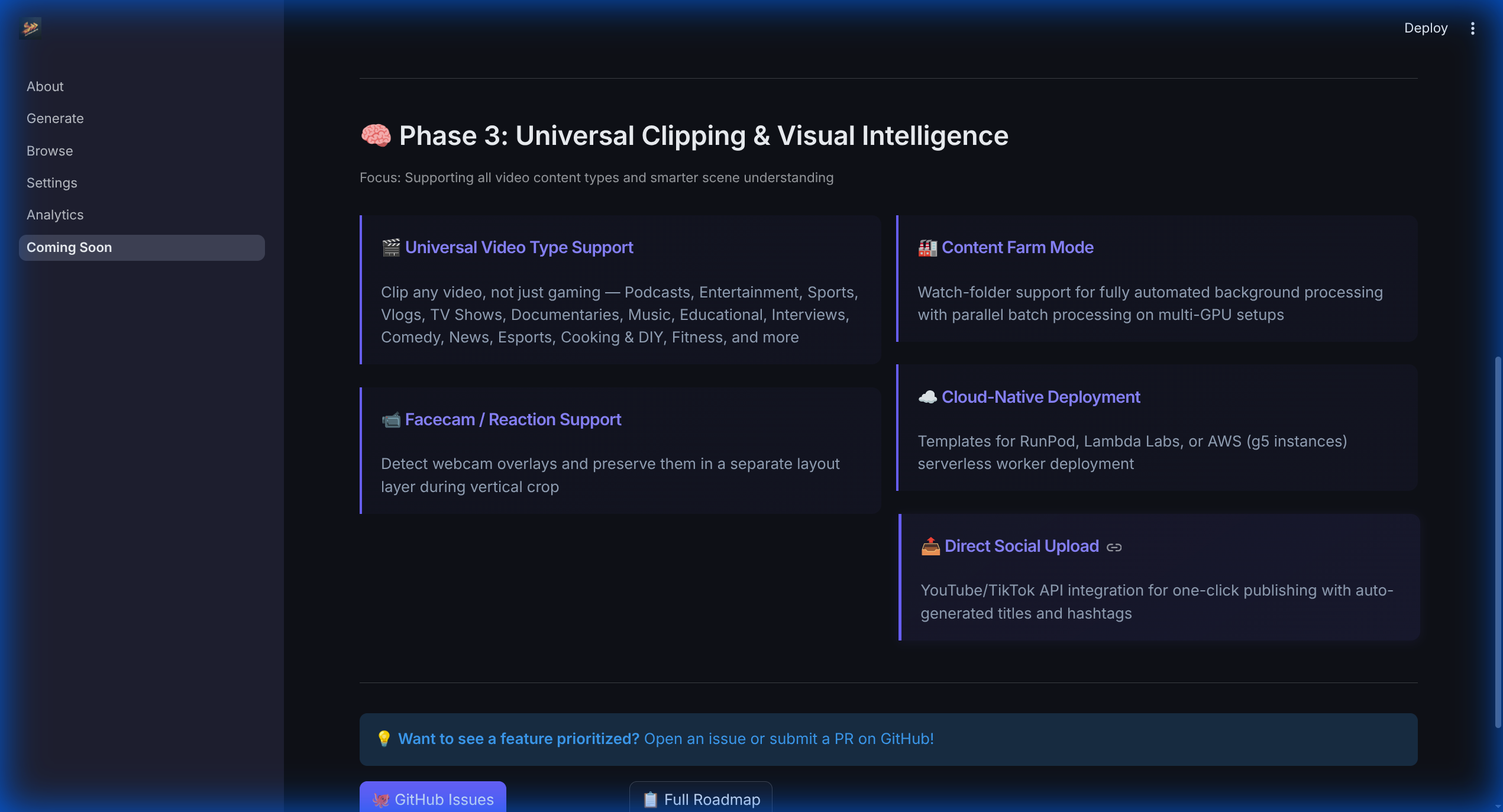
Beyond simple clips: Multilingual support, automated voice design, and narrative story modes for every platform.
-
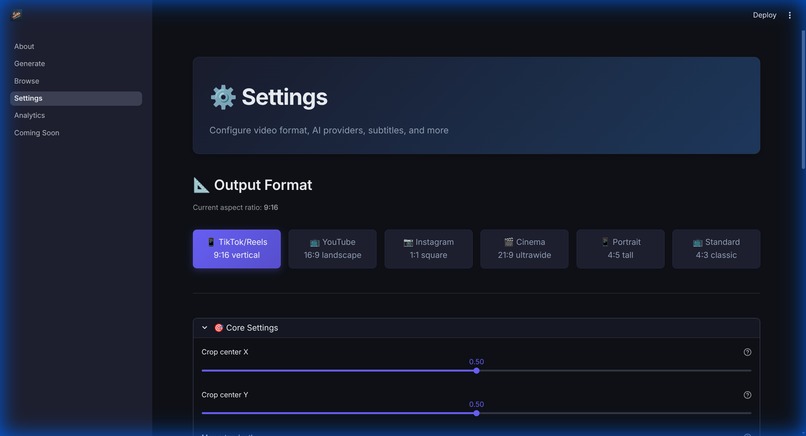
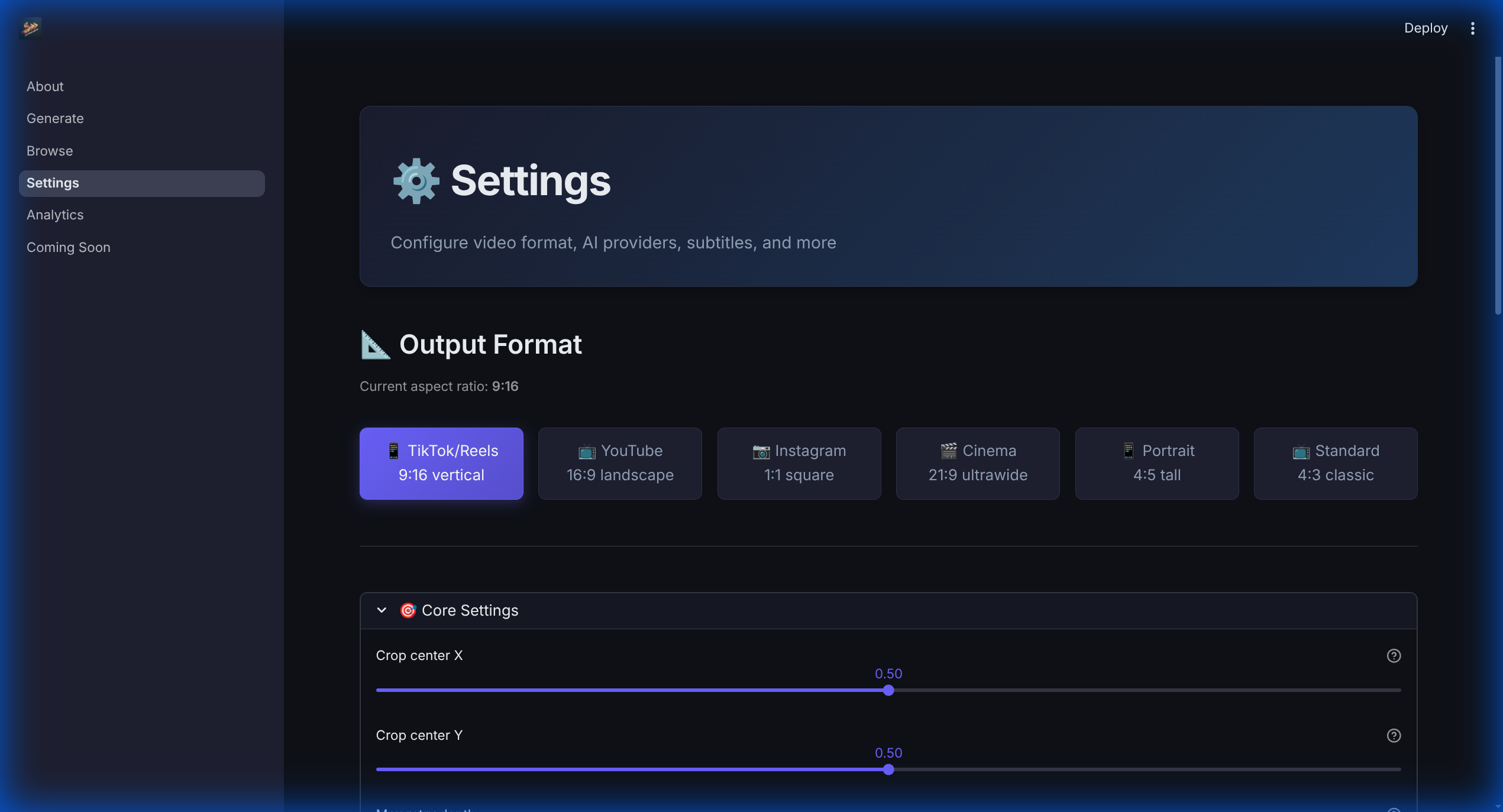
Fine-tune your workflow. Toggle between Local, OpenAI, or Gemini analysis and manage output formats.
-
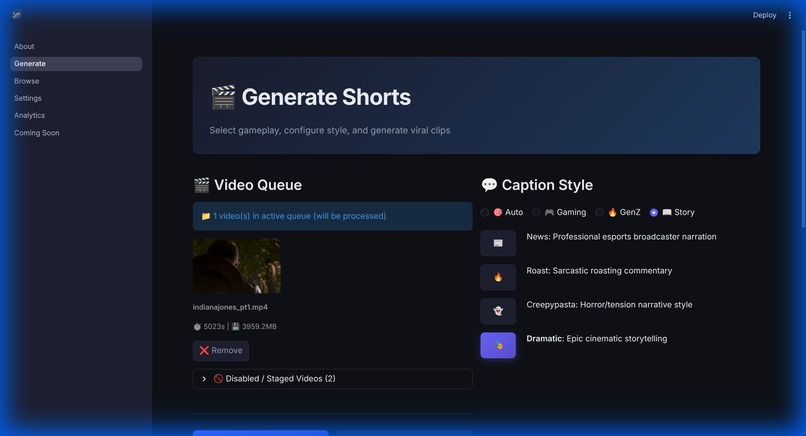
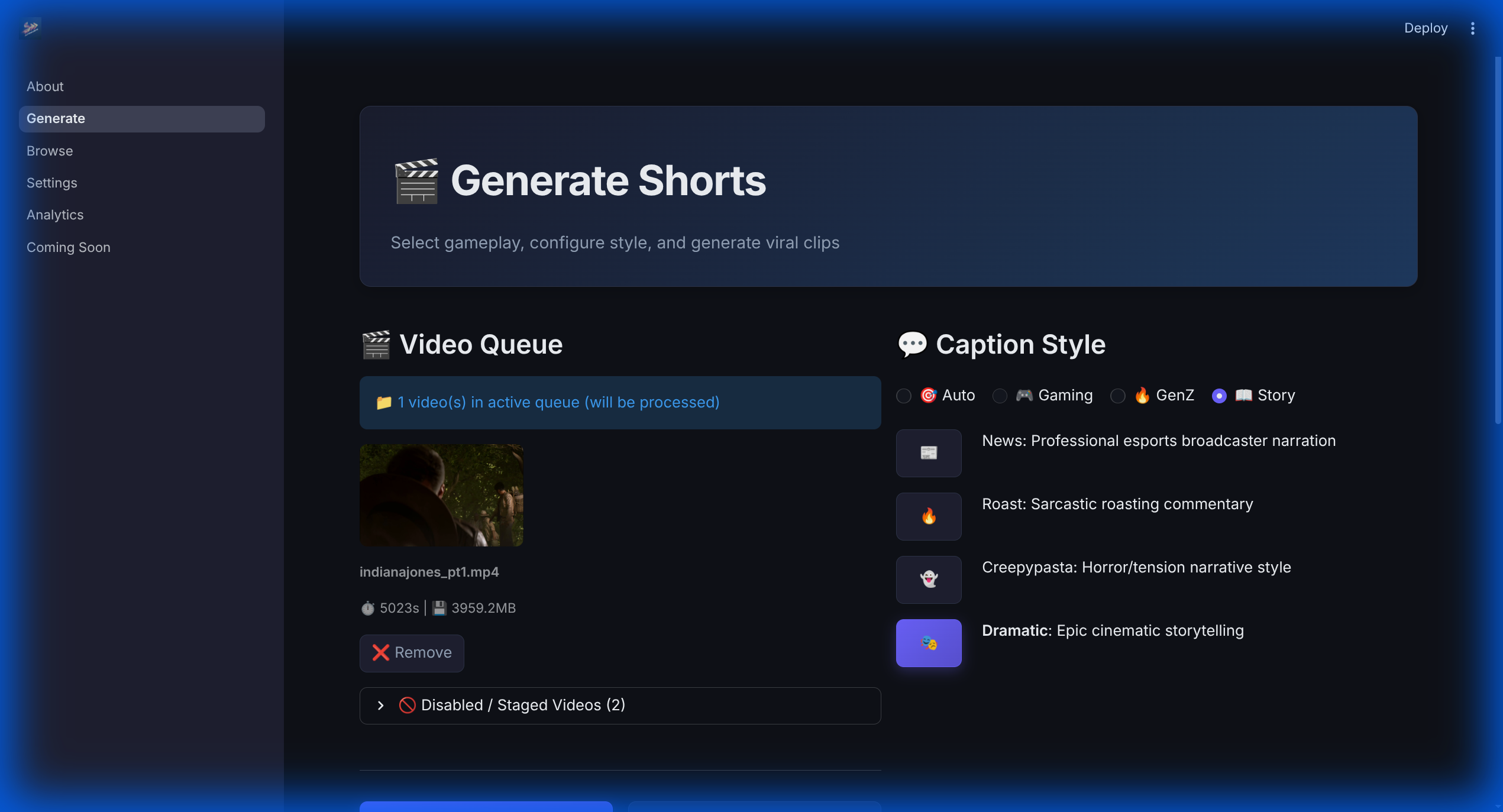
The command center. Drop raw VODs here to start the AI-powered scene detection and clip extraction pipeline.
-
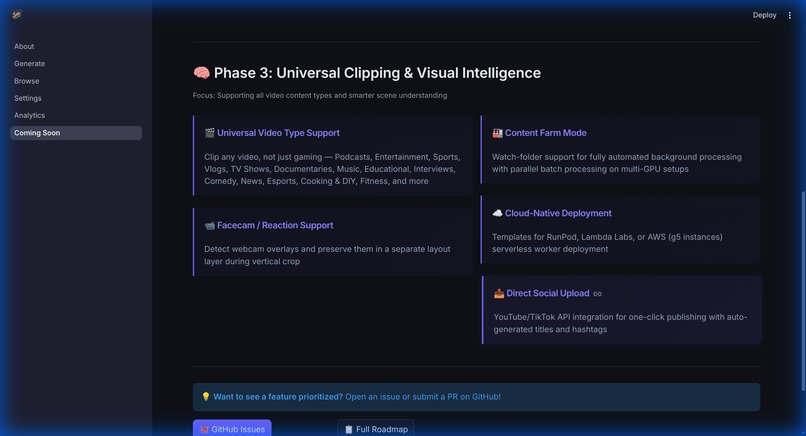
The roadmap: Real-time stream monitoring, SFX generation, and intelligent auto-zoom tracking are on the horizon.
-
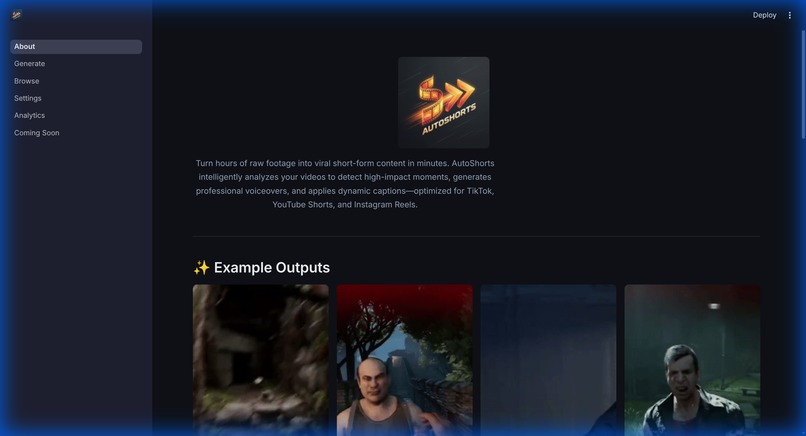
The vision behind AutoShorts: Eliminating the 4-hour editing grind so creators can focus on playing.
AutoShorts: The AI-Powered Gameplay Editor
Inspiration
Recording gameplay is easy; editing it is a nightmare. I was spending 4 hours editing for every 1 hour of footage—scrubbing through VODs for that one "clutch" moment. I built AutoShorts to flip the script: a system where you drop raw footage, walk away, and return to ready-to-upload, narrated clips.
What it does
AutoShorts is a GPU-accelerated AI pipeline that semantically understands gaming content. It identifies "action," "funny," and "WTF" moments, then automatically crops them to 9:16, adds AI-generated captions, and synthesizes high-energy voiceovers to match the game's vibe.
How I built it
The core is built with Python, leveraging PyTorch and CUDA for local execution.
- Vision Analysis: A hybrid system using local heuristics and Gemini/OpenAI vision models for semantic scoring.
- Voice Design: Qwen3-TTS for natural, personality-driven voice synthesis.
- Rendering: Optimized FFmpeg with NVENC hardware acceleration for fast vertical cropping and blurred backgrounds.
- Orchestration: Developed modular logic to manage complex model sequencing and pipeline flow.
🏗️ Intelligence & Customization
I built a dedicated settings layer to manage how the AI "thinks" and "talks," ensuring the tool adapts to the creator's specific needs.
🧠 Gemini Deep Analysis Mode
- The Proxy Trick: To keep costs low, the pipeline generates a low-res GPU-accelerated proxy (from 4K@60fps down to 640p@1fps).
- Semantic Context: It sends this lightweight stream to Gemini to identify narrative arcs or running jokes across hours of footage, which is more cost-effective than per-clip analysis.
✍️ Adaptive Caption Styles
The AI adapts its persona and visual styling based on the content:
- Story Roast: Sarcastic commentary on gameplay fails.
- GenZ Slang: High-energy, emoji-heavy captions with current lingo.
- Dramatic Story: A cinematic, serious narration for epic moments.
⚙️ Full Control
- Model Swapping: Users can toggle between OpenAI, Gemini, or Local Heuristics depending on budget and privacy needs.
- API Management: Integrated cost-management features allow users to set limits and avoid accidental credit drains.
Challenges I ran into
- The VRAM Juggling Act: Running LLMs, TTS models, and video rendering on a consumer GPU is a recipe for OOM crashes. I implemented an aggressive model lifecycle management system to explicitly unload models between pipeline stages.
- The TTS Timing Nightmare: Subtitles would drift over time. I solved this by switching from sentence-level probing to probing merged narrations and distributing timing proportionally.
- CJK Language Support: Standard word-based subtitle splitting failed for Japanese and Chinese. I built a custom character-based splitting logic with language detection.
What I learned
Building this taught me that "local-first" AI isn't just about privacy—it's about cost and latency. By using small proxy videos for cloud analysis and running heavy TTS/Rendering locally, I created a pipeline that is both powerful and affordable.
What's Next for AutoShorts
- Universal Video Support: Expanding beyond gaming to podcasts and sports.
- SFX Generation: Integrating AI-generated sound effects matched to on-screen action.
- Cloud API Mode: Designing a "submit URL, get clips" architecture.
- Live Stream Monitoring: Researching real-time highlight extraction for live broadcasts.
Log in or sign up for Devpost to join the conversation.