-
-
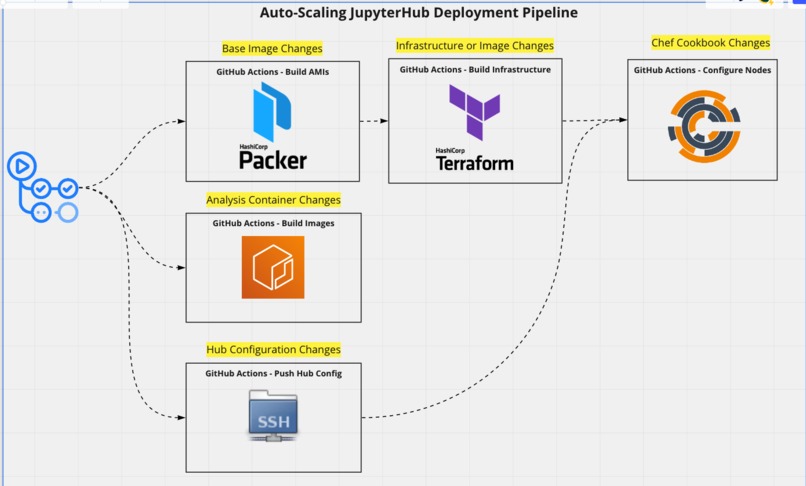
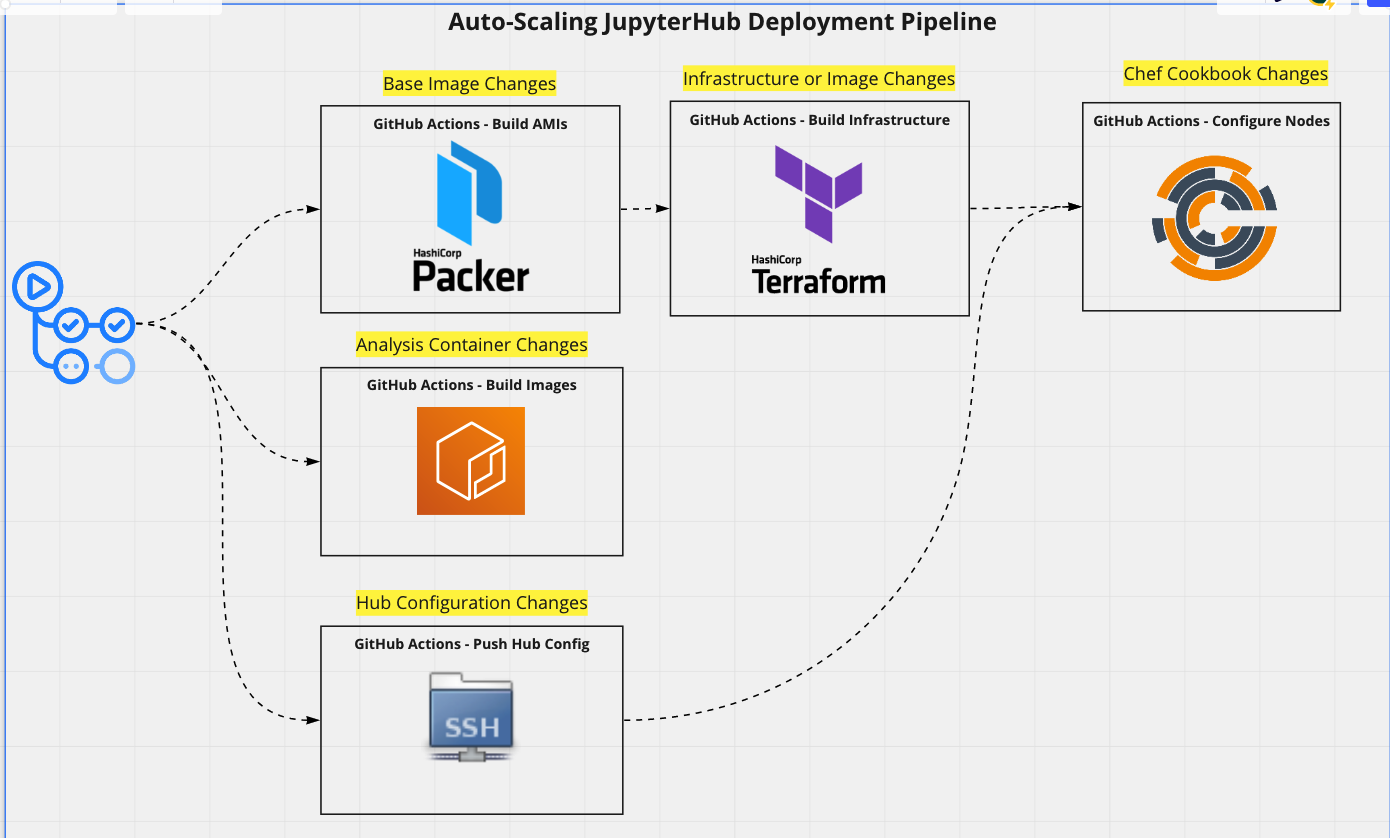
The CI uses a combination of Packer, Terraform, and Chef to deploy our Hub cluster
-
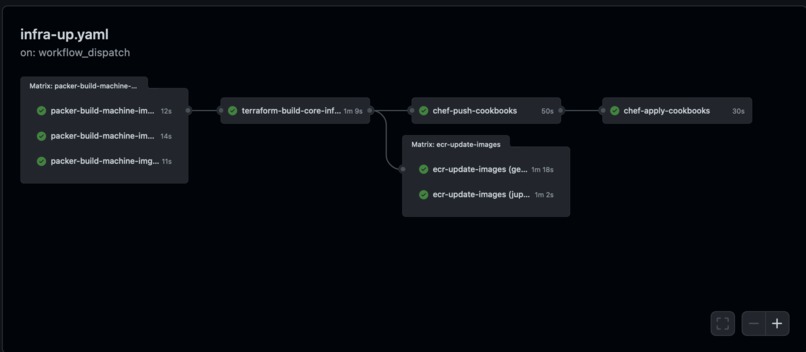
The GitHub CI - Build Infra Workflow
-
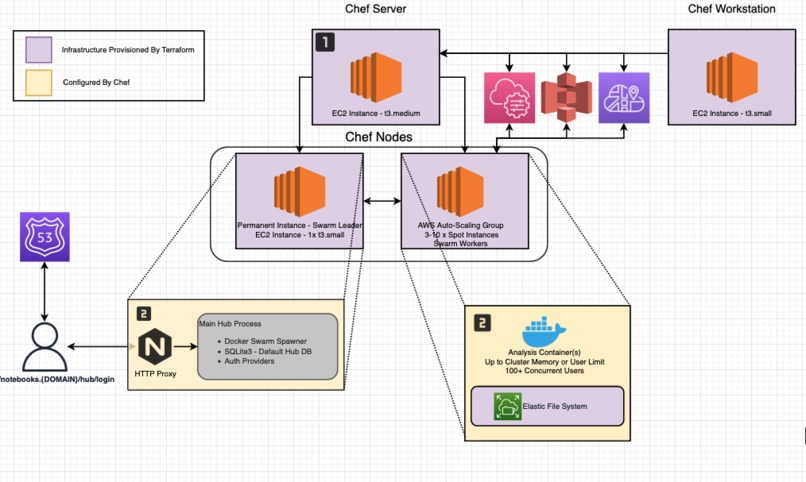
Once the Instances are ready, Chef provisions Nginx, JupyterHub, and Docker
-

Hub can be configured such that non-standard packages (i.e. for ML, GIS, Bioinformatics) are built into the launch image
-
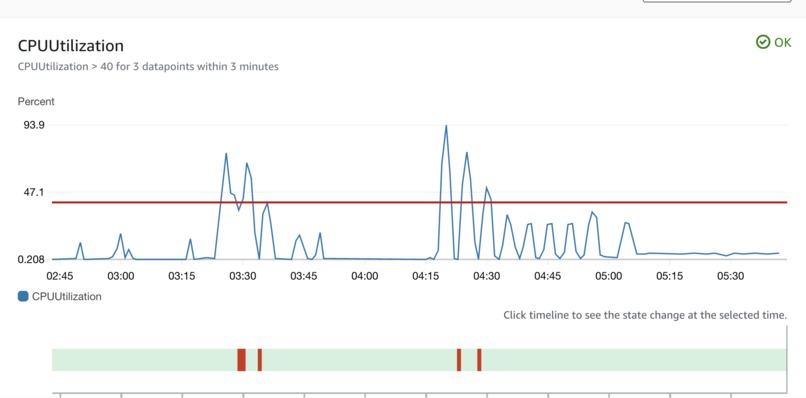
The total CPU usage of the cluster can be tracked and used to guide the ASG's instance count
-

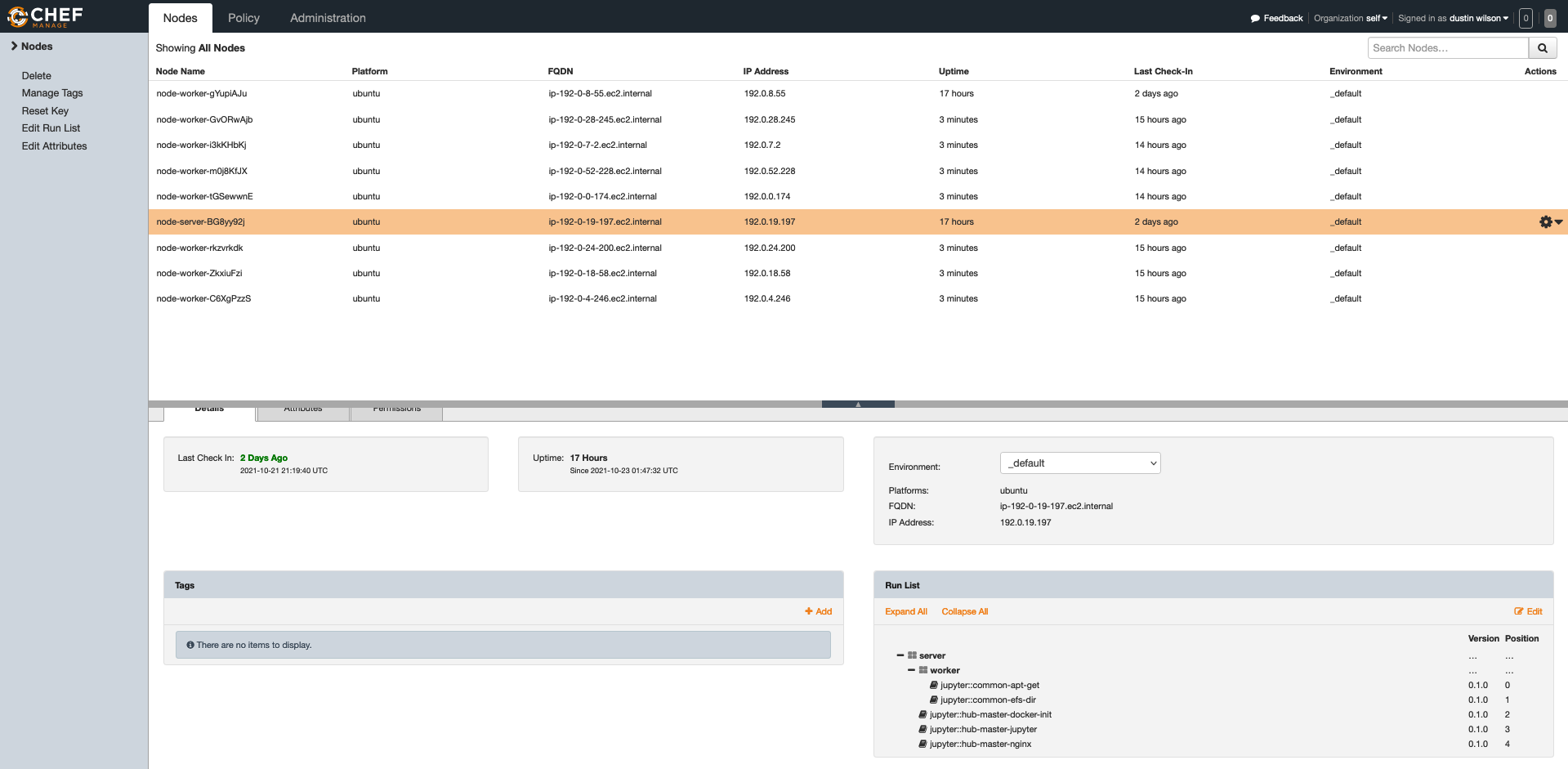
Chef Server manages the Jupyter Server and Jupyter Worker nodes


Inspiration
JupyterHub is a Python application that runs in the cloud or on your own hardware, and makes it possible to serve pre-configured data science containers to multiple users. It is customizable and scalable, and is suitable for small and large teams, academic courses, and large-scale infrastructure.
However, JupyterHub traditionally depends on one of two configurations. Either a vertically-scaled single node deployment (ironically named, "The Littlest JupyterHub") or a Kubernetes deployment. For many users, especially in education, both a single node or K8s deployment can quickly become impractical.
Consider a lab session with 100+ students on a large single node instance, the instance would be deeply underutilized for all but a few hours a week. If the machine was under-provisioned, it may be unable to meet demand during the lab sessions with many concurrent users. K8s presents a viable alternative if you're willing to maintain it, but I propose an alternative solution.
What it does
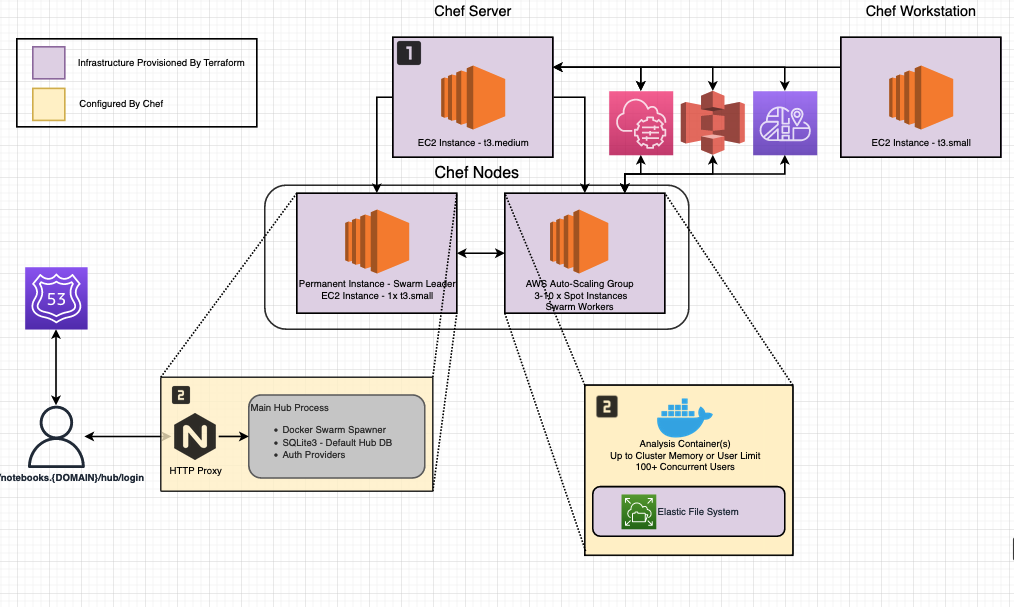
This project uses Terraform, Packer, GHActions, Chef, and Docker Swarm to provision and deploy a JupyterHub instance backed by an EC2 Auto-Scaling Group (ASG) instances with a shared NFS (AWS EFS) file-system.
As an added bonus, the system also creates Chef Server, Chef Client, and Chef Workstation AWS AMIs, with recent Ubuntu and Chef Software versions. You can use in other deployments if you'd like, I found the Chef Client AMI very helpful when bootstrapping new auto-scaling nodes quickly.
The system has two components. First, a Jupyter Hub instance, this instance is permanent and is the Docker Swarm Manager, all hub requests are routed through this instance. The second is a cluster of ASG instances. As CPU usage increases (could easily add a memory usage rule as well), the new instances join the Chef Server with role "worker". From there, each node's recipes configure it to join the Docker Swarm. Once joined, that node can be used as a deployment target for new user's analysis notebook containers.
Because we expect ASG nodes to scale in and out with traffic, it's reasonable to purchase these instances from the AWS spot market. This is a risky choice for some use-cases, but for simple exploratory analysis, worth the occasional restart!
How we built it
See architecture slides above. I used Packer, Terraform, Github Actions, and Chef to deploy the system.
Chef - To configure the cluster's instances, install applications, and manage their state.
Packer - To create machine images for Chef Workstation, Chef Nodes, and Chef Server. This was important as it allows ASG nodes to come up much quicker because they're pulling an AMI with Chef instead of installing Chef themselves.
Terraform/AWS - Provision core infrastructure, e.g. VPC, Subnets, Security Groups, IAM profiles, NFS, and EC2 instances.
Github Actions - Run the CI jobs for the deployment of the system
Challenges we ran into / Accomplishments that we're proud of
Provisioning Chef Servers - Doing this from Terraform was quite difficult at first. Particularly, ensuring that instances came up at the right time and their dependencies user-data scripts had finished successfully. I was able to come up with a temporary solution using SSM Documents to call
cloud-init status --wait, but this solution still felt over-engineered for what it was doing. This snag pushed me towards using Packer to pre-build custom Chef AMIs instead.JupyterHub Configuration - JupyterHub is very configurable, and this can be confusing even if you've brought up a service like this before. In a real deployment, a researcher/engineer/educator would need to carefully read through the docs to get just the right configuration for them. In this instance though, I just needed a viable demo configuration, which I was able to achieve with a few
t3.smallandt3.mediumnodes.De-registering Nodes - As of writing, both Chef Server and Docker Swarm don't have an intelligent way to de-register ASG nodes when they drop off. This can make management of nodes confusing, especially when there's high churn.
What we learned
Chef - Period. Before this event I hadn't used Chef at all. I work as a data engineer and I provision database clusters with other IAC tools, but I'm glad that I got to have this experience.
Packer - This was my first time deploying AMIs with Packer, it's a nice tool and I'd love to use it a bit more. I didn't anticipate building any custom AMIs when I started this project, but glad that I ended up here.
What's next for Autoscaling JupyterHub
Hardening - Hardening or security were admittedly not my top priority here. I'd want to go through and audit the choices made and tighten those up. I'd also probably want to integrate Inspec into the CI.
Isolation of Clusters/Decoupling of Chef and Jupyter Deployment - The way my Terraform and CI is written implies there will be one and only one Jupyter cluster per Chef Server. In practice, only one Chef Server is needed for many jupyterhub clusters (we know Chef is more than capable of managing 100+ nodes). In theory, an engineer should be able to run
terraform applyin one module to bring up a Chef Server and Workstation, andterraform applyin another to bring up a JupyterHub cluster (or 10, one for each lecture in the department) backed by an ASG. For this, I'd need to split code into multiple modules and just be mindful about module outputs/variables.
Additional Note on Lock-In: There is no reason this deployment needs to be on AWS. At the core of this system is Packer (which can use Linode, GCP, Digital Ocean, etc.) as a target build environment, Terraform (which can provision for most major cloud providers), and Chef (which is of course completely agnostic to what hosting is used. Each of these providers also has object storage, and some sort of concept analogous to AWS' auto-scaling nodes.
Built With
- chef
- docker
- docker-swarm
- jupyter
- packer
- terraform

Log in or sign up for Devpost to join the conversation.