-
-
Autorunbook- AI powered Production engineer
Inspiration
As a GenAI developer, I can build models. But I realised I had no idea how to keep them alive in production. This hackathon challenged me to bridge that gap. The question that drove AutoRunbook was simple: what if a production service could diagnose its own failures and write its own fix instructions? That question became this project.
What it does
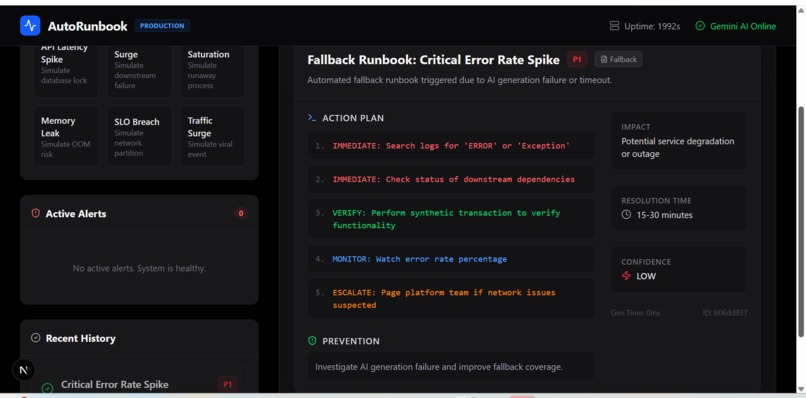
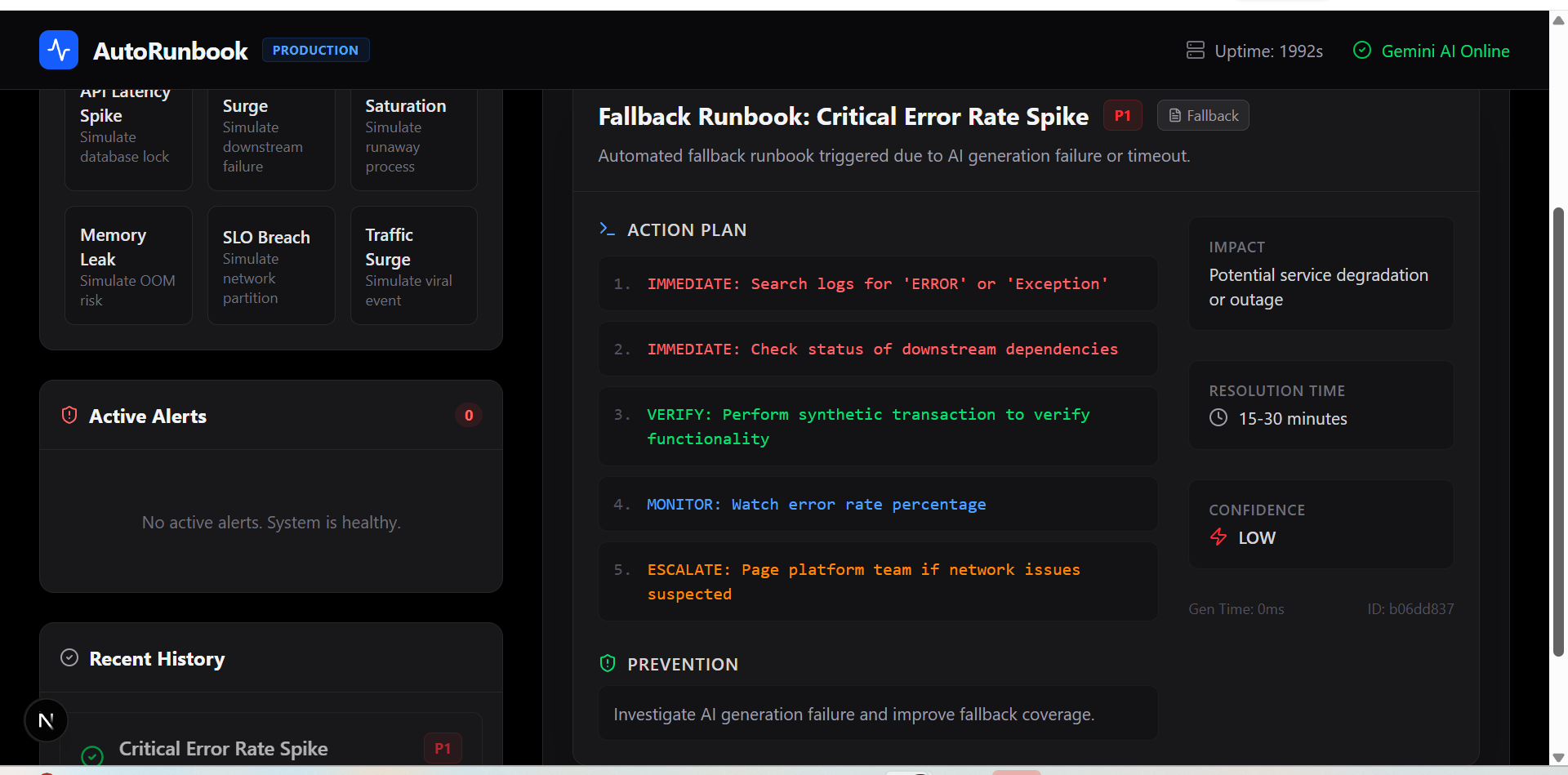
AutoRunbook monitors 6 live production metrics in real time. When any metric breaches a threshold, ARIA — a Google Gemini powered SRE brain — automatically generates a complete incident runbook with root cause analysis, severity classification (P1/P2/P3), 5 immediately executable fix steps, user impact assessment, and a prevention recommendation. All in under 10 seconds with no human intervention.
Key features:
- 6 live metric dashboard: error rate, p99 latency, CPU, memory, availability, and requests per second
- 9 alert threshold rules covering all golden signals
- 6 chaos engineering scenarios: API latency spike, 500 error surge, CPU saturation, memory leak, SLO breach, and traffic surge
- Circuit breaker fallback — serves a pre-built runbook instantly when Gemini is unavailable so the service never fails
- Full alert history and incident timeline
- Health and readiness endpoints
- Structured JSON logging throughout every layer
How we built it
Stack: Next.js 14, TypeScript, Google Gemini 1.5 Flash, prom-client, Docker, Google Cloud Run
Architecture: Next.js API routes handle all backend logic from a single deployable container. An in-memory store tracks live metrics and active alerts. An alert engine polls all 9 threshold rules every 15 seconds. When a breach is detected, the Gemini API is called with a precision-engineered system prompt using temperature 0.1, topP 0.8, and topK 10 — tuned specifically for consistent, reliable, production-safe outputs rather than creative responses.
ARIA — the Gemini system persona — is instructed to never guess, never hallucinate terminal commands, and use an INVESTIGATE prefix when uncertain. This makes every generated runbook safe to execute in a real production environment without human review.
On any AI failure, timeout, or invalid response, a circuit breaker silently activates and serves a pre-built fallback runbook. The user never sees an error. The service never goes down.
Challenges we ran into
Gemini returning markdown-wrapped JSON — the API occasionally wraps responses in code blocks. Solved by building a response cleaner that strips all markdown before parsing, preventing silent failures.
Environment variable access in serverless context — Next.js API routes run serverlessly where module-level initialisation fails unpredictably. Solved by moving all API key reads inside function bodies at runtime.
Alert re-triggering loop after resolve — metrics were not resetting after resolve, causing the same alert to re-fire immediately and always hit the fallback before Gemini could respond. Solved by adding synchronous metric reset to the resolve endpoint.
Making AI output safe for real production use — GenAI models can hallucinate commands that do not exist. Solved through strict prompt engineering with explicit instructions that prevent invented terminal commands from appearing in runbooks.
Accomplishments that we're proud of
Built a fully working production-grade service solo in one night as a GenAI developer with no prior DevOps or SRE background.
Implemented a genuine circuit breaker pattern — the service degrades gracefully and continues serving runbooks even when the AI provider is completely offline. Zero downtime under any failure mode.
Engineered a Gemini system prompt that produces consistent, structured, production-safe runbooks reliably — treating prompt engineering as production configuration, not creative writing.
Connected two worlds that are often treated as separate: GenAI development and production engineering. AutoRunbook proves they are the same discipline at different layers.
What we learned
Production engineering is not about avoiding failure. It is about designing systems that fail gracefully when they inevitably break.
GenAI in production requires the same reliability thinking as any other critical service — fallbacks, timeouts, circuit breakers, and structured error handling are not optional.
Prompt engineering is production configuration. Temperature, topP, topK, and system instructions directly determine whether AI output is reliable enough to trust in an incident. These are engineering decisions, not creative ones.
Observability is the foundation of everything. Without metrics you cannot detect. Without detection you cannot respond. Without response you cannot recover. Every other feature in this project depends on that foundation.
The gap between a demo and a production system is one try/catch block, one fallback function, and one health endpoint. That gap is everything.
What's next for AutoRunbook
Real Prometheus and Grafana integration for monitoring actual infrastructure instead of simulated metrics.
Slack and PagerDuty webhook integration so ARIA delivers runbooks directly to on-call engineers the moment an alert fires.
Multi-service architecture support — monitor entire microservice clusters and correlate alerts across services to identify cascading failures.
Runbook learning loop — ARIA improves its recommendations over time based on which fix steps actually resolved past incidents, building institutional knowledge automatically.
Production deployment pipeline with CI/CD, automated load testing, and chaos testing on every merge — making AutoRunbook itself a demonstration of the principles it teaches.
Built With
- docker
- google-cloud-run
- google-gemini-1.5-flash-api
- next.js-14
- node.js
- prom-client
- react
- rest
- typescript

Log in or sign up for Devpost to join the conversation.