
About Autoreduce
Autoreduce is a distributed autoresearch harness for large-scale ML systems. The core idea is to use coding agents, sealed benchmarks, and elastic GPU scheduling to search not only over what algorithm works, but also where that algorithm works best.
We were inspired by projects like Andrej Karpathy’s autoresearch, where an agent can edit code, run experiments, and keep improving over time. We also looked at elastic compute systems that make it easier to run many independent experiments across GPUs. But we noticed a gap: in large-scale ML systems, the experiment itself often changes when you scale it.
For example, a speculative decoding strategy might look weak on one GPU because candidate branches are serialized, but become strong on four GPUs when candidate generation can be parallelized. A batching strategy might improve average throughput but fail p95 latency. A low-bit search method might only be useful when cheap candidate generation is spread across GPUs and BF16 verification is reserved for the best candidates.
So instead of only asking:
$$ \text{What should the agent try next?} $$
Autoreduce also asks:
$$ \text{At what resource scale should this idea be measured?} $$
What we built
Autoreduce separates research reasoning from GPU execution.
The system follows this loop:
Goal
→ Planner
→ Agents
→ Experiments
→ GPU Scheduler
→ Sealed Benchmark
→ Scale Curves
→ Planner Digest
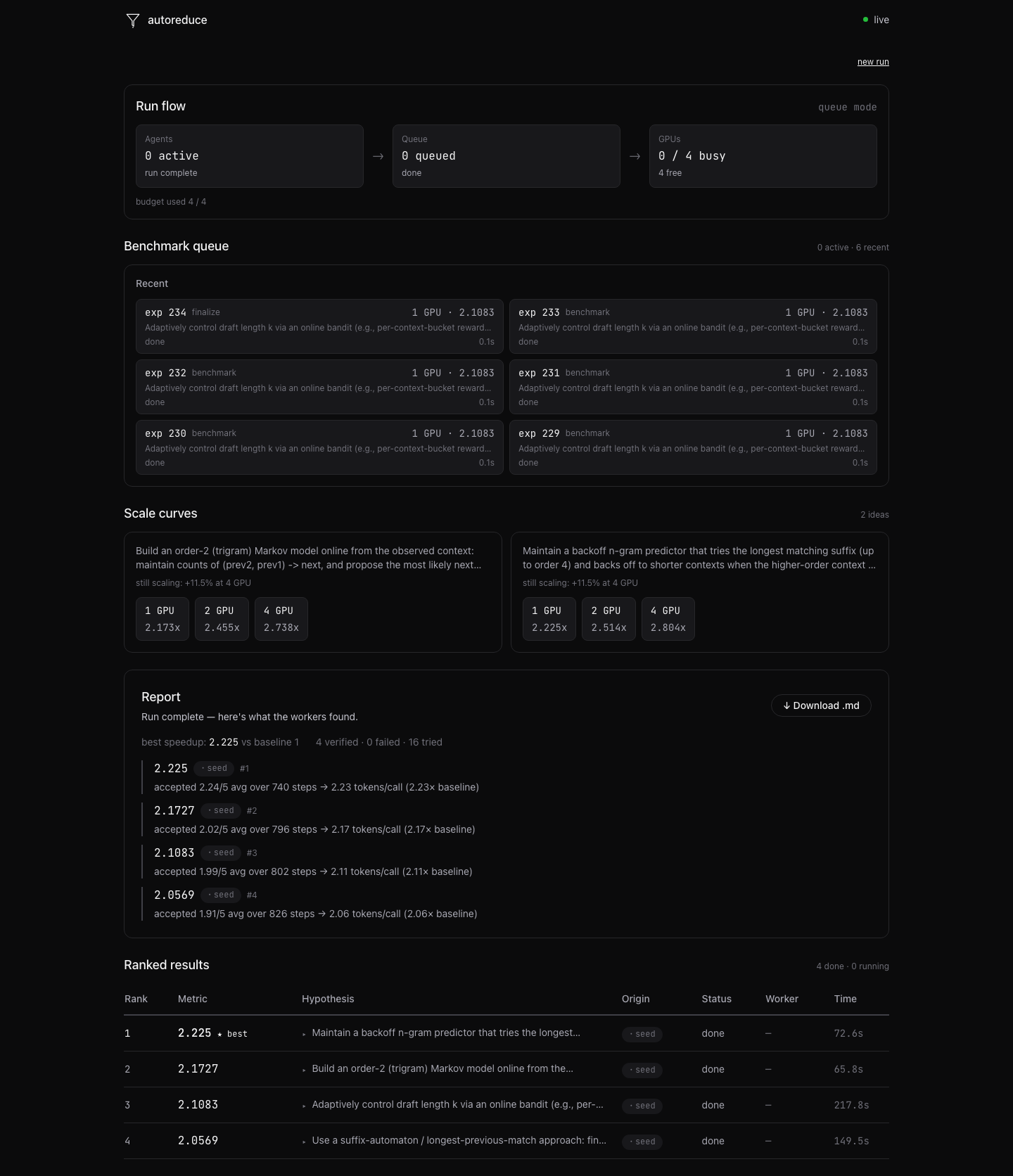
The planner proposes research hypotheses. Agent workers claim those ideas and write method.py implementations. Each method becomes an experiment with a workload shape and resource shape. The GPU scheduler decides whether to run that experiment as a cheap one-GPU test, a two- or four-GPU scale probe, or an eight-GPU validation. Benchmark workers run the sealed measurement and report trusted metrics back to the planner.
The two main optimization layers are:
Agent elasticity Agents do not permanently own GPUs. They can think, write code, and prepare experiments while GPU benchmark jobs run separately. This means one GPU can still support multiple active agents, as long as only one benchmark runs at a time.
Experiment elasticity Some methods need multiple GPUs to be measured correctly. Autoreduce can allocate 1/2/4/8 GPU bundles to promising experiments and build scale curves, instead of ranking every idea only by its one-GPU result.
The trust boundary is also important: agents write methods, but the sealed benchmark owns the metric. Agents cannot simply claim a speedup. The system measures the final method and only then updates the leaderboard.
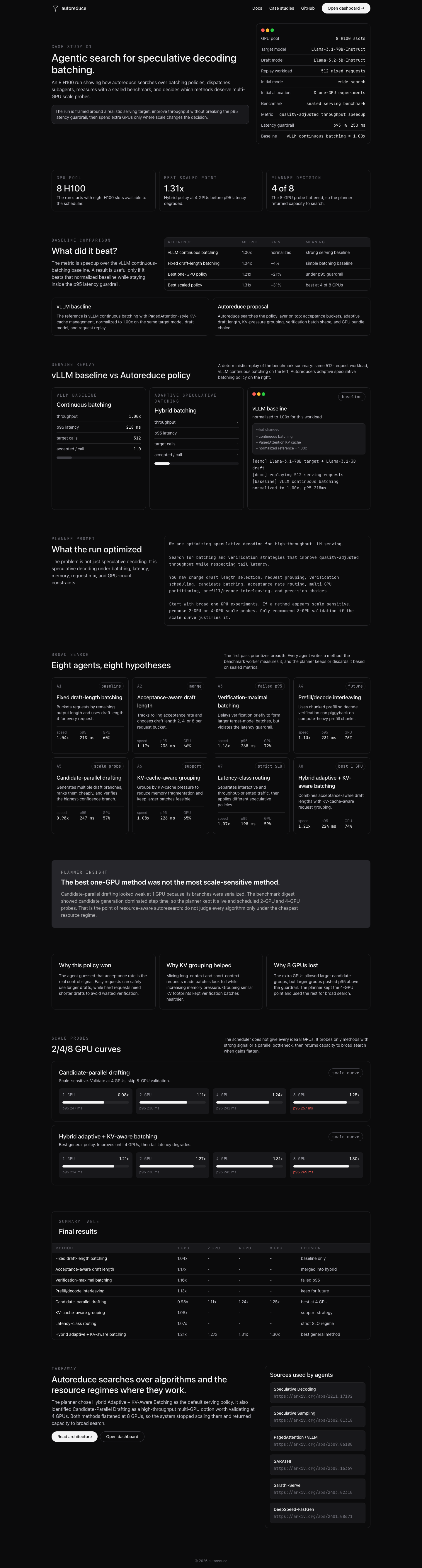
Case study: speculative decoding batching
Our main demo focused on speculative decoding batching. We chose this problem after visiting Etched and speaking with their Chief Architect, Saptadeep Pal, who mentioned the combinatorics problem around batching for speculative decoding.
Speculative decoding is not just “use a draft model and go faster.” In real serving workloads, every request can have a different prompt length, decode length, acceptance rate, latency class, and KV-cache pressure. The system has to decide how to group requests, how many draft tokens to propose, when to verify with the target model, and whether the best policy changes across GPU counts.
We prompted Autoreduce to optimize speculative decoding for high-throughput LLM serving using:
Target model: Llama-3.1-70B-Instruct
Draft model: Llama-3.2-3B-Instruct
Workload: 512 mixed ShareGPT-style requests
Goal: improve quality-adjusted throughput while keeping p95 latency under 250 ms
Baseline: vLLM continuous batching normalized to 1.00x
The agents explored strategies like fixed draft-length batching, acceptance-rate-aware draft length, verification-maximal batching, prefill/decode interleaving, candidate-parallel drafting, KV-cache-aware grouping, and hybrid adaptive batching.
The most interesting result was candidate-parallel drafting. On one GPU, it looked weak because the candidate branches were serialized. But the planner detected that candidate generation was the bottleneck and scheduled multi-GPU scale probes.
The scale curve looked like:
1 GPU → 0.98x
2 GPUs → 1.11x
4 GPUs → 1.24x
8 GPUs → 1.25x
The planner learned that four GPUs gave almost all the benefit, while eight GPUs added little and hurt the p95 latency guardrail. A flat one-GPU leaderboard would probably discard this idea. Autoreduce kept it alive long enough to discover the resource regime where it actually worked.
Second case study: low-bit search, BF16 render
We also tested a second problem space: low-bit candidate search followed by BF16 verification or rendering. This was inspired by low-bit inference and quantization work such as QLoRA, AWQ, FP8 formats, and microscaling formats.
The idea is to generate many cheap candidates in FP4, NVFP4-style, or FP8 precision, then verify or rerender only the best candidates in BF16. This pattern appears in best-of-N inference, test-time search, RL-style inference-time optimization, and world-model rollouts.
Again, the key question was not just which method was best, but where extra GPUs stopped being useful. The best policy improved through four GPUs, then flattened at eight GPUs, showing that the useful result was not “use all GPUs,” but “find the point where extra compute stops helping.”
What we learned
The biggest lesson was that autoresearch for ML systems needs more than a ranked table. It needs scale curves.
A method’s quality is not just:
$$ \text{score}(\text{method}) $$
It is closer to:
$$ \text{score}(\text{method}, \text{GPU count}, \text{batch size}, \text{precision}, \text{workload}) $$
That shift changes how the planner should reason. It should not blindly allocate more GPUs, and it should not blindly discard weak one-GPU ideas. It should ask which measurement would reduce uncertainty the most.
We also learned that scheduling agents and scheduling GPUs are different problems. Agents can run ahead of measurement, but only up to a point. If the benchmark queue gets too long, the agents are reasoning from stale information. If the benchmark queue is empty, the GPUs are underused. Balancing those two loops became one of the most interesting parts of the project.
Challenges
The hardest part was designing the system so that it stayed trustworthy while becoming more elastic. If agents can write code and request benchmarks, the system needs a strong boundary between what the agent controls and what the benchmark controls.
We solved this by keeping measurement sealed. Agents can write method.py, but they cannot edit the benchmark, baseline, or result fields. In the decoupled architecture, even benchmark requests go through the experiment queue, so the scheduler controls when and where the measurement happens.
Another challenge was making the architecture general enough for multiple problem spaces. Speculative decoding, low-bit search, distributed training, and world-model inference all have different metrics and resource shapes. We handled this by separating ideas from experiments. An idea is the hypothesis. An experiment is a concrete measurement of that idea under a specific workload and resource shape.
Conclusion
Autoreduce is our attempt to make autoresearch work for the kinds of ML systems where algorithms, batching, precision, memory, and GPU topology are all coupled.
Agents generate methods. The scheduler allocates compute. The sealed benchmark produces trusted metrics. The planner learns from scale curves.
The main takeaway is simple:
$$ \text{Autoreduce searches over what to try and where it works.} $$
Built With
- agent
- anthropic
- api
- claude
- css
- fastapi
- httpx
- next.js
- pydantic
- python
- react
- sdk
- sqlite
- tailwind
- typescript
- uvicorn


Log in or sign up for Devpost to join the conversation.