Inspiration
It's 2035. The last software engineer was laid off on a Tuesday. The severance package included a complimentary subscription to MasterClass. So a coder, grieving, starts thinking about a rap career. He buys a microphone. He writes sixteen bars about his Phantom Pain 😔 in his favorite game, Roblox. The problem reveals itself immediately: coders have no sense of rhythm. Every take lands a little ahead or behind the beat, never quite locked in.
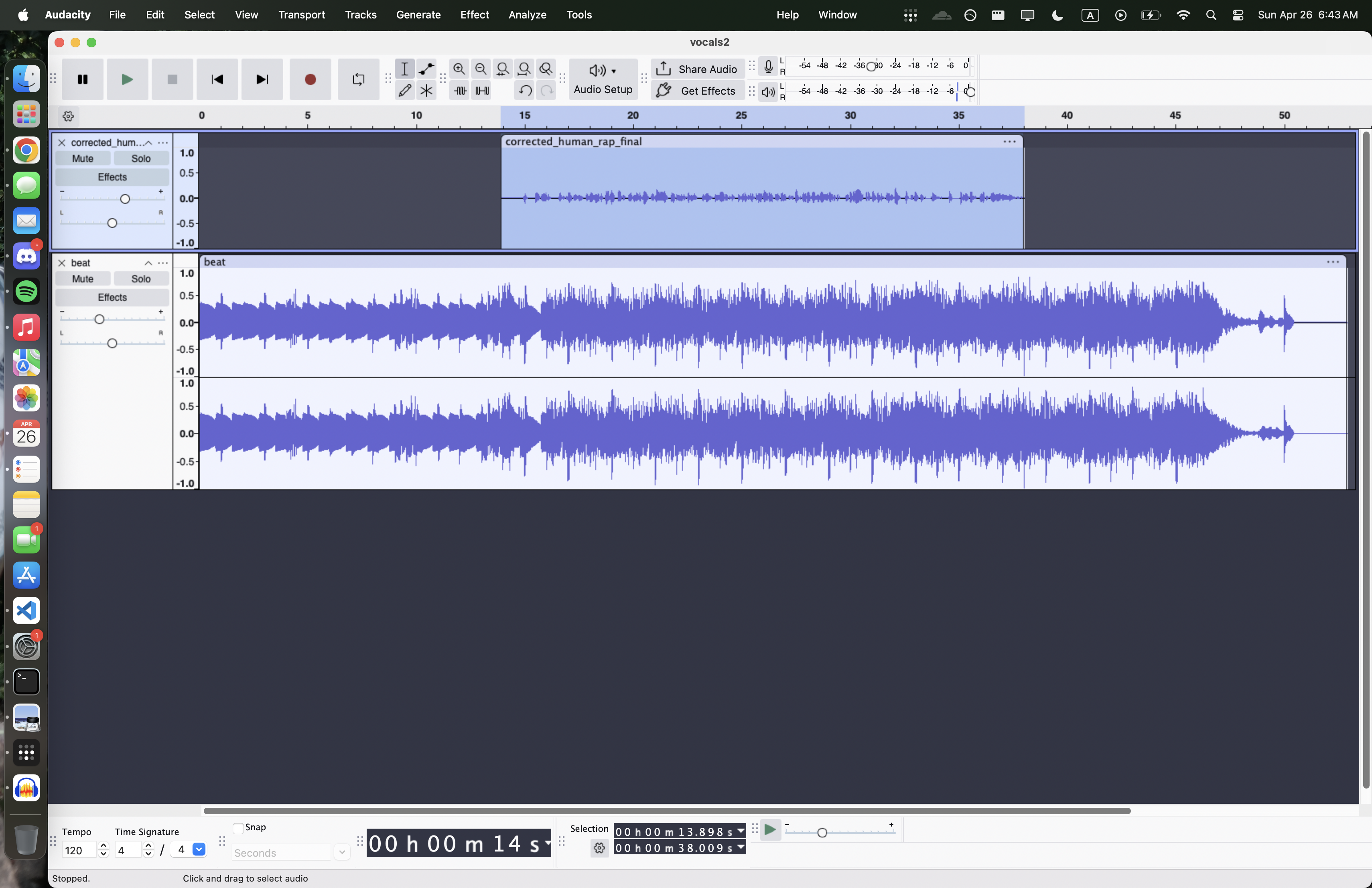
This is, of course, also a real problem for real producers. In a professional studio, an engineer fixes timing by hand, slicing and nudging syllables in a DAW for hours per song. We wanted to automate that work without touching the voice itself. No autotune, no AI vocal cloning, no black box that hands back a stranger's performance. Just precise, syllable-level rhythm correction you can open in Audacity and inspect line by line.
What it does
AutoRapper takes three inputs (a backing track, a dry rap vocal, and lyrics) and produces a rhythmically corrected version of the vocal where every syllable lands exactly on beat. It works in two modes:
- Guide mode: an AI-generated rap vocal serves as a timing reference. The human vocal's syllable anchors are mapped to the AI guide's timing with zero-sample error: not "close enough," but mathematically exact.
- Beat-only mode: detects BPM from the backing track and snaps syllables directly to the beat grid. No guide vocal needed.
The output isn't just a corrected WAV file. It's a full Audacity session with visible clips, label tracks, and waveforms that you can inspect, tweak, and override. Every edit is transparent and reversible.
How we built it
The pipeline has 9 phases, each with a clear boundary between "AI allowed" and "deterministic only":
- Phases 0–3 (AI allowed): We use ACE-Step 1.5 to generate an AI guide vocal from lyrics, Demucs for vocal isolation, CMUdict + G2P for automated syllable detection, and Montreal Forced Aligner for phone-level forced alignment on both the guide and human vocals.
- Phases 4–8 (fully deterministic): Syllable anchor mapping, safe-boundary clip grouping, piecewise time-warp planning, Rubber Band pitch-preserving time-stretch rendering, and Audacity session assembly via
mod-script-pipe. No neural model touches the human voice past Phase 3.
We built it in Python with uv for package management, a Flask + pywebview interactive syllable editor with wavesurfer.js waveforms, and a studio launcher that opens Audacity and the editor side-by-side. The codebase is around 4,600 lines of source with 168 passing tests.
Challenges we ran into
- MFA on rap vocals: Montreal Forced Aligner is designed for read speech, not rapid-fire rap delivery. We added multi-pronunciation support, energy-based fallback for missed vowels, and phoneme smoothing to get reliable syllable timestamps from stylized performances.
- AI guide lyrics fidelity: ACE-Step doesn't always sing every word. It sometimes skips or merges lyrics. We iterated on BPM settings, duration, and captions to improve coverage, and built a manual guide fallback for when generation misses words.
- Extreme stretch ratios: when human and guide timing diverge significantly, some syllables need 15x stretch or 0.1x compression. We added configurable ratio bounds and safe-boundary grouping to minimize audible artifacts at these extremes.
- 8 GB VRAM constraint: running ACE-Step + Demucs on an RTX 3070 required CPU offloading for model components and tiled VAE decoding to stay within memory limits.
Accomplishments that we're proud of
- Zero-sample anchor error guarantee: every rendered syllable anchor lands exactly on the guide anchor, not within a tolerance, but at the exact integer sample index. The pipeline fails rather than silently producing wrong output.
- Full transparency: the output is an editable Audacity session, not a black box. You can see every cut, stretch, and crossfade, and override any decision the pipeline made.
- Two rendering modes: warp mode produces a single contiguous time-stretched vocal; clip mode produces individual clips for Audacity visual editing. Both are always computed from the same anchor map.
- 168 tests passing: covering syllabification, anchor mapping, edit plan exactness, warp maps, safe-boundary grouping, and render clip lengths.
What we learned
- Forced alignment on rap vocals is surprisingly viable once you handle pronunciation variants and low-energy regions. The key insight is that rap is more rhythmically consistent than conversational speech, which actually helps the aligner.
- Deterministic audio editing with integer sample arithmetic eliminates an entire class of floating-point drift bugs that plague audio pipelines.
- The model-adapter pattern for guide generation paid off immediately. We started with manual guides, added ACE-Step, and could swap backends without touching the rest of the pipeline.
- Safe-boundary clip grouping (splitting at silence, breaths, and zero crossings rather than arbitrary syllable edges) makes a dramatic difference in perceived audio quality versus naive syllable-level cutting.
What's next for AutoRapper
Setting aside the career-pivot use case, there's a serious production workflow here: a tool that collapses hours of manual timing edits into a single deterministic pass while leaving the producer in full control of the final result. From there:
- Vowel-nucleus anchoring: map vowel centers instead of syllable onsets for smoother, more natural-sounding corrections on melodic delivery styles.
- Confidence heatmap labels: visual overlay in Audacity showing which syllables had low alignment confidence so producers know where to double-check.
- Multi-rapper support: separate and independently align multiple voices on the same track.
- Native DAW plugins: move beyond
mod-script-pipeto native Audacity, Reaper, and Ableton plugins with real-time preview. - Formant-aware stretching: adaptive Rubber Band settings that prevent vocal artifacts at extreme stretch ratios by shifting formants intelligently.
Built With
- audacity
- click
- cmudict-+-g2p-en-(pronunciation)-audio-processing:-rubber-band-(time-stretch)
- demucs-(source-separation)
- flask
- librosa-(beat-detection)
- montreal-forced-aligner-(forced-alignment)
- nltk
- numpy
- python
- pytorch
- pywebview
- scipy
- soundfile
- torchaudio-ai/ml-models:-ace-step-1.5-(music-generation)
- uv
- wavesurfer.js-(waveform-display)-tools-&-platforms:-audacity-(mod-script-pipe)


Log in or sign up for Devpost to join the conversation.