💭 Inspiration
Our inspiration for Sprintly came from both personal experience and the hackathon’s theme. As a team, we’ve always admired how product managers balance strategy, coordination, and execution — yet we’ve seen firsthand how demanding and repetitive their workflows can be.
One of our teammates was inspired by his dad, who works as a product manager. Watching him spend countless hours collecting research, writing Jira tickets, syncing with DevOps, and managing constant meetings made us realize how much time PMs lose on coordination instead of creativity.
When we saw that this hackathon track focused on product manager workflows, it felt like the perfect opportunity to build something meaningful. We wanted to create a system that would make his job — and the jobs of PMs everywhere — simpler, faster, and more focused on impact.
Around the same time, we began exploring NVIDIA’s Nemotron models and were impressed by their reasoning and planning abilities. That inspired us to design a connected system that thinks and works like a product manager — streamlining everything from brainstorming to release planning, so PMs can focus on vision instead of busywork.
🚀 What It Does
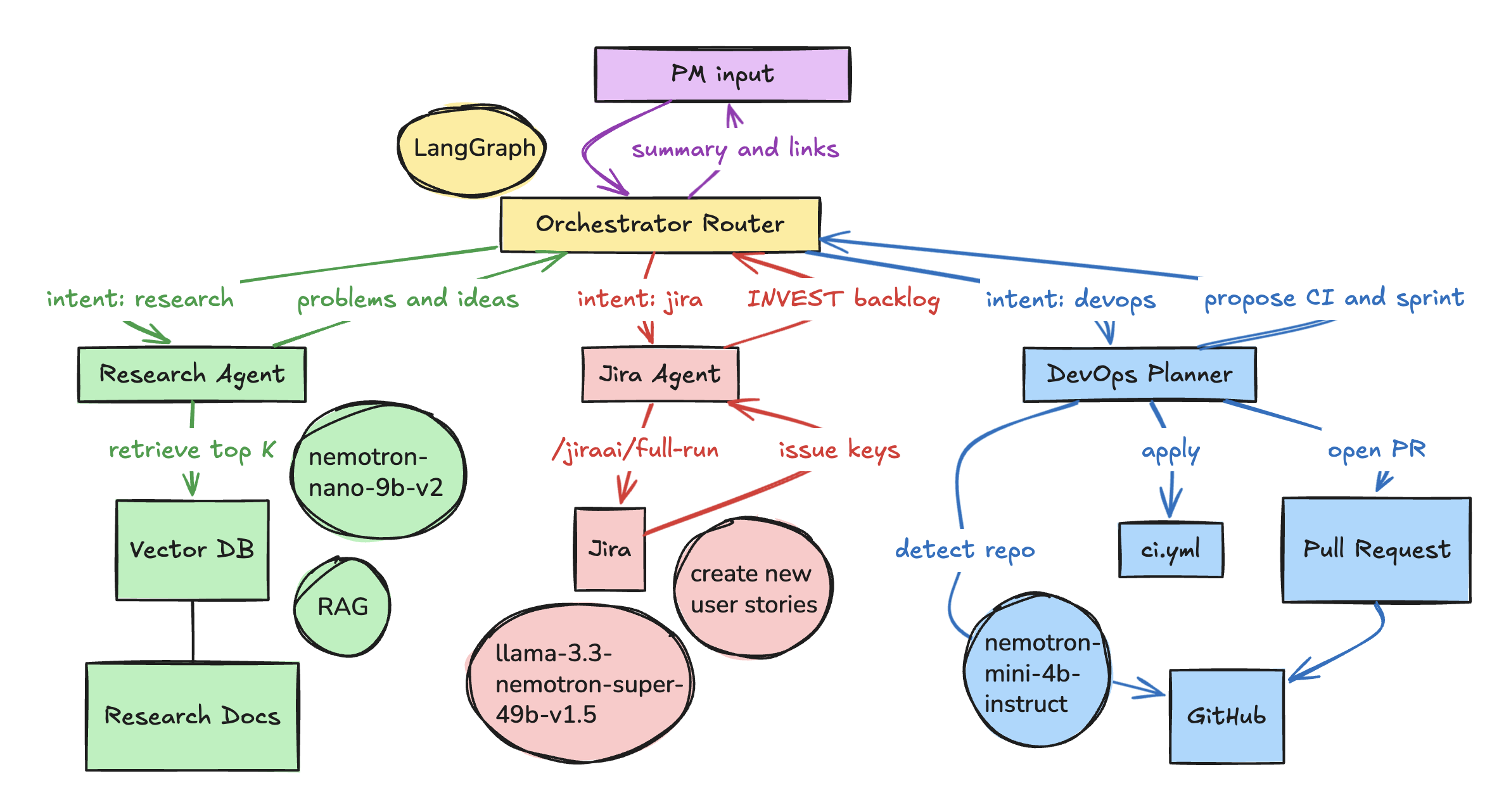
🌟 Main Idea Sprintly is a connected workflow assistant that automates a product manager’s day-to-day operations — from idea discovery to release planning. It combines three specialized components, all powered by NVIDIA’s Nemotron models, and coordinates them through LangGraph, which acts as the system’s decision-maker.
🧠 1. ResearchAI — The Insight Generator (Nemotron Nano 9B v2) Role: Finds meaning in messy information. What it does: -Analyzes customer feedback, survey data, and research reports. -Summarizes key trends and identifies areas of opportunity. -Passes structured insights to the next stage for planning. How it helps PMs: -Instead of spending hours combing through reports, PMs instantly get actionable insights and research summaries to guide better decisions.
📋 2. JiraAI — The Task Architect (Llama 3.3 Nemotron Super 49B v1.5) Role: Turns insights into organized plans. What it does: -Converts research outcomes into well-structured project deliverables. -Automatically creates epics, user stories, and acceptance criteria in Jira. -Maintains logical linking between tasks and priorities. How it helps PMs: -Removes the manual effort of writing and formatting Jira tasks — giving PMs more time to focus on direction and alignment.
⚙️ 3. DevOpsPlannerAI — The Execution Partner (Nemotron Mini 4B Instruct) Role: Bridges planning and engineering. What it does: -Reviews repository structure and team needs. -Suggests CI/CD workflows and sprint plans. -Can open pull requests and document plans automatically. How it helps PMs: -Takes ideas from the whiteboard to the deployment stage — allowing PMs to connect strategy with execution faster than ever.
🌐 LangGraph — The Orchestrator -LangGraph sits at the center of Sprintly , making intelligent routing decisions based on the user’s request: 💬 For research needs → It calls ResearchAI. 🧾 For task organization → It triggers JiraAI. 🔧 For technical rollout → It activates DevOpsPlannerAI. -It can also coordinate multiple at once: -ResearchAI identifies insights → JiraAI structures them into plans → DevOpsPlannerAI prepares the release pipeline. -This creates a single, continuous workflow — turning raw ideas into launch-ready projects in minutes.
🧩 Tech Stack Overview
💻 Languages -Python 3.11+ → Orchestrator, Research (RAG), DevOps Planner -TypeScript (Node 18+) → Jira Service
🔗 APIs & Integrations -NVIDIA Nemotron → Language model & reasoning engine -Jira Cloud API → Epic & story creation -GitHub REST API → CI/CD automation & PR management
🧰 Frameworks & Libraries -LangGraph → Multi-agent orchestration -Requests → HTTP requests (Python) -dotenv → Environment variable management -scikit-learn → TF-IDF + cosine retrieval -NumPy → Vector computations -Express.js → Jira API server
⚙️ DevOps & Testing -GitHub Actions → Automated CI/CD pipelines -YAML generation → Workflow creation -pytest / flake8 → Testing and linting
🛠️ How We Built It
🏗️ How We Built It — Step by Step 1️⃣ Defined the workflow we wanted to automate -Mapped a real PM day: research → backlog writing → coordination with engineers/DevOps. -Identified repetitive parts we could systematize (not replace judgment, just save time). -Broke that into three responsibilities: Research, Planning (Jira), Execution (DevOps).
2️⃣ Picked the right models for each role -Tested multiple NVIDIA Nemotron models for reasoning, structure, and planning tasks. -Assigned lighter/faster models (e.g. Nemotron Nano / Mini) to focused agents, stronger ones to complex planning. -Standardized all calls through one OpenAI-compatible API endpoint for simplicity.
3️⃣ Built the Jira service (JiraAI) as its own backend -Created a Node + TypeScript service that exposes /jiraai/generate and /jiraai/full-run. -Forced the model to return strict JSON (epics, stories, priorities, acceptance criteria). -Integrated with Jira Cloud API to automatically create and link issues inside a real Jira project.
4️⃣ Built the Research component -Set up a lightweight retrieval layer using local files (e.g. ./data / domain docs). -Used TF-IDF + cosine (and embeddings where needed) to pull only relevant context. -Generated short, focused outputs: key findings + product ideas that feed directly into JiraAI.
5️⃣ Built the DevOps Planner -Scanned the repo for signals (tests, package files, existing workflows, tech stack). -Generated a proposed .github/workflows/ci.yml and a SPRINT_PLAN.md based on the project needs. -Used the GitHub REST API to create/update workflow files and open pull requests automatically.
6️⃣ Wired everything together with LangGraph -Implemented a router that looks at the user’s prompt and decides: Research, Jira, DevOps, or a combo. -Shared state between steps so outputs from one component become inputs to the next. -Enabled chained flows like: Research → JiraAI → DevOpsPlannerAI from a single prompt.
7️⃣ Hardened the system -Added validation on all structured outputs (especially JSON for Jira). -Handled failures from Jira/GitHub gracefully with clear error messages and retries. -Tested end-to-end flows using real prompts to confirm: one request → insights, backlog, and execution plan ready.
Challenges we ran into 🤖
Multi-Agent Coordination -Hard to synchronize ResearchAI, JiraAI, and DevOpsPlannerAI without overlap. -Agents often duplicated tasks or lost shared context. -Solved with a LangGraph orchestration layer that routes prompts and maintains shared memory.
🧠 Choosing the Right Nemotron Model -Tested multiple NVIDIA Nemotron models for each agent. -Some models excelled at reasoning, others at structured task generation. -Final setup: Reasoning for ResearchAI, Structure for JiraAI, and Planning for DevOpsPlannerAI.
🧱 Strict JSON Enforcement -Nemotron mixed reasoning text with JSON, breaking automation -JiraAI couldn’t parse malformed data correctly. -Added a “JSON jail” system prompt and response validator to enforce clean output.
⚙️ Parallel Task Management -Multiple agents triggered simultaneously caused timing conflicts. -Workflows overlapped or repeated actions. -Implemented asynchronous orchestration so all agents collaborate in real time.
🏆 Accomplishments We’re Proud Of
-🚀 Built a connected system that mimics how real teams work, with research, planning, and execution all talking to each other. -🧩 Automated a full product management cycle — turning an idea into organized plans and technical workflows in one go. -⚙️ Optimized model pairing by selecting the best Nemotron for each stage, achieving a balance between reasoning depth and output precision.
📚 What We Learned
-💡 We learned that technology works best when it amplifies people, not replaces them — Sprintly showed us how automation can support better thinking. -⚙️ Building multi-step workflows taught us the value of communication — both in code and in teams. -🌍 We gained experience designing systems that can scale beyond a prototype, with real applications in modern workplaces.
🔮 What’s Next for Sprintly
-☁️ Scale on AWS: Deploy Sprintly using ECS, Lambda, and API Gateway for reliable scalability and elastic performance. -📊 Smarter data management: Use S3, DynamoDB, and RDS for storing project insights, making Sprintly a central productivity hub. -🔐 Enhanced security: Add encryption, access control, secret management, and activity logs to keep product and user data safe.
Built With
- apis
- axios
- css
- javascript
- nemotron
- node.js
- python
- rag
- react-native
- tailwind
- typescript
- vite




Log in or sign up for Devpost to join the conversation.