-
-
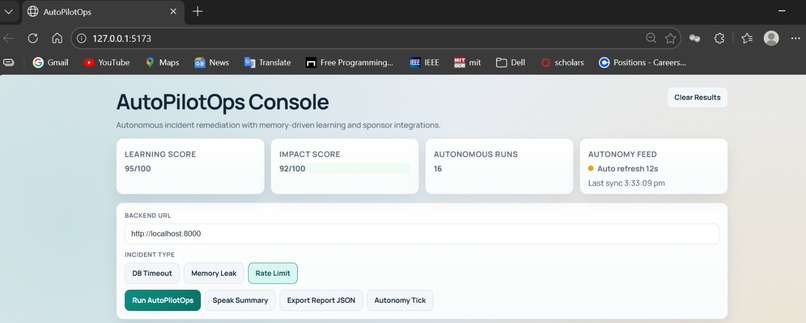
Demo
-
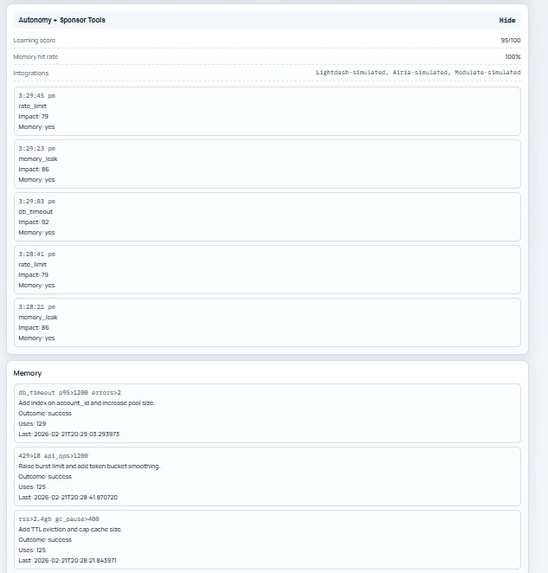
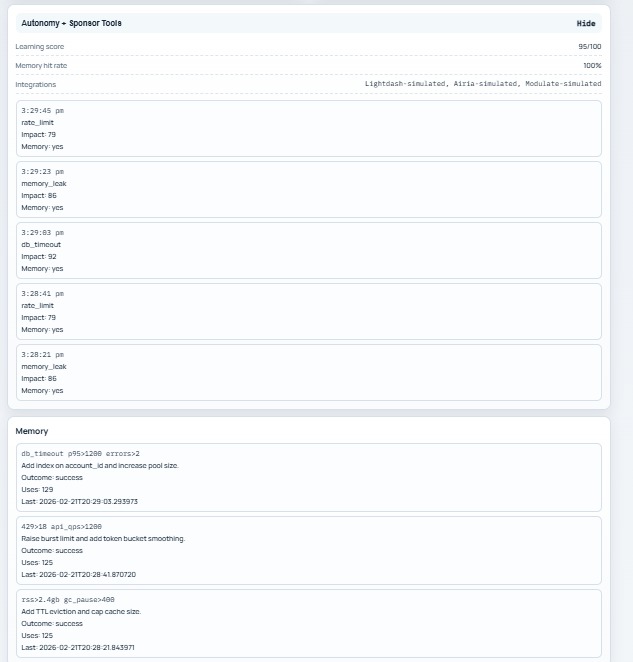
Memory
-
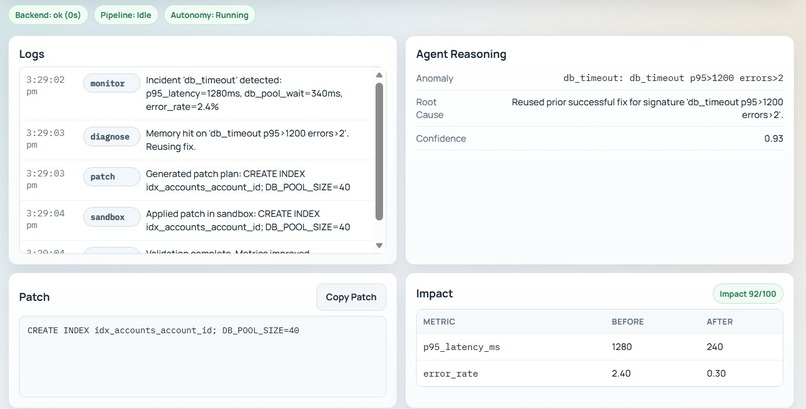
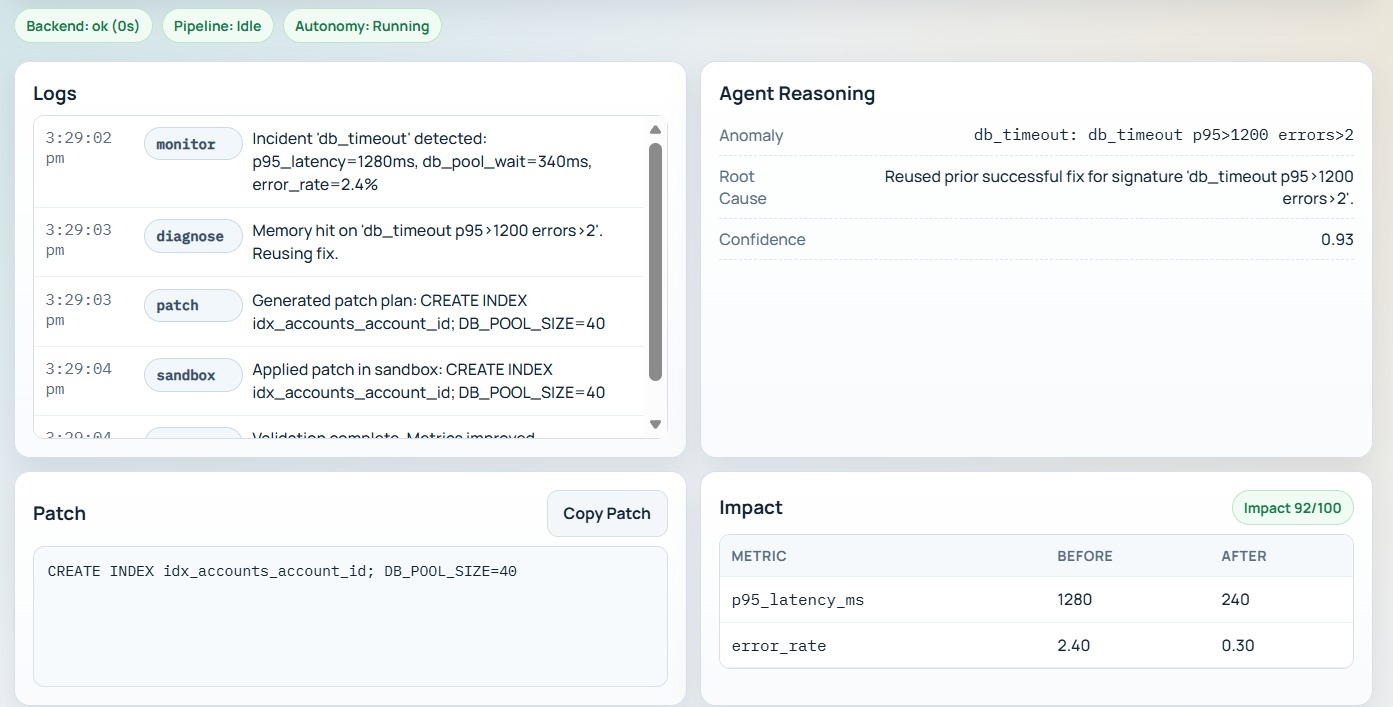
Logs
🚀 AutoPilotOps: Autonomous Incident Remediation
🧠 About the Project
AutoPilotOps was born from a simple question:
What if incident response could be autonomous?
Modern production systems generate massive volumes of events and logs, but engineers still manually diagnose and fix failures. We set out to build a system that detects failures, reasons about causes, applies fixes safely, validates outcomes, and learns from experience — all autonomously.
This project taught us how to design multi-agent systems that behave like self-healing site reliability engineers (SREs). Along the way we tackled production-grade API design, integrated observability tooling, and created a reusable remediation loop.
💡 Inspiration
Infrastructure systems today are monitored closely by observability platforms (metrics, logs, traces), yet bridging the gap between detection and remediation remains manual. We wanted to build the next layer of infrastructure — one where the system continually improves itself by learning from past incidents.
Our inspiration came from:
- Real SRE workflows
- Modern observability and AI tooling
- The idea of self-improving agents
🔍 What It Does
AutoPilotOps simulates real types of production incidents:
- Database timeout
- Memory leak
- Rate limit saturation
Each incident is processed through a pipeline of agents:
- Monitor Agent — Detects anomalous metrics and errors
- Diagnose Agent — Infers root cause using memory + reasoning
- Patch Agent — Proposes remediation strategy
- Sandbox Agent — Tests the patch in isolation
- Evaluate Agent — Measures before/after impact
- Memory System — Stores successful patterns for future reuse
We model impact using systems metrics. For example, the overall impact score is a function of measured changes:
$$ Impact = f(\Delta latency,\ \Delta error_rate,\ \Delta throughput) $$
🏗 How We Built It
🧩 Backend
- FastAPI for REST endpoints
- Modular multi-agent pipeline
- Memory persistence via both SQLite & JSON
- Middleware for:
- API key auth
- Rate limiting
- Request size limits
- Structured request ID tracing
- Structured logging for observability
🖥 Frontend
- React + Vite for SPA dashboard
- Modular components showing:
- Backend status
- Incident controls
- Agent logs and reasoning
- Patch suggestions
- Impact results
- Export JSON and voice summary support
🔗 Integrations
- Lightdash API for external metric validation
- Uses
Authorization: ApiKey <token>
- Uses
- Simulation support for sponsor tools (e.g., Airia, Modulate)
📦 Deployment
- Dockerized frontend + backend
- Health endpoints (
/health,/ready) - Production ENV configs
💪 Technical Highlights
- Multi-agent structured pipeline
- Self-improving memory loop
- Sandbox validation before persistence
- Clean separation between detection, reasoning, and remediation
- Fault-tolerant LLM wrapper (timeout + fallback)
- CORS and security enforced
🤯 Challenges We Faced
Simulating Real Incidents
We had to design meaningful yet synthetic incidents that resemble real failures.
Memory Reuse
Balancing deterministic logic with store & reuse of past fixes required careful design.
Production Readiness
Adding structured logging, middleware, and readiness checks made this more than a toy demo.
External API Integration
Lightdash uses ApiKey auth (not Bearer), which required correct header handling.
📘 What We Learned
- Agents should have clear responsibilities
- Metrics + reasoning loops improve over time
- Production grade equals predictable failures
- Integrations must be secure and configurable
✨ Future Vision
AutoPilotOps is a step toward truly autonomous infrastructure:
- Run tests in CI/CD automatically
- Automated rollback & canary deployments
- Use reinforcement learning to optimize fixes
- Support distributed microservice remediation
We believe infrastructure should not just scale — it should heal itself.

Log in or sign up for Devpost to join the conversation.