-
Dashboard
-
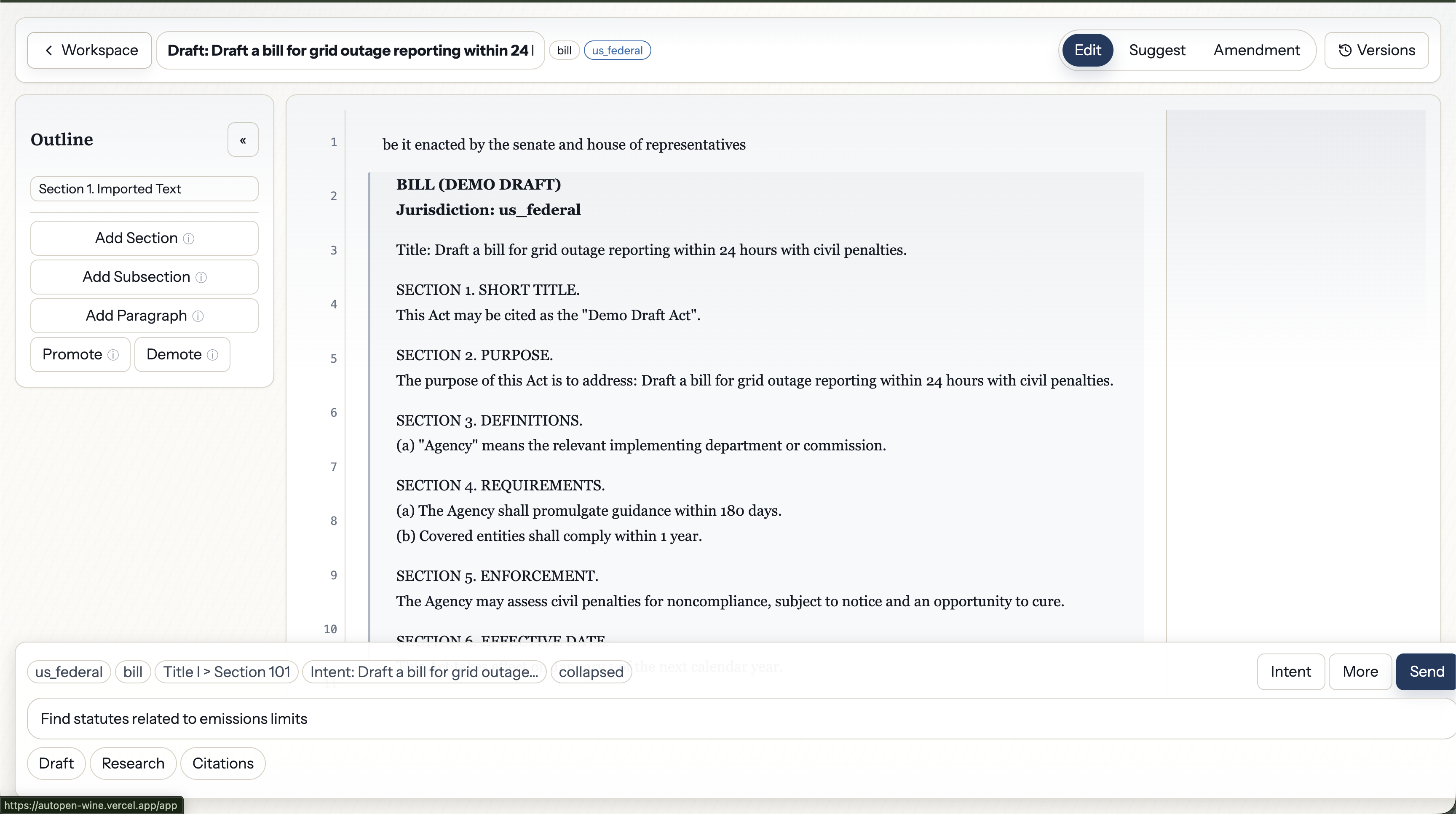
AI-Powered Drafting Page
-
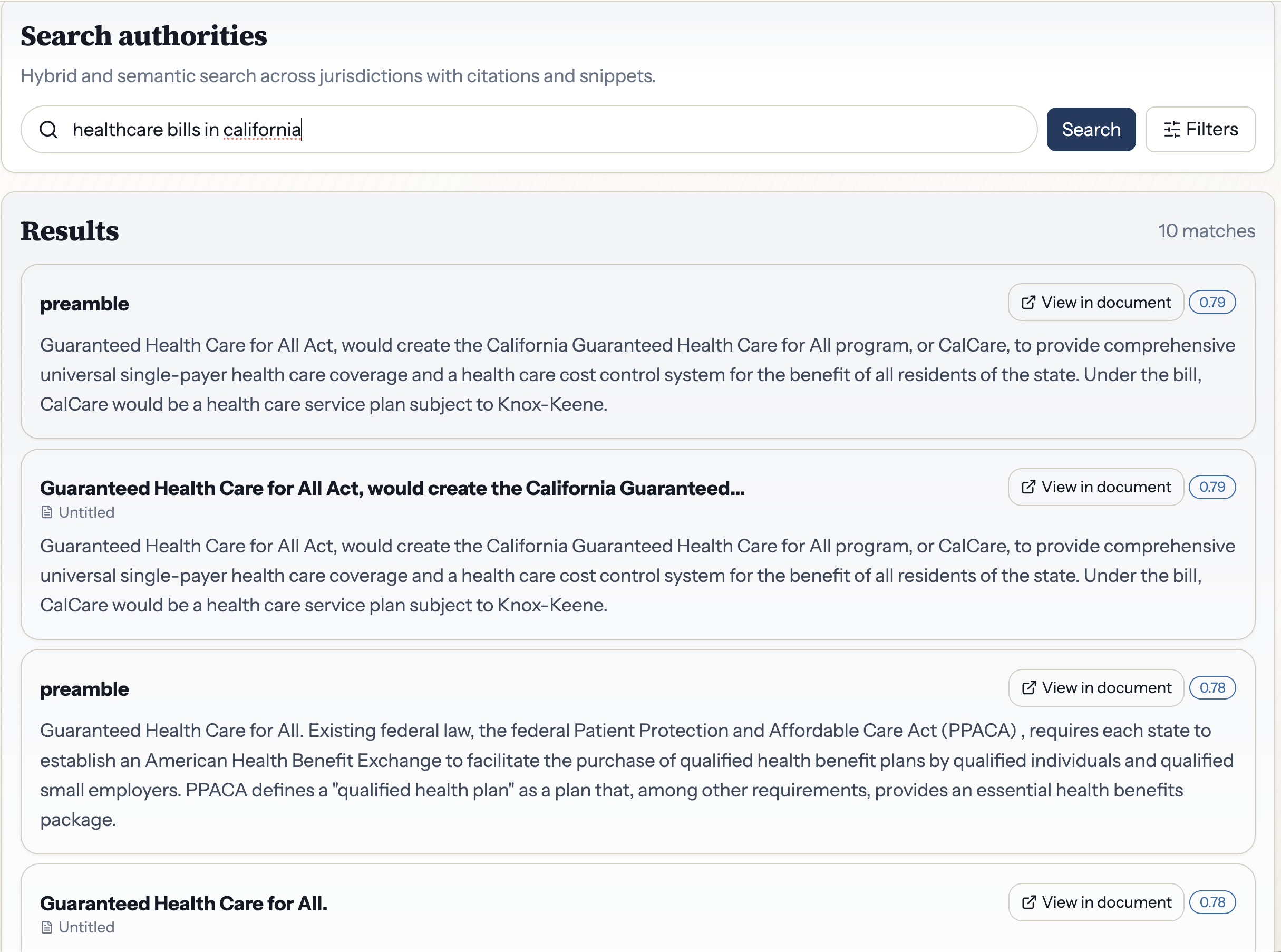
Legal Semantic Search
Inspiration
Legislative drafting is broken. In 2015, a four-word drafting error in the Affordable Care Act - "established by the State" - reached the Supreme Court and nearly stripped health insurance from 6.4 million Americans. That's what happens when legislation is written with Word documents, manual cross-referencing, and legacy XML editors that haven't changed in decades. The scale makes it worse: over 250,000 bills are introduced across U.S. state legislatures every session, and the legislative staff responsible for drafting them has been shrinking since 1996. More bills, fewer people, worse tools.
What if legislative drafting had the same caliber of tooling as software engineering?
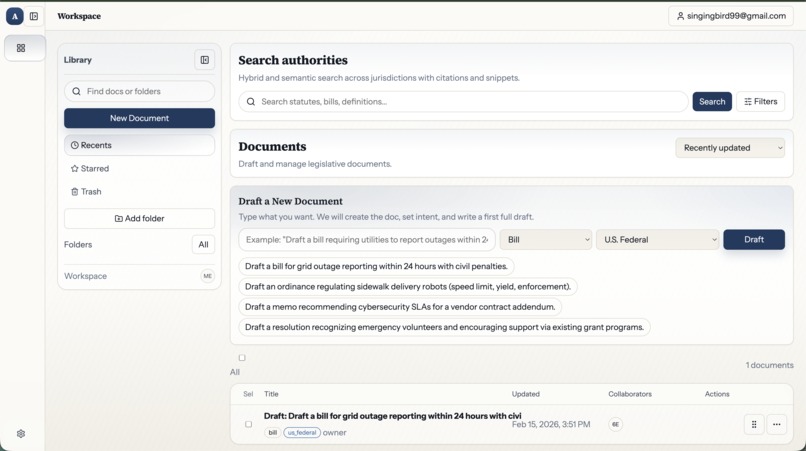
What it does
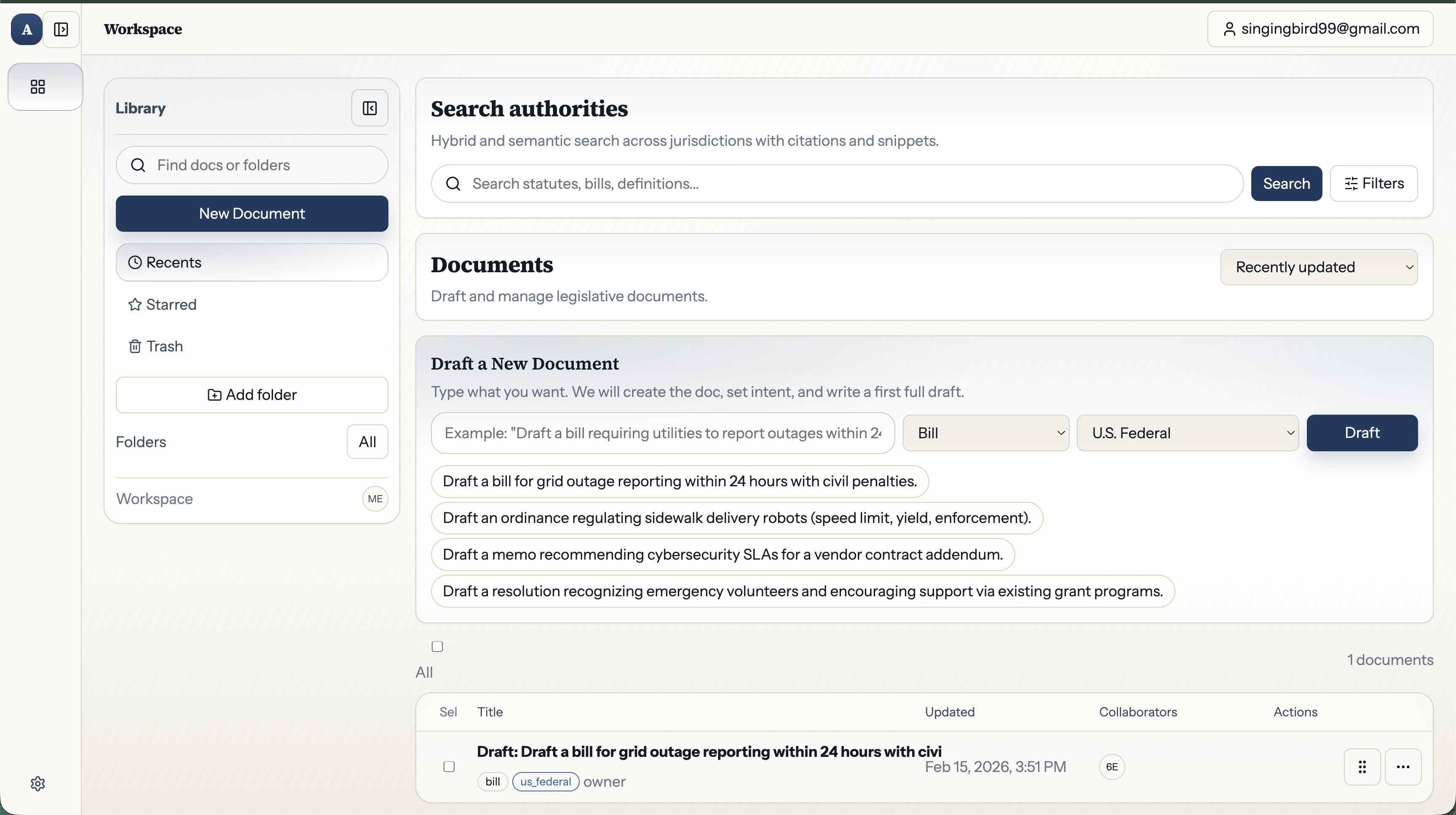
AutoPen is an AI-native workspace for drafting legislation. It replaces the fragmented workflow of Word + Westlaw + LegisPro + manual research with a single surface where every feature understands the domain:
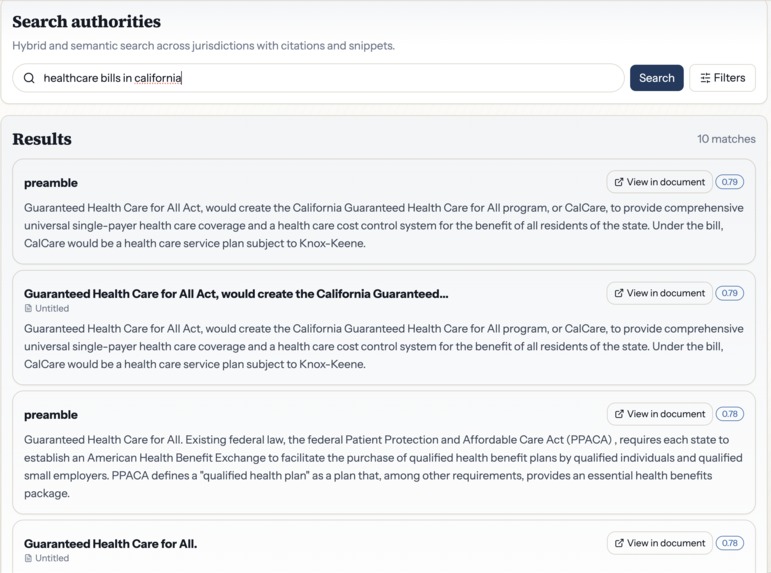
- Hybrid authority search: BM25 full-text search combined with semantic vector search over millions of legislative documents (federal bills, the U.S. Code, the CFR, and all 50 state legislatures), reranked by Jina AI for precision.
- Citation-grounded AI: Every AI suggestion cites its source — a real statute, regulation, or bill. No hallucinated citations, ever.
- Jurisdiction-aware intelligence: Select your jurisdiction (federal, California, Texas, etc.) and the entire system adapts - enacting clauses, numbering conventions, amendment formats, style rules, and AI completions all shift accordingly.
- Web-grounded research: Perplexity Sonar integration brings live web research into the drafting surface.
- Tab completions: Inline ghost-text suggestions powered by fine-tuned models with per-jurisdiction LoRA adapters, appearing only when confidence is high.
How we built it
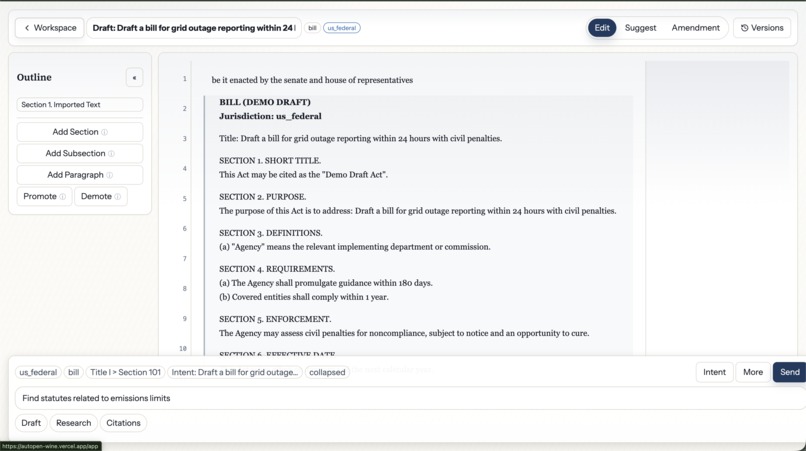
Frontend: Next.js 15 on Vercel with a custom Tiptap (ProseMirror) editor extended with legislative structure nodes. Each structural element (Section, Subsection, Paragraph, etc.) is a first-class editor node with jurisdiction-specific rendering rules.
Search: ElasticSearch Cloud with a dual-retrieval pipeline — BM25 full-text search fused with Jina jina-embeddings-v3 semantic vectors via Reciprocal Rank Fusion (RRF), then reranked with jina-reranker-v2-base-multilingual. A custom legal synonym analyzer maps legislative language (shall/must, pursuant to/under, herein/in this).
Data pipeline: Python workers on Railway ingest from five sources - Congress.gov API (federal bills), GPO bulk data (U.S. Code in USLM XML), the eCFR API (federal regulations), OpenStates v3 (CA, FL, NY, TX), and Bright Data for supplemental (hardest!) scraping. Documents are chunked on section boundaries, embedded, and bulk-indexed into Elasticsearch.
ML inference: NVIDIA Nemotron-Cascade-8B served on Modal via vLLM with an OpenAI-compatible API. We train LoRA adapters per jurisdiction on Modal H100s, composing them into bundles (structural + jurisdiction) that hot-swap at inference time.
Research: Perplexity Sonar API for web-grounded generation — every research response returns inline citations that insert directly into the document.
Database: Supabase Postgres with row-level security on every table. Yjs/Hocuspocus on Railway for real-time collaboration infrastructure (WebSocket sync with snapshot compaction).
Infra: Vercel (web), Railway (workers + collab server), Modal (GPU inference + LoRA training), Supabase (DB).
Challenges we ran into
Data curation - I wanted to curate data from all 50 states and use that. But that resulted in too much data for 36 hours, and training times were taking too long. Ended up choosing 4 states (CA, FL, NY, TX).
Training - I ran into a lot of errors during training, debugging them took a very long time. We use OpenAI's GPT-5-mini as a fallback in the case the adapters are still flawed.
Model selection under pressure. Choosing the right base model for tab completions meant balancing inference latency, license terms, and fine-tuning quality. We pivoted to NVIDIA Nemotron-Cascade-8B mid-build after our initial choice had compatibility issues with our LoRA adapter pipeline.
Making the product robust. Live demos with five external API dependencies (Elasticsearch, Modal, Perplexity, RunPod, Supabase) are fragile by nature. It's still buggy...
Hybrid search tuning. Getting BM25 + semantic search fusion right for legal text required building a custom legal synonym analyzer and carefully tuning the RRF weights. Legal language is precise in ways that break naive semantic similarity.
Accomplishments that we're proud of
- Every AI-generated reference traces back to a real document in our Elasticsearch corpus or a live web source.
- Structure enforcement at the editor level. Not a linter, not a post-hoc check — the editor itself makes it impossible to produce an invalid bill hierarchy. Structure is a constraint, not a suggestion.
- Thousands of documents indexed and searchable. Federal bills, the full U.S. Code, the CFR, and legislation from several US states - all in just 36 hours
- Hot-swappable jurisdiction intelligence. Switch from federal to California drafting and everything changes: numbering, enacting clauses, amendment format, style rules, and the AI's completions. Same editor, different legal universe.
What we learned
Legal text is a fundamentally different domain from general prose. Every design decision we imported from conventional editors broke in some way. Building in a domain-specific area in a very limited time-frame was difficult, but rewarding and I believe that it is still a really impactful area. If legislators can draft bills/resolutions faster, then government can become more efficient and faster at helping their consituents.
What's next for AutoPen AI
- Real-time collaboration launch: The Hocuspocus/Yjs infrastructure is built and running - we need to expose it in the product UI so multiple staffers can co-draft simultaneously.
- Impact analysis: "What existing law does this bill affect?" We have RunPod serverless endpoints for cross-reference validation and conflict detection — next step is surfacing this as an interactive analysis panel.
- Per-user personalization: The LoRA adapter pipeline supports user-level fine-tuning (stacked on jurisdiction adapters). Once users draft enough content, the tab model learns their style - modal verb preferences, sentence length, terminology choices.
- Amendatory language generation: Edit existing law inline and have the AI generate proper amendatory instructions in the jurisdiction's format.
- Expand jurisdiction coverage: Deep support for all 50 states with jurisdiction-specific LoRA adapters, not just the five we launched with.
- Fiscal note drafting: AI-assisted fiscal impact estimation to help under-resourced legislatures produce the budget analyses that bills require.
Built With
- congress.gov-api
- elasticsearch
- fastapi
- jina
- modal
- nemotron-cascade-8b
- next.js
- openstates-v3
- perplexity-sonar
- python
- railway
- sql
- supabase
- typescript
- vercel
- vllm




Log in or sign up for Devpost to join the conversation.