-
-
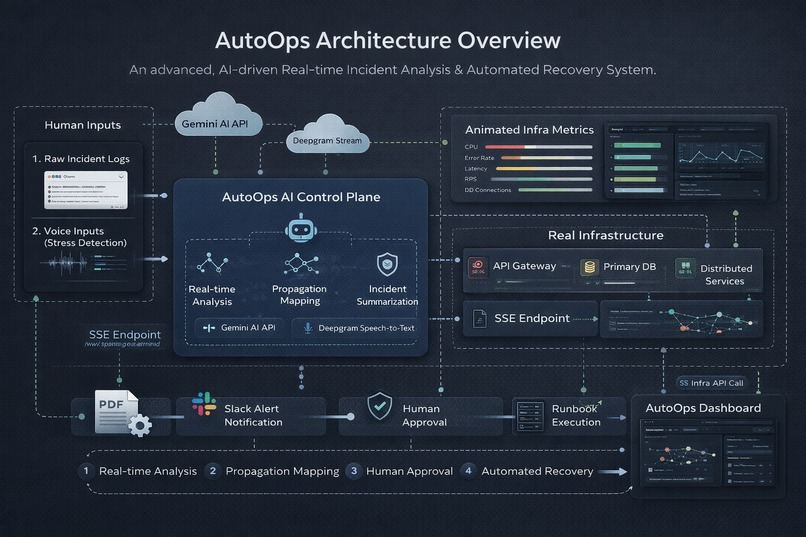
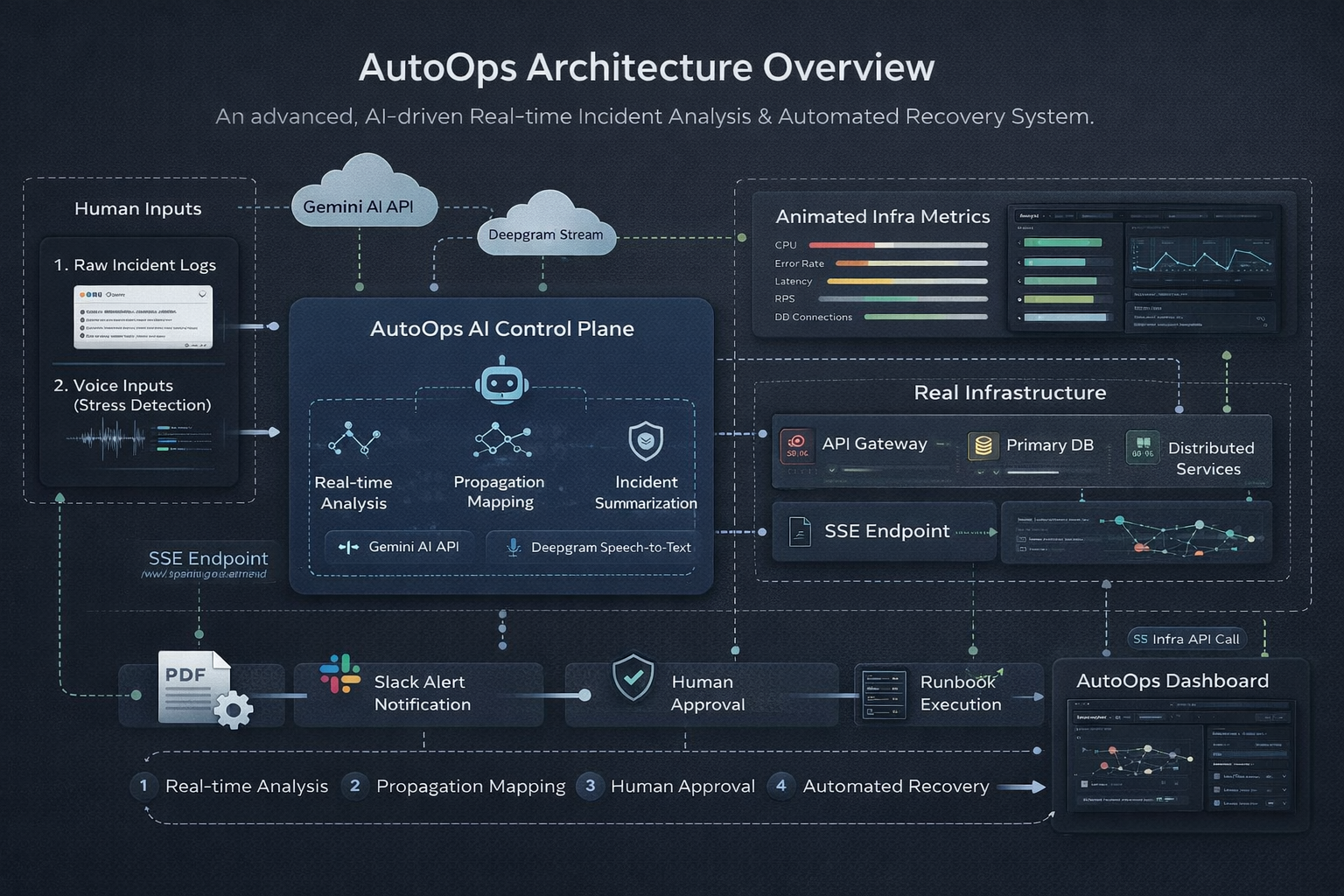
AutoOps Architecture — Real-Time AI Control Plane
-
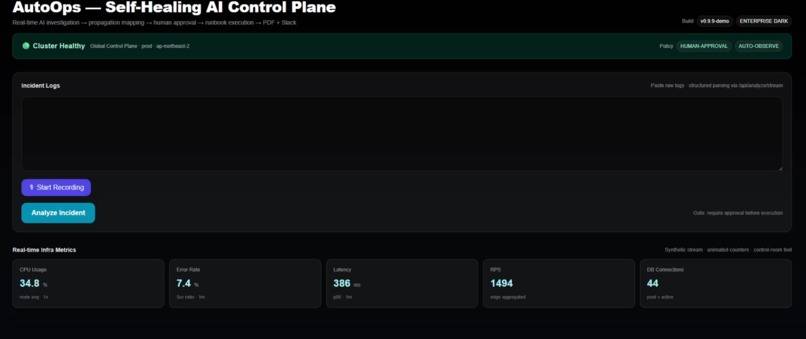
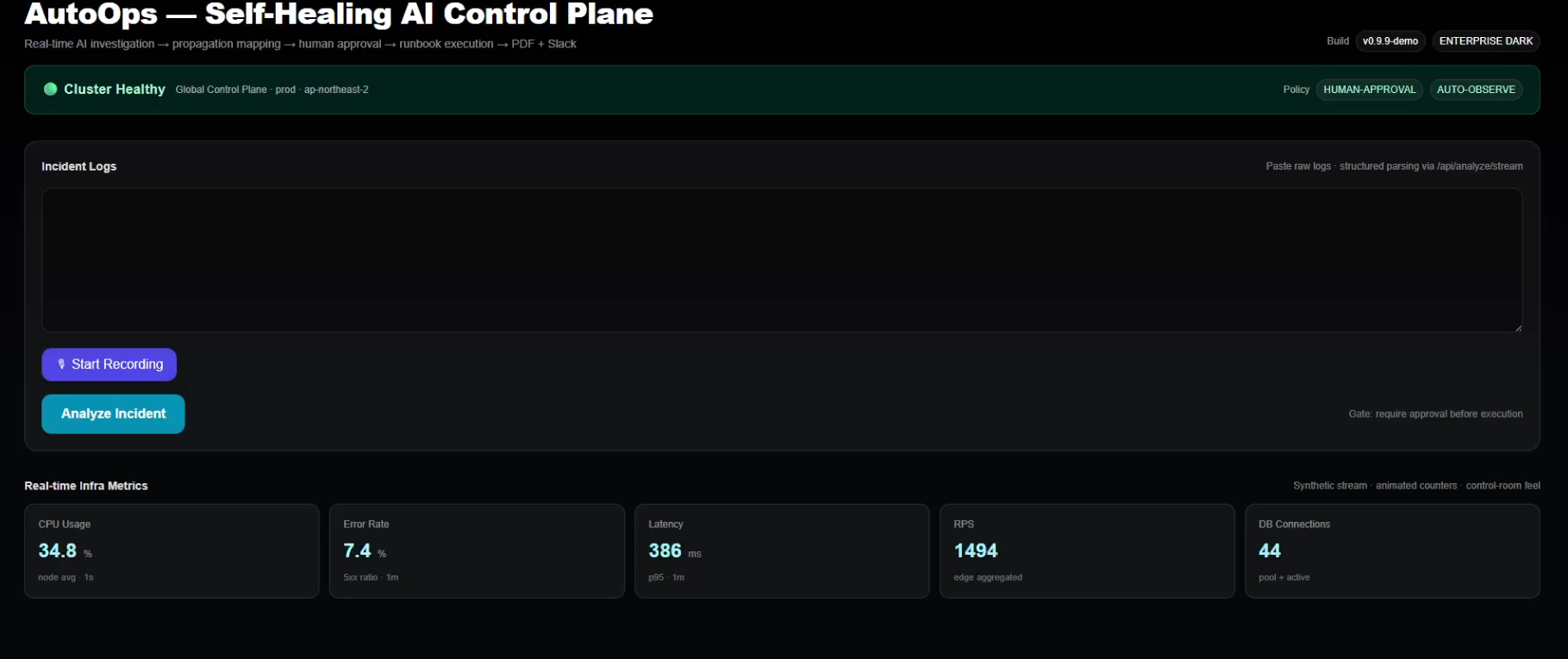
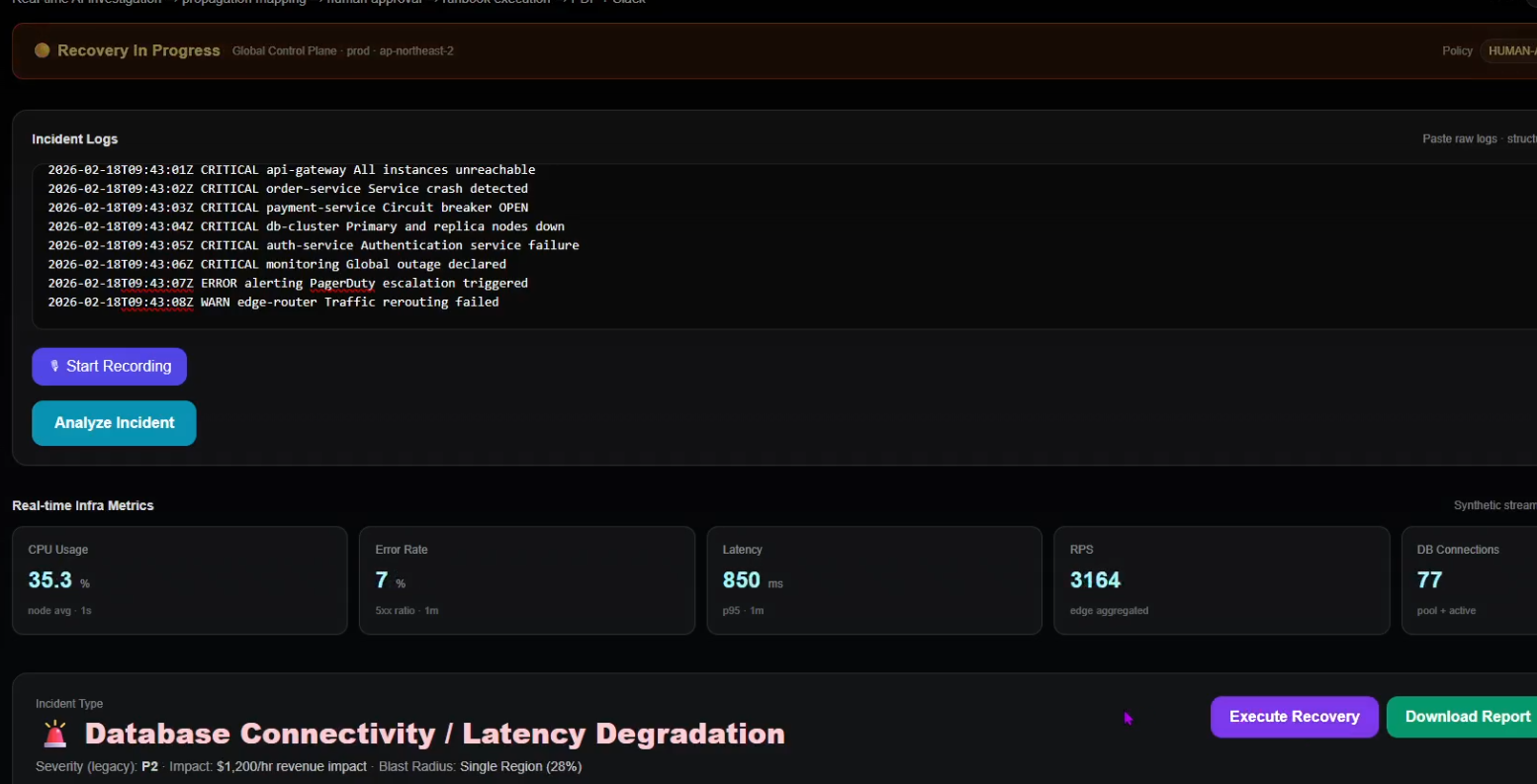
AutoOps continuously monitors distributed services and visualizes real-time infrastructure metrics in a centralized control plane.
-
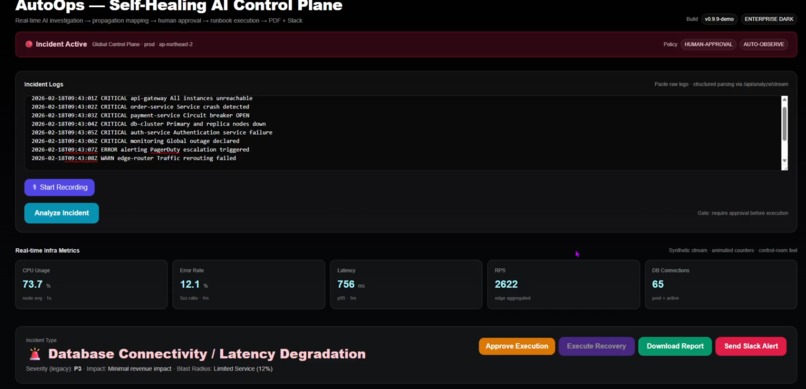
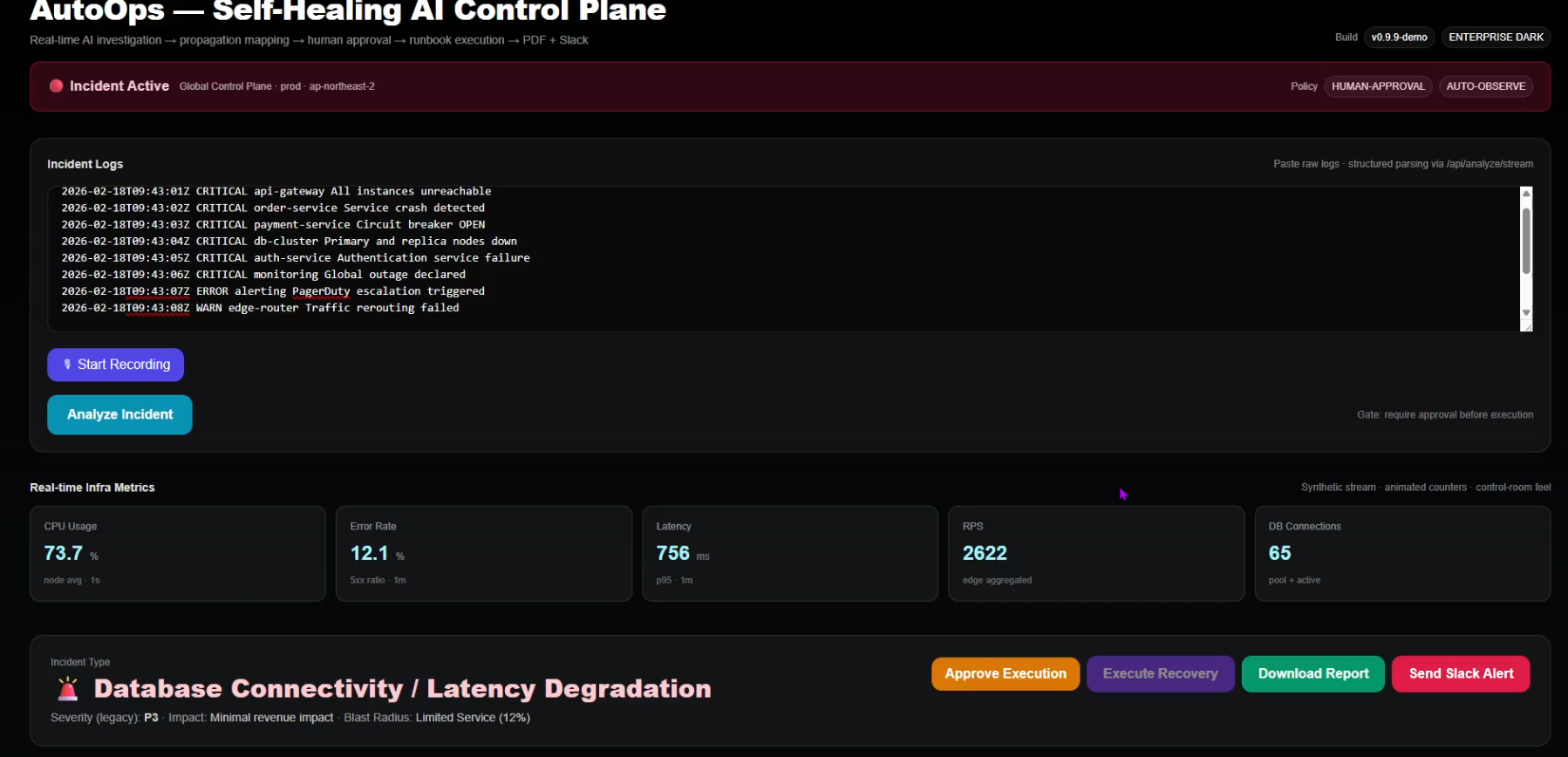
AutoOps ingests raw production logs and immediately detects cascading failures across API Gateway, Order Service, and Database clusters.
-
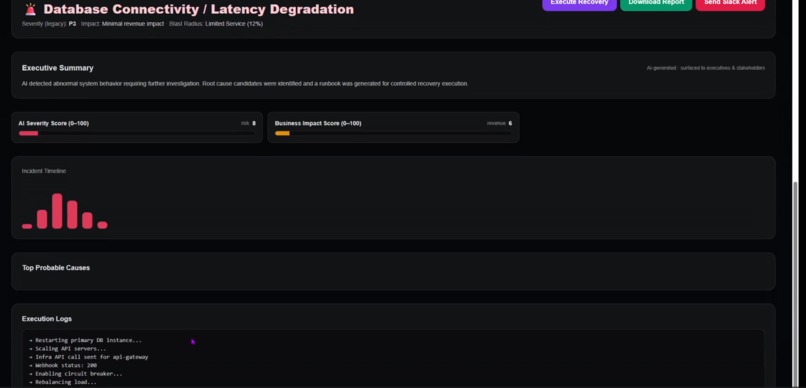
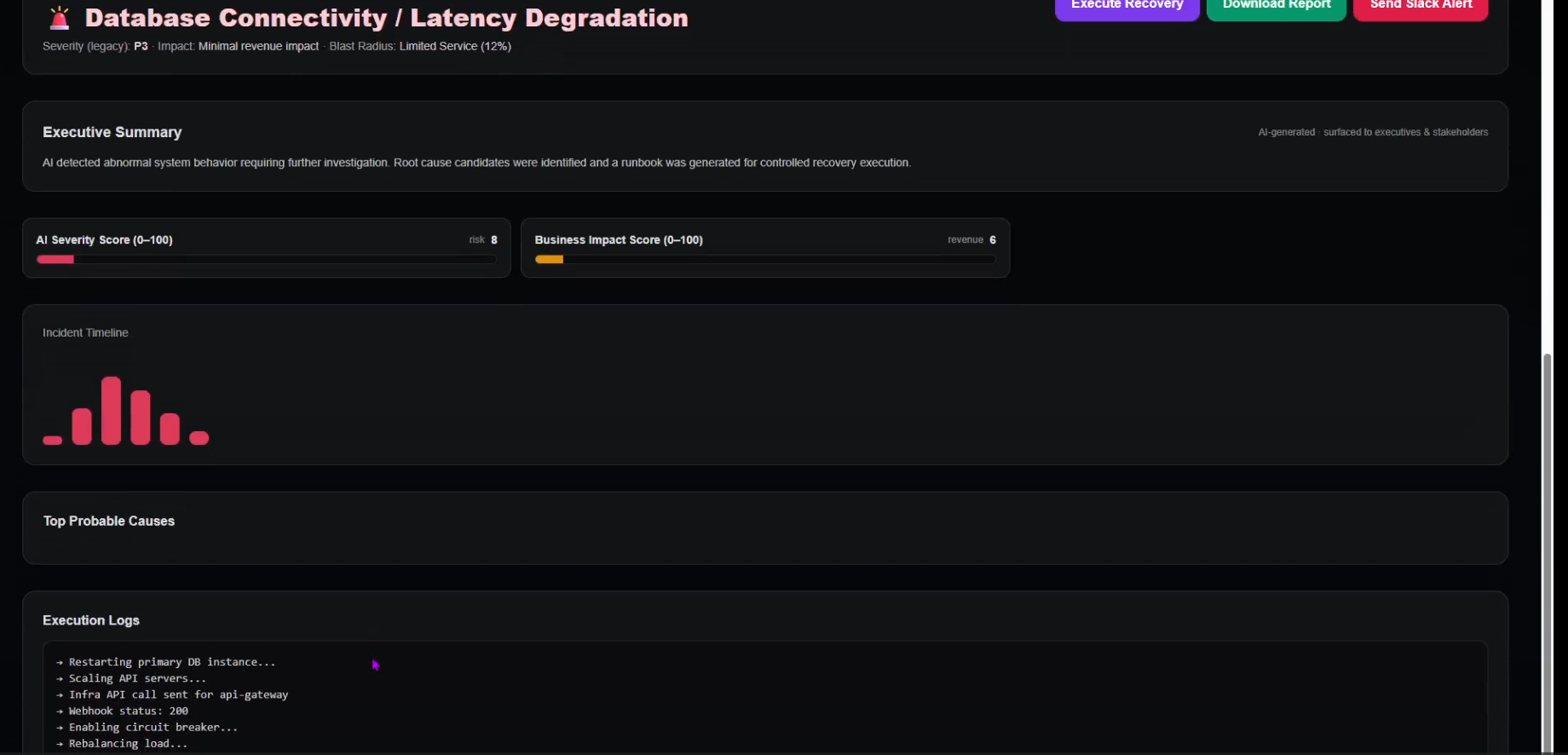
AutoOps doesn’t just detect incidents — it explains them, scores risk, models impact, and prepares accountable recovery.
-

From detection to approval to automated recovery — every action is controlled, auditable, and enterprise-ready.
-
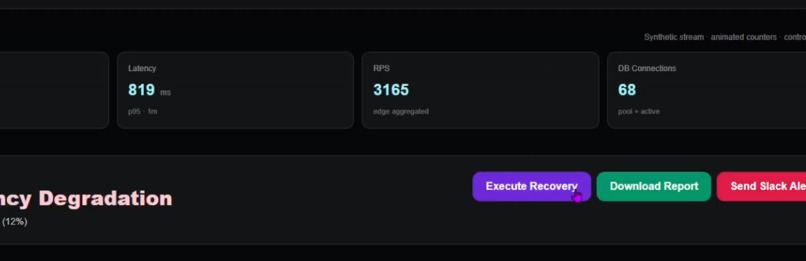
From insight to action — AutoOps converts AI analysis into automated, controlled infrastructure recovery.
-
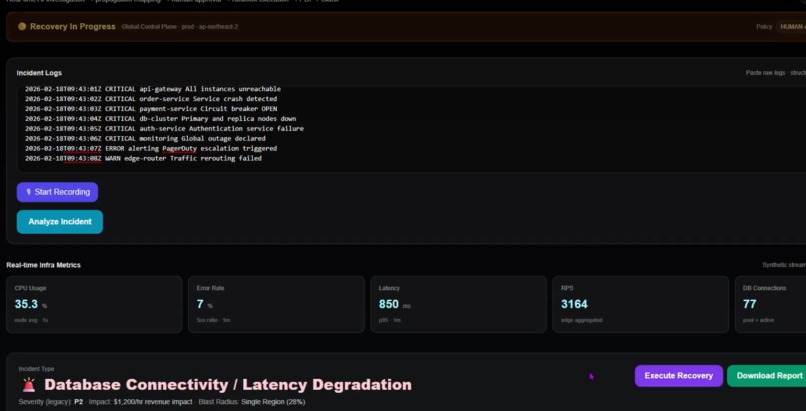
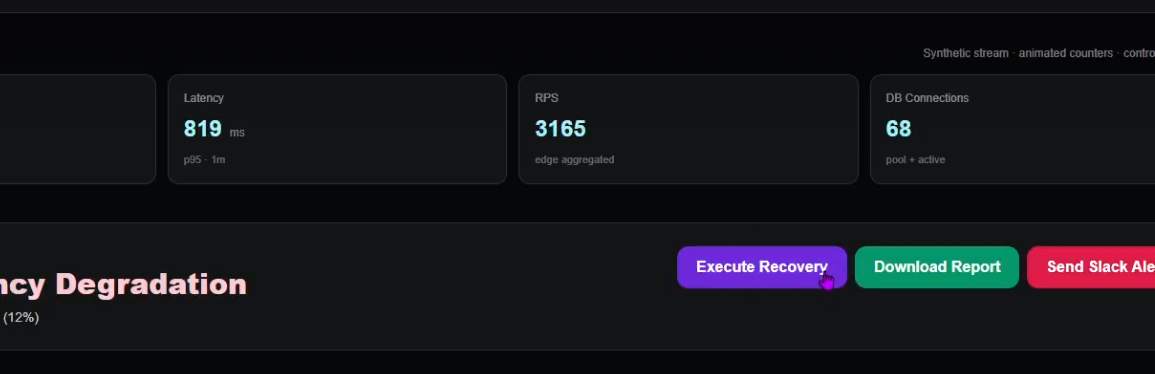
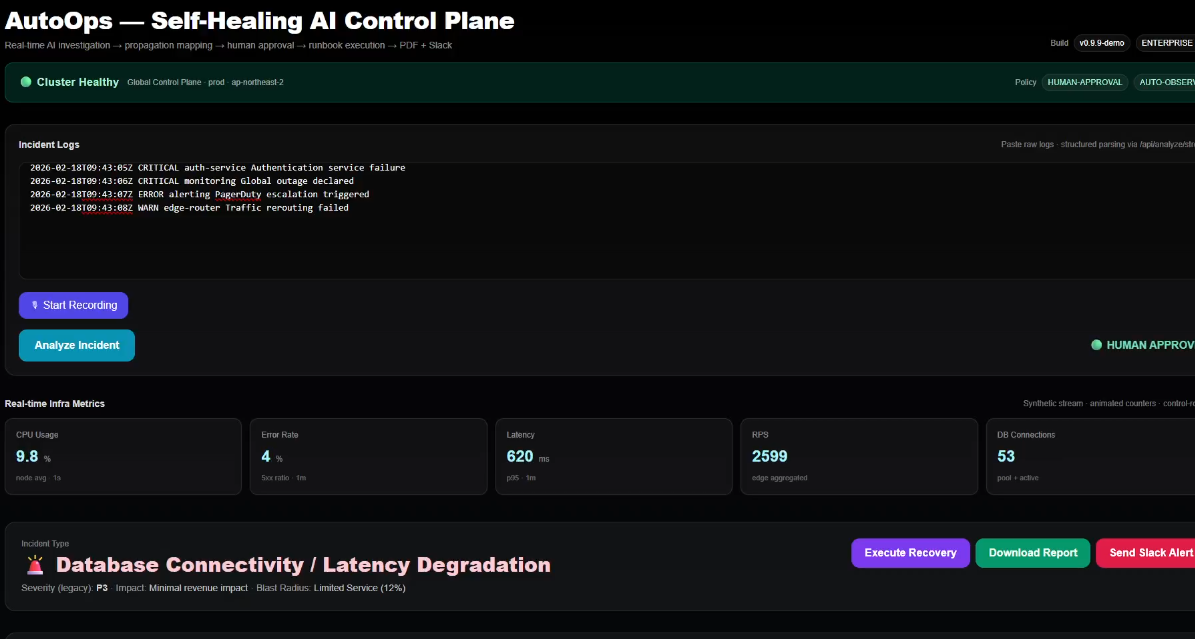
System transitions from active incident to recovery mode, stabilizing services before returning to healthy state
-
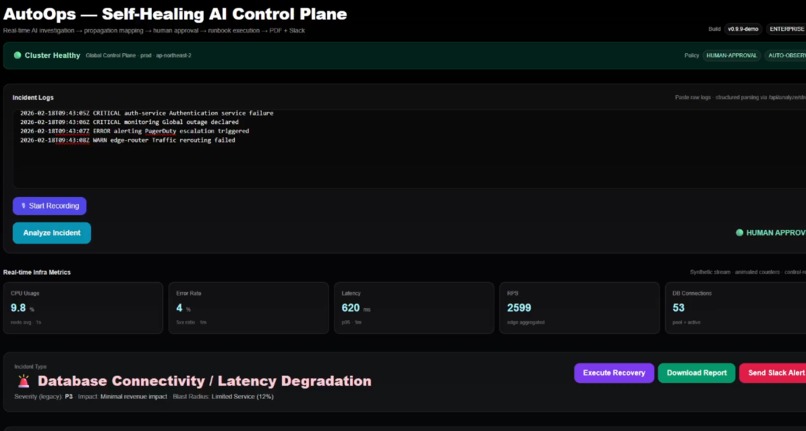
AutoOps completes controlled recovery, restoring full service health and returning the production cluster to green status.

Inspiration
Modern distributed systems no longer fail in isolated ways. They fail across services, propagate silently, and escalate faster than human operators can respond.
Most AI incident tools today stop at analysis. They summarize logs. They suggest causes. But they do not command recovery.
AutoOps was built around a different idea:
What if AI didn’t just analyze incidents — what if it acted as a real-time Incident Commander inside a control plane?
I wanted to design something that feels less like a chatbot and more like an AI operating inside production infrastructure — structured, deterministic, controlled, and human-aware.
AutoOps is my attempt to simulate that future.
What it does
AutoOps is not a chatbot. It enforces structured reasoning, deterministic safeguards, and human approval before executing recovery.
AutoOps is a Self-Healing AI Control Plane for distributed systems.
It transforms raw production logs into structured, actionable incident response — end to end.
It:
Detects and classifies incidents from unstructured logs
Streams live AI investigation reasoning (SSE-based)
Generates executive summaries for stakeholders
Scores severity and business impact (0–100 scale)
Maps multi-service failure propagation visually
Identifies top probable root causes with reasoning
Generates structured AI runbooks
Requires explicit human approval before execution
Executes controlled infrastructure recovery (webhook-based simulation)
Transitions system state from Incident → Recovering → Healthy
Produces enterprise-grade PDF incident reports
Sends Slack alerts
Enriches analysis with real-time external intelligence (You.com)
Integrates voice input (Deepgram) to dynamically adjust severity if stress is detected
This is not just log analysis.
It behaves like an AI-powered Incident Command System.
How we built it
AutoOps is architected as a full-stack AI control plane simulation.
🔹 Frontend — Control Room Interface (Next.js + React)
Real-time Server-Sent Events streaming
Strict separation of narration and FINAL_JSON blocks
Animated severity, impact, and recovery metrics
Multi-service health view
Dynamic failure propagation graph layout
Human approval gating before execution
Simulated infrastructure metric streams
Execution log tracing
The UI is intentionally designed to feel like a production operations console, not a demo page.
🔹 AI Core — Gemini 1.5 Flash
The AI layer operates under strict JSON schema constraints.
We implemented:
Structured output enforcement
Safe JSON extraction and parsing
Deterministic fallback logic
Hybrid scoring model
Hybrid scoring combines:
AI-generated severity
Service health analysis
Blast radius computation
Propagation graph topology impact
Final severity is never purely LLM-generated. It is recalculated deterministically to prevent under-reporting.
🔹 External Intelligence Layer
AutoOps enriches incidents with contextual search intelligence via You.com.
Logs are partially summarized and queried externally, then injected back into the AI prompt as real-time context.
This simulates how real-world incident commanders consult external knowledge during active outages.
🔹 Execution Layer
Recovery execution is intentionally gated.
Flow:
AI proposes recovery steps
Human approves
Infrastructure execution endpoint is triggered
Webhook simulates scaling or failover action
System state transitions gradually toward Healthy
Severity scores and service states dynamically decrease during recovery simulation.
This creates a realistic operational feedback loop.
🔹 Voice Intelligence (Deepgram)
We integrated speech-to-text with metadata analysis:
Speech rate calculation (words per second)
Confidence scoring
Stress detection heuristics
If stress signals exceed thresholds, severity is automatically boosted.
Incident response is not just technical — it is human.
🔹 Enterprise Reporting Engine
Using pdf-lib, AutoOps generates:
Structured executive summaries
Root cause breakdowns
Severity visual indicators
AI confidence bar visualization
External intelligence context
Reports are presentation-ready.
Challenges we ran into
Enforcing strict JSON compliance in streaming LLM responses
Preventing narration from corrupting structured output
Handling partial SSE chunk boundaries safely
Designing hybrid severity scoring that avoids AI conservatism
Maintaining consistency between streaming and fallback endpoints
Dynamically generating graph layouts for arbitrary propagation trees
Simulating realistic recovery transitions without hard-coded hacks
The biggest challenge was realism.
It needed to feel like a real system — not a hackathon prototype.
Accomplishments that we're proud of
Built a fully functioning AI control plane simulation end-to-end
Implemented hybrid AI + deterministic severity modeling
Designed a live recovery state transition engine
Enforced production-safe structured AI outputs
Integrated external intelligence into incident reasoning
Added stress-aware voice severity adjustment
Delivered a cohesive enterprise-grade UX
Most hackathon projects wrap an LLM.
AutoOps simulates how AI would actually operate inside production infrastructure.
What we learned
Pure LLM output is insufficient for production-grade systems.
Deterministic safeguards are mandatory.
Visual propagation mapping improves incident comprehension dramatically.
Human approval must remain central in self-healing systems.
Incident response blends infrastructure, AI reasoning, and human psychology.
AI should assist the commander — not replace operational discipline.
What's next for AutoOps — Self-Healing AI Control Plane
AutoOps is currently a simulation layer.
Next steps include:
Direct Kubernetes API integration
Real OpenTelemetry ingestion
Terraform / AWS execution adapters
Policy-driven auto-remediation guardrails
Multi-region blast radius modeling
Historical incident memory & adaptive learning
Autonomous rollback decision engines
The long-term vision:
AutoOps evolves into a real AI-powered Incident Command System — operating inside production, not beside it.
Built With
- deepgram
- events
- gemini
- next.js
- node.js
- pdf-lib
- react
- server-sent
- typescript
- webhook

Log in or sign up for Devpost to join the conversation.