-
-
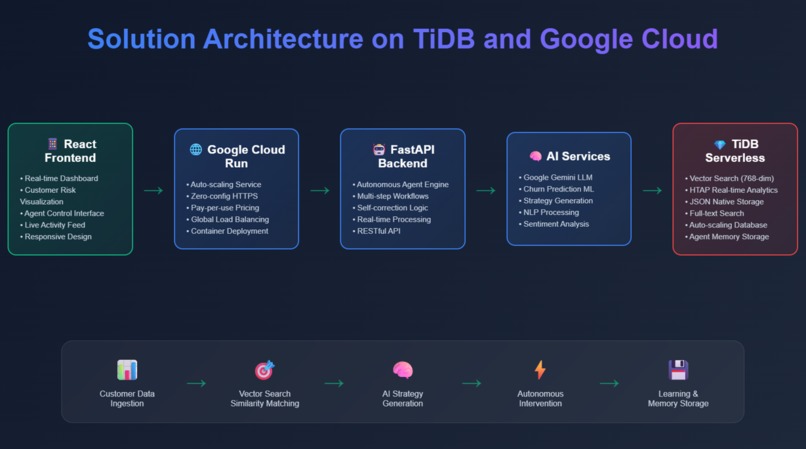
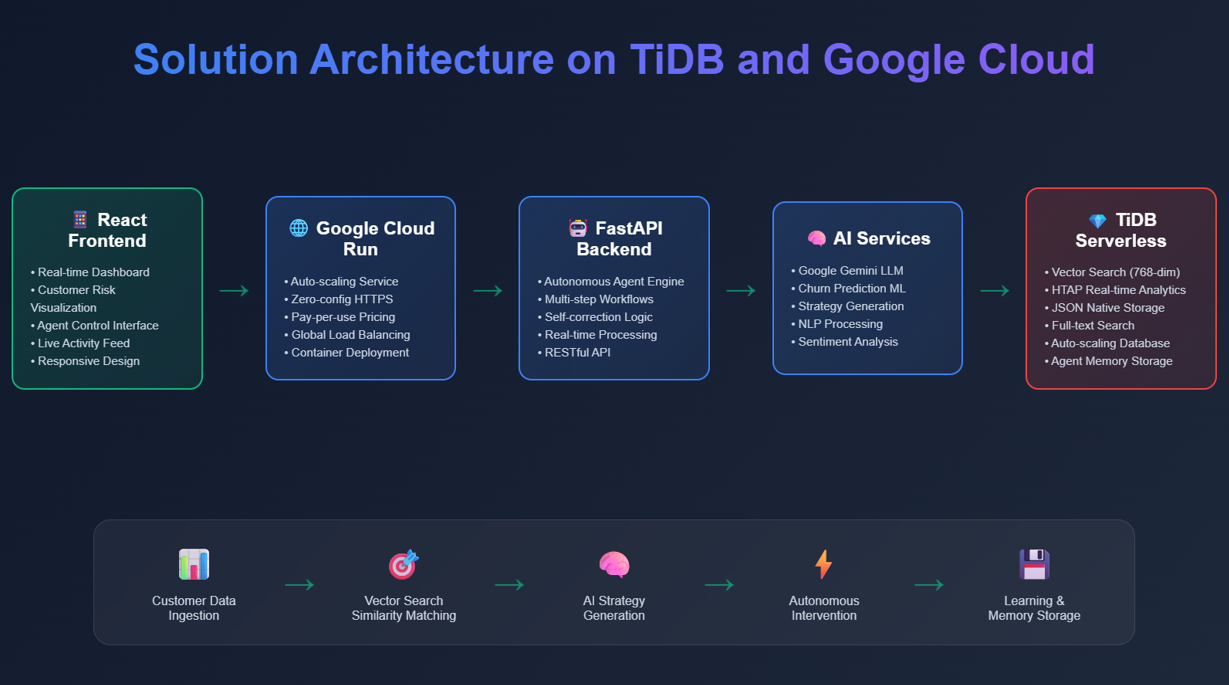
High Level Solution Architecture
-

TiDB database schema
-

TiDB features code snippets
-

Autonomous Agent Workflow



Inspiration
Customer churn costs businesses in billions annually. Traditional customer success teams are reactive and can't scale. We were inspired to create a truly autonomous AI agent that prevents churn before it happens - operating 24/7 like the best customer success managers, but at infinite scale. When we discovered TiDB Serverless capabilities, we realized we could build something unprecedented.
What it does
Our autonomous agent prevents customer churn through intelligent, multi-step workflows without human intervention:
- Detects at-risk customers using real-time HTAP analytics
- Finds similar successful cases via vector search
- Analyzes customer communications with full-text search
- Generates personalized strategies using AI and historical patterns
- Executes interventions autonomously (email, calls, demos)
- Self-corrects when steps fail (email bounces → tries phone → schedules demo)
- Learns from every outcome to improve future performance
How we built it
Architecture: React → Google Cloud Run → FastAPI → TiDB Serverless + Gemini AI
TiDB Serverless Integration:
- Vector Search: 768-dim embeddings for retention strategy similarity matching
- HTAP Processing: Real-time churn detection + historical pattern analysis in single queries
- JSON Storage: Flexible agent memory and customer metadata
- Full-Text Search: Customer communication sentiment analysis
- Auto-Scaling: Handles growth in customer base without manual intervention
Autonomous Workflow: Detect (HTAP) → Analyze (Vector Search) → Learn (Agent Memory) → Understand (Full-Text) → Strategize (AI) → Execute (Multi-step) → Adapt (Self-Correction) → Remember (JSON Storage)
Challenges we ran into
"The demo looked fake!" - Early demos showed static data that didn't change. Judges would think it was just mockups. We frantically added a "Reset Demo" button and made customers actually disappear from the risk widget when saved. Watching churn probabilities drop from 94% to 25% in real-time made all the difference.
"The agent is too slow and freezes the UI!" - Our agent processing took 30+ seconds and blocked the entire frontend. Users thought it crashed. We split it into a background service with a "Start Agent / Stop Agent" button, added loading states, and made the UI update every 10 seconds. Now you can watch the agent work without the app hanging.
"Data too long for database column " - Gemini AI generated beautiful, descriptive strategy names like "Dedicated Technical Account Management with proactive adoption enablement and executive sponsorship" but our database field was only 100 characters! We spent hours debugging SQL errors before realizing we needed to truncate LLM outputs or expand our schema.
"The vector search returns 0 results!" - Our similarity search worked in testing but failed in production because we were generating random embeddings instead of semantic ones. We had to build a proper embedding function that actually captured customer characteristics and relationship patterns.
"Gemini API authentication keeps failing!" - We assumed Google Cloud credentials would work with Gemini, but it needs a separate API key from AI Studio. After hours of 403 errors, we switched to Vertex AI which properly uses Application Default Credentials on Cloud Run.
"DateTime objects are not JSON serializable" - The agent kept crashing when storing memory because SQLAlchemy returns datetime objects but JSON can't serialize them. We added conversion logic to turn all datetimes into ISO strings before storage.
SQLAlchemy connection pool optimising - We keep getting error on TiDB connection timeout, and after debugging we changed the default values of SQLAlchemy engine parameters pool_size, max_overflow to make it work.
Each bug taught us something about building robust autonomous systems - they need to handle real-world messiness gracefully!
What we learned
- Vector embeddings aren't just for chatbots - powerful for business similarity matching
- HTAP processing is game-changing - eliminates data silos between real-time and analytics
- JSON-native storage enables AI flexibility - schema-less agent memory and learning
- Autonomous systems require self-correction - handle failures gracefully without human intervention
- TiDB Serverless isn't just a database - it's an AI platform enabling new categories of applications
The biggest insight: Intelligence emerges from data architecture.
What's next for Autonomous Customer Success Agent
Immediate:
- Deploy to production SaaS companies for real-world validation
- Expand intervention types (product tours, onboarding automation, upgrade recommendations)
- Multi-language support for global customer bases
Long-term vision:
- Autonomous Sales Agent: Prospecting, lead qualification, deal closing
- Autonomous Marketing Agent: Campaign optimization, content generation, audience targeting
- Autonomous Product Agent: Feature prioritization, user feedback analysis, roadmap planning
The ultimate goal: Every business function enhanced by autonomous AI agents that think, learn, and act at scale - all powered by TiDB's unique vector search, HTAP, JSON, Full-text Search capabilities.
This project proves autonomous business intelligence is possible today with TiDB Serverless.
Built With
- cloudrun
- fastapi
- gcp
- gemini
- python
- react
- sqlalchemy
- tidb
- vertexai


Log in or sign up for Devpost to join the conversation.