-
-
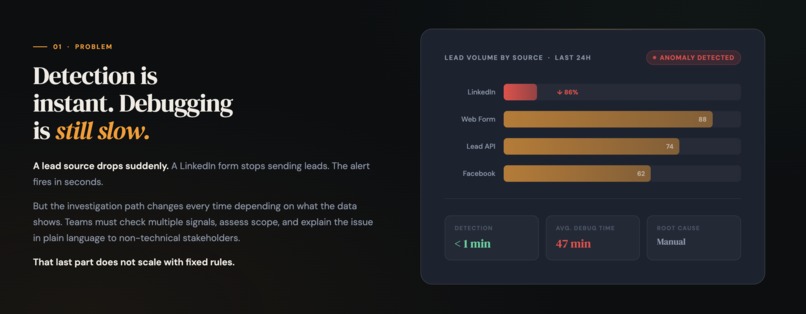
Problem
-
Nova analysis example 1
-
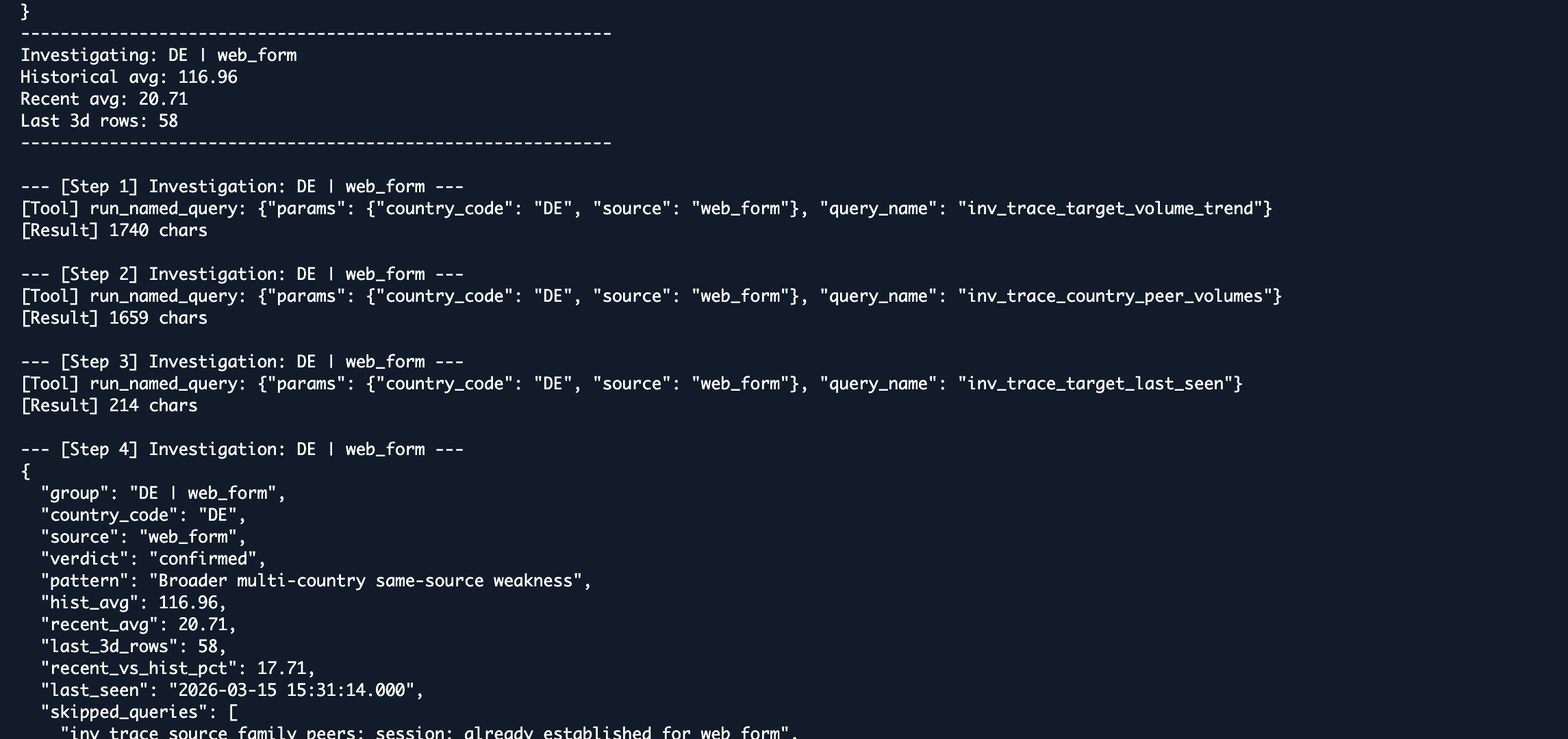
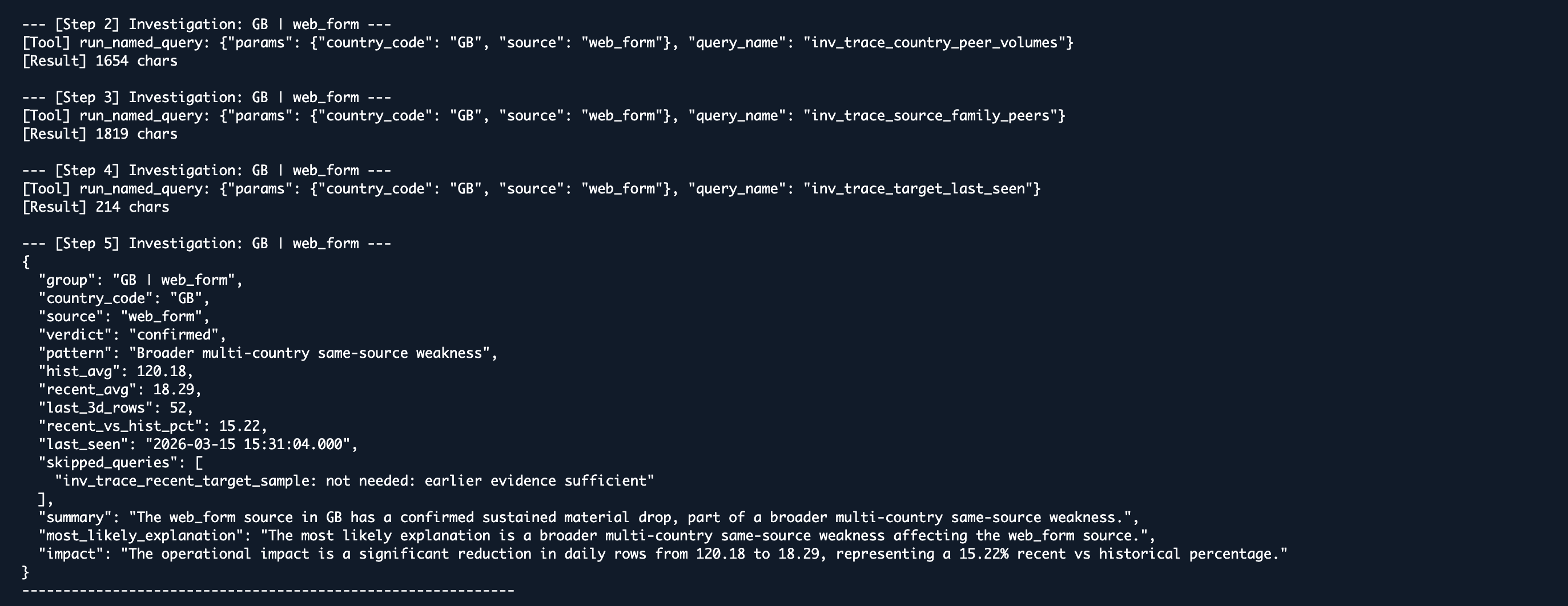
Nova analysis example 2
-
Tools shared with Nova

Inspiration
This project came directly from a problem I lived with for a long time working closely with CRM data.
When a lead source drops overnight, you know something is wrong within minutes. What you do not know is why. Is it isolated to one country? One source family? Did the pipeline fail at a specific timestamp, or was it a gradual decline? Every incident looked similar on the surface but required a different investigation path underneath. I found myself running the same categories of SQL queries, in slightly different orders, for slightly different reasons and then translating the findings into plain language for non-technical stakeholders who needed to act on them.
It was repetitive, it was slow, and there was no obvious way to generalize it with fixed rules because the right path always depended on what the data showed. That gap is where this project lives.
What it does
The Autonomous CRM Incident Investigator detects, traces, and diagnoses CRM data pipeline anomalies autonomously specifically, lead source volume drops and produces a clear, evidence-backed operational summary without any human intervention.
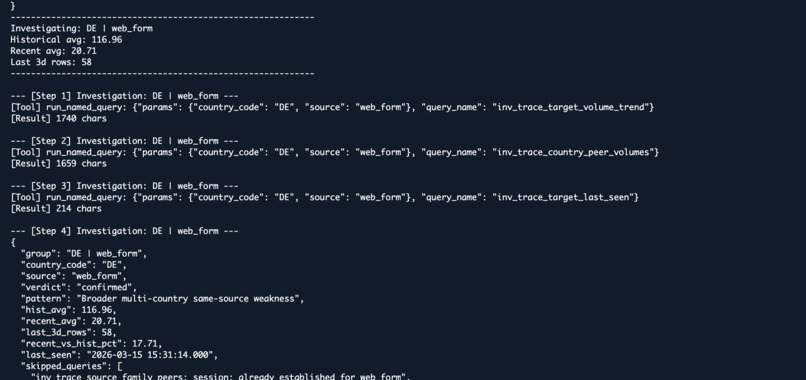
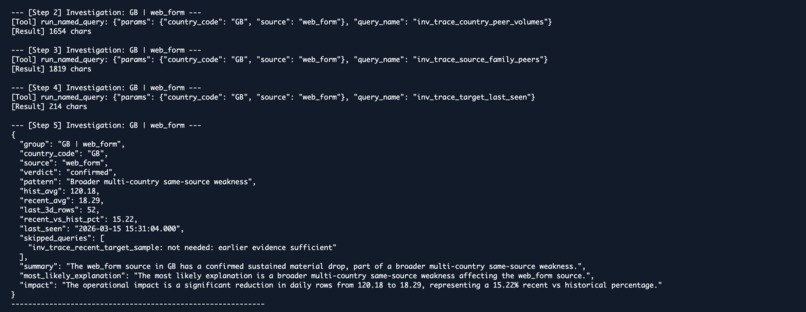
It works in two stages. First, a preparatory query scans the last 28 days of CRM data against the last 7 days to flag any source and country combination experiencing a severe volume drop above 50%. Second, for each flagged anomaly, Amazon Nova Pro V1 takes over the investigation deciding which of the pre-registered Athena queries to run, in what order, and when to stop.
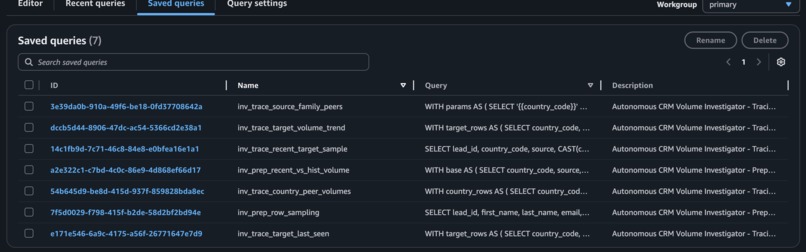
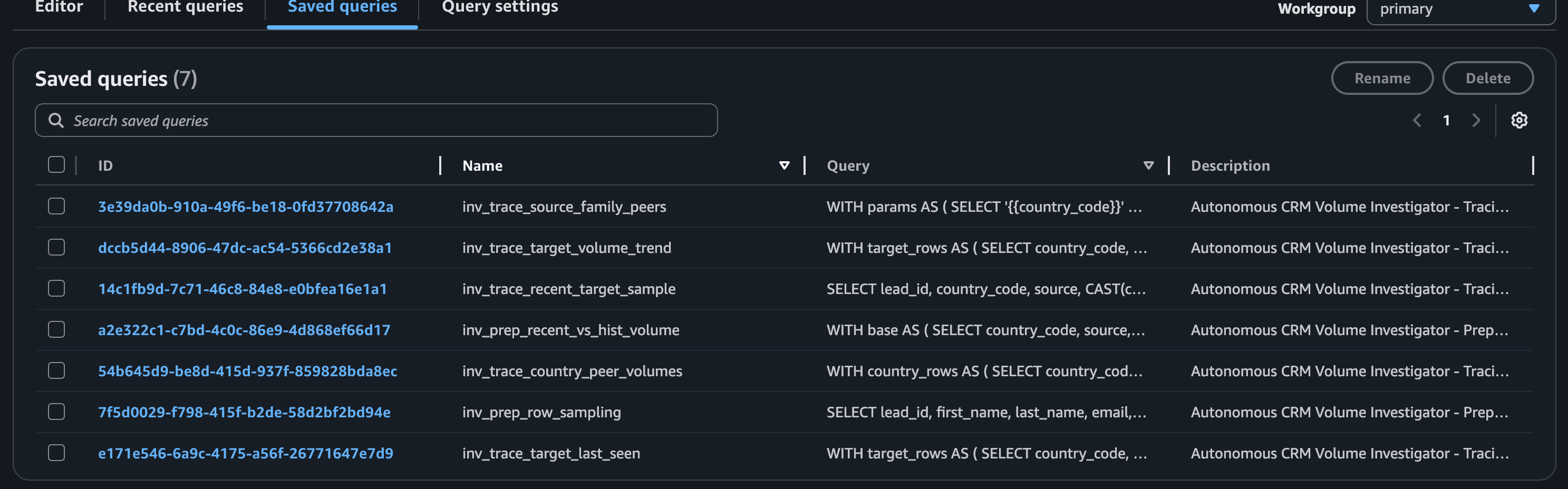
The available tools cover the full hypothesis space for this class of incident: day-by-day trend, country peer volumes, source family peers across countries, last-seen timestamp, and a final row sample for inspection. Nova does not have access to arbitrary SQL. It has access to exactly the queries that matter, and it reasons about which ones are necessary given what it has already found.
Session memory handles multi-anomaly deduplication. If Nova establishes a broader multi-country weakness on the first flagged anomaly, that finding is injected as context for subsequent investigations so redundant queries are skipped entirely. The final output is a validated, strictly typed JSON verdict saved alongside a full investigation log.
How we built it
The core stack is Amazon Nova Pro V1 on Amazon Bedrock with Amazon Athena Named Queries as the bounded tool set. The agent is orchestrated in Python using Boto3, with no external agent frameworks the agentic loop, tool execution, and session memory are all implemented directly.
A synthetic dataset of 500,000 rows spanning five months was generated with deterministic anomalies injected into the final week: an isolated drop on FR | LinkedinForm and an 85% drop across GB | web_form and DE | web_form. This gave a realistic and reproducible environment to develop and test the investigation logic against.
The Athena Named Queries were registered programmatically via a bash setup script, keeping the tool definitions version-controlled and portable. Session state is managed via SourceSessionState and CountrySessionState Python structs that carry findings across anomaly iterations.
Challenges we ran into
The central challenge was giving Nova enough reasoning room to be useful while keeping it from drifting into hallucination.
With temperature = 0, the model is deterministic but can become overly conservative it may refuse to commit to a verdict when the evidence is strong enough to justify one. Raise the temperature and it starts filling gaps with inferences not grounded in the query results. Finding the balance between those two failure modes took significant iteration on the system prompt and the evaluation rules. The final design forces Nova to cite hard numbers actual row counts and percentage drops before confirming any verdict. That constraint does most of the work.
Accomplishments that we're proud of
The session memory deduplication works exactly as intended. When Nova establishes a multi-country weakness on the first anomaly, subsequent investigations skip the source-family query entirely without being explicitly told to. That behavior emerges from the injected context, not from hard-coded logic. It is the system reasoning, not just executing.
The bounded tool design also holds up under the adversarial test cases in the synthetic dataset. Nova does not hallucinate a root cause when the evidence is ambiguous it reports what the data shows and stops there.
What we learned
Nova Pro V1 surprised us. Given that it is not the latest model in the family, we expected to hit reasoning limits on the more ambiguous investigation paths. It handled them cleanly. The native integration with the AWS infrastructure also made the development experience genuinely smooth in a way that working across platforms does not.
The bigger lesson was conceptual. The most productive thing you can do with a capable model is not give it everything it is define the boundaries carefully and let it work inside them. Bounded tooling is not a limitation. It is what makes the system trustworthy, cost-efficient, and auditable. The intelligence shows up most clearly when the space it operates in is well-defined.
What's next for Autonomous CRM Incident Investigator
The current system is scoped to lead source volume drops. The same architecture generalizes to any class of CRM data incident where the hypothesis space can be defined in advance: conversion rate anomalies, duplicate record spikes, field-level data quality failures. The next step is abstracting the tool registration layer so new investigation types can be added without touching the core agent logic.
A real-time trigger integration with an alerting system would close the loop moving from a tool you run manually to one that fires automatically when the detector flags an anomaly.
Built With
- amazon-web-services
- athena
- bedrock
- boto3
- cloudshell
- python
- s3
- sql

Log in or sign up for Devpost to join the conversation.