AIAI: The Identity Engine
Build AI with AI — custom intelligence anyone can ship.
AIAI is a chat-first, no-code AutoML factory that turns a plain-English goal into a trained model you can export and reuse. The core idea is democratizing customizable AI: you shouldn’t need a PhD to create a model that fits your community, business, or personal workflow.
Inspiration
Identity is the blueprint of who we are and in the digital world, identity is constantly interpreted by algorithms we don’t own.
We built AIAI to close that gap by making custom AI creation accessible. Instead of downloading a template model and hoping it fits, anyone can describe what they need (fraud signals for their shop, classification for their dataset, a text classifier for their community) and generate a tailored model pipeline from conversation.
Trust still matters — so AIAI makes the process observable (metrics + artifacts + stage-by-stage workflow), but the why is simple: give people ownership over their own intelligence.
What It Does (Problem → Solution)
The Problem
Creating custom machine learning is still locked behind:
- notebooks,
- brittle glue code,
- confusing preprocessing,
- and long feedback loops.
So most people either don’t build ML at all, or they adopt one-size-fits-all “AI” that doesn’t match their data, domain, or values.
The Solution
AIAI is a guided AutoML pipeline designed for customization:
- Natural language → model: describe your goal and constraints.
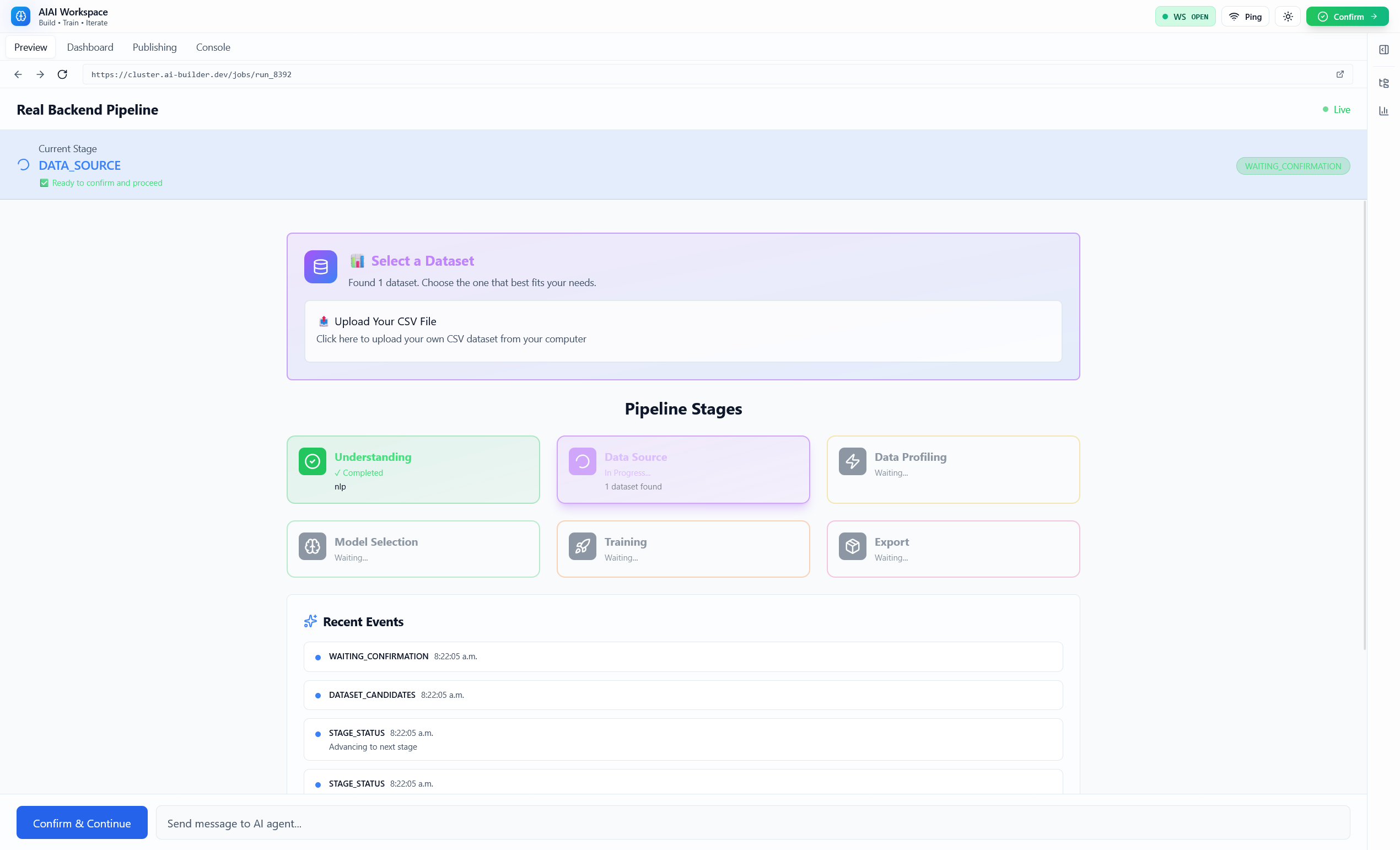
- Stage-based orchestration: intent parsing → data ingestion → profiling → preprocessing → model selection → training → evaluation → export.
- Multi-modal support: tabular, text, and image workflows.
- Safety + trust signals (supporting features): live metrics, explainability artifacts, and privacy-aware profiling warnings.
Agentic AI (Orchestration)
Customization is hard because the system has to translate a vague human goal into a concrete ML plan. AIAI solves this with an agentic workflow that turns “chat” into reliable pipeline actions.
At a high level, AIAI uses specialized agents (with deterministic fallbacks when LLMs aren’t available):
- Prompt Parser: converts a user request into structured intent (
task_type,target,dataset_hint,constraints). - Dataset Finder / Ingestion: helps locate/ingest datasets (upload, Kaggle, and Hugging Face flows).
- Preprocess Planner: profiles data and proposes preprocessing steps (missingness, encoding, scaling, text-column preservation).
- Model Selector: picks candidate models for the task (and exposes a clear model catalog).
- Trainer: runs training and streams telemetry + artifacts.
- Reporter / Notebook Generator: produces human-readable outputs (report/notebook artifacts) to make the result shareable.
This “agent swarm” approach keeps the product no-code and customizable while still being structured and auditable.
Trust Layer: Explainability + Metrics
Explainability is not the headline feature — it’s part of how AIAI earns trust while people build custom models.
- SHAP for tabular runs: when SHAP is installed, the backend generates a SHAP explanations artifact and emits
SHAP_EXPLANATIONS_READY. - Global interpretability: SHAP outputs include feature names and an importance ranking, so users can sanity-check what the model is “looking at”.
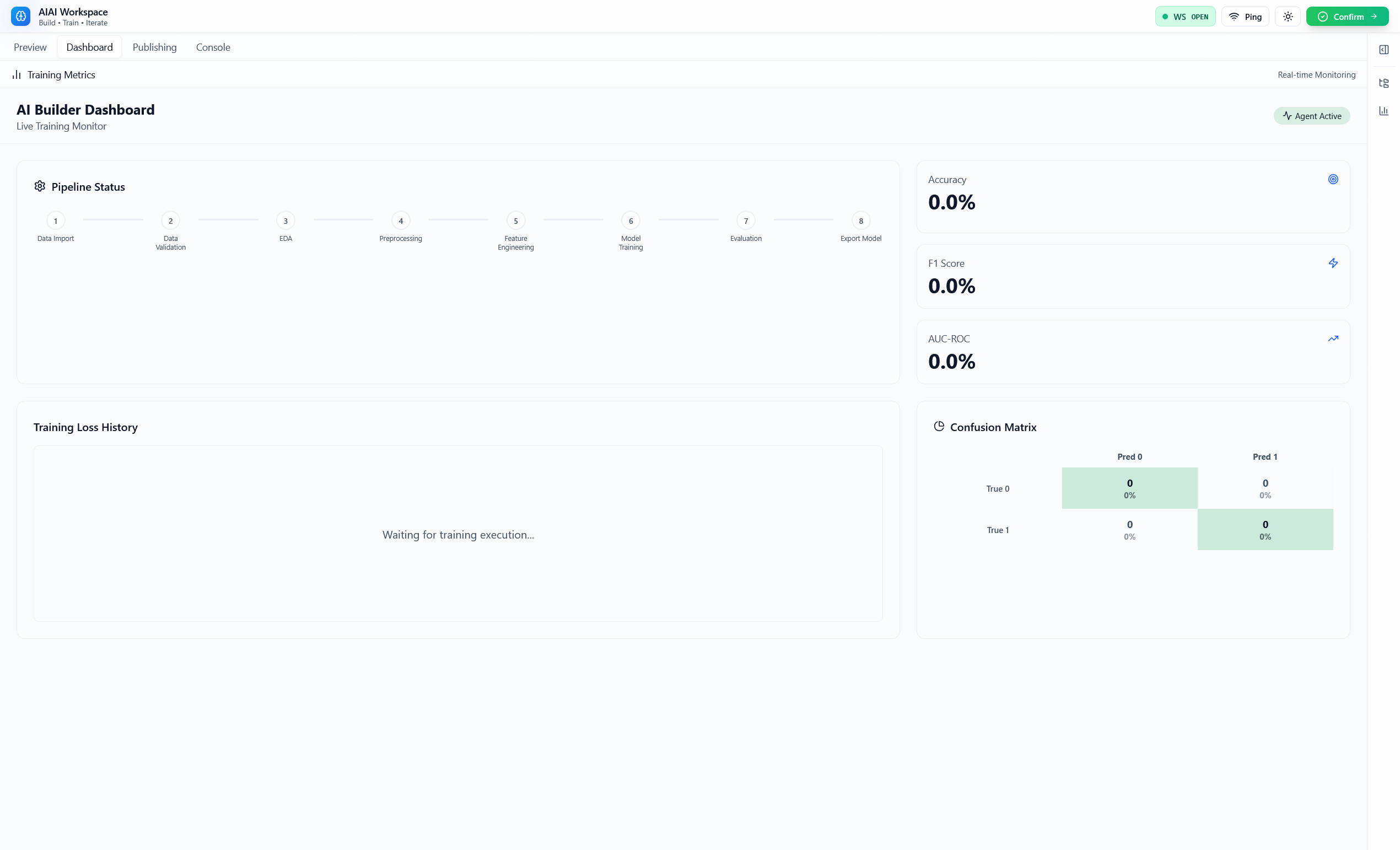
- Metrics beyond “accuracy”: classification includes ROC-AUC, log loss, confusion matrix, per-class stats; regression includes RMSE/MAE/R² and more.
- Artifact-first evaluation: assets like confusion matrices, ROC/PR curves, feature importance, and SHAP summaries are emitted so the UI (and exported bundles) stay consistent across runs.
Real-Time Feedback (WebSockets)
Customization requires fast iteration. AIAI keeps the loop tight by streaming the pipeline as events over WebSockets:
- WebSocket endpoint:
ws://localhost:8000/ws/projects/{project_id} - During training, the backend streams:
TRAIN_PROGRESS(progress + ETA)METRIC_SCALAR(loss/accuracy/F1/etc. points)- evaluation artifacts like
CONFUSION_MATRIX_READY,FEATURE_IMPORTANCE_READY,SHAP_EXPLANATIONS_READY
This makes the ML pipeline feel “alive”: you don’t wait for a silent job to finish — you watch it learn and can adjust your choices.
Privacy & Redactability
We take a pragmatic approach to privacy:
- Profiling emits PII-risk warnings based on column-name and sampled-value heuristics (emails/phones/SSNs/card-like patterns).
- Redaction-first workflow: the warnings are designed to trigger an early decision to redact, hash, or drop sensitive columns before training or exporting artifacts.
- Text-aware preprocessing: for NLP tasks, AIAI preserves detected text columns (instead of blindly encoding them), reducing accidental leakage via “encoded identifiers”.
Next step (roadmap): stronger policy-driven redaction + federated learning.
Supported Models (14 total across 4 task types)
Tabular Classification
- Logistic Regression (
logreg) (mapped to Random Forest in trainer for robustness) - XGBoost Classifier (
xgb_clf) default - Random Forest (
rf_clf) - Gradient Boosting (
gb_clf) (mapped to XGBoost in trainer)
Tabular Regression
- Linear Regression (
linreg) (mapped to Random Forest in trainer for robustness) - XGBoost Regressor (
xgb_reg) default - Random Forest Regressor (
rf_reg) - Gradient Boosting Regressor (
gb_reg) (mapped to XGBoost in trainer)
Text Classification (Transformers)
- DistilBERT (
distilbert-base-uncased) default - BERT Base (
bert-base-uncased) - RoBERTa (
roberta-base)
Image Classification (Transfer Learning)
- ResNet50 (
resnet50) default - EfficientNet-B0 (
efficientnet_b0) - ViT-B/16 (
vit_b_16)
How We Built It
- Backend: FastAPI + a contract-driven event bus that broadcasts to WebSocket clients.
- Frontend: React + TypeScript + real-time stores that consume
TRAIN_PROGRESS,METRIC_SCALAR, and artifact-ready events. - Orchestration: intent parsing + model selection agents feeding a staged pipeline.
- ML:
- Tabular: scikit-learn + XGBoost
- Text: HuggingFace Transformers
- Vision: PyTorch + torchvision transfer learning
- Explainability (supporting): SHAP for tabular runs.
Challenges We Ran Into
- Making customization feel simple: mapping natural language goals to concrete ML tasks/models without forcing users into jargon.
- Real-time feedback: streaming metrics while training without freezing the app required an event-driven architecture.
- Consistent outputs across model families: we standardized around artifacts + events so the UI can render training/eval/explainability consistently.
- Privacy vs. usability: we wanted guardrails without blocking users, so we emit risk warnings early in profiling.
Accomplishments We’re Proud Of
- Turning “custom ML” into a chat-first, no-code workflow.
- Real-time model training telemetry over WebSockets.
- Trust features (metrics + artifacts + optional SHAP) integrated into the pipeline instead of bolted on.
What’s Next
- More customization knobs (cost/latency constraints, model families, and guided trade-offs).
- Federated learning (train on-device / private data stays local).
- Stronger redaction policies + configurable compliance modes.
- A marketplace for reusable “identity models” and pipelines.

Log in or sign up for Devpost to join the conversation.