-
-

Posters
-
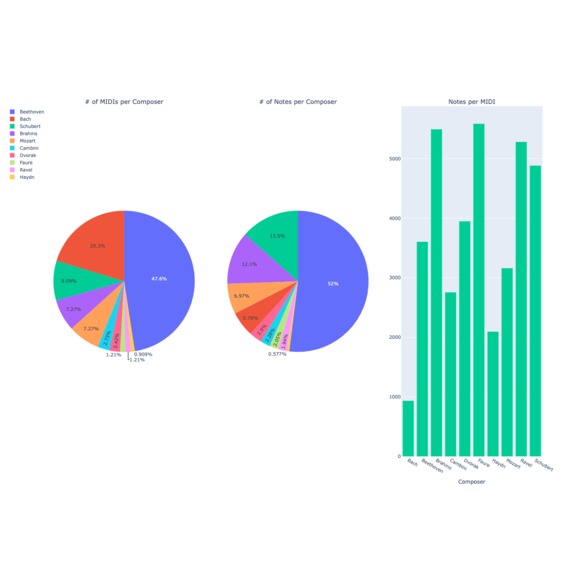
MusicNet dataset overview
-
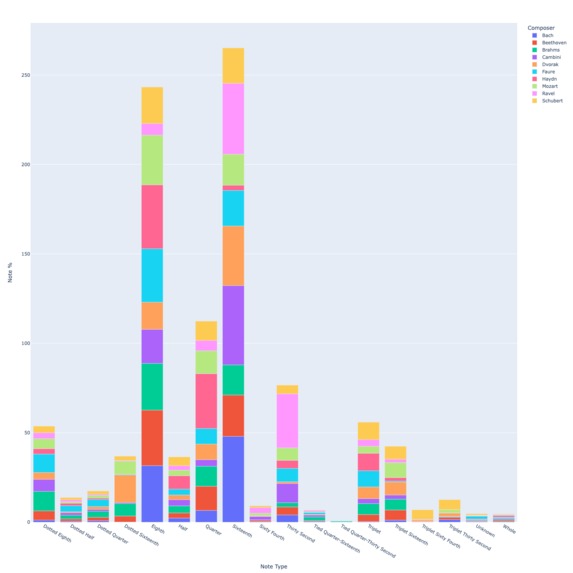
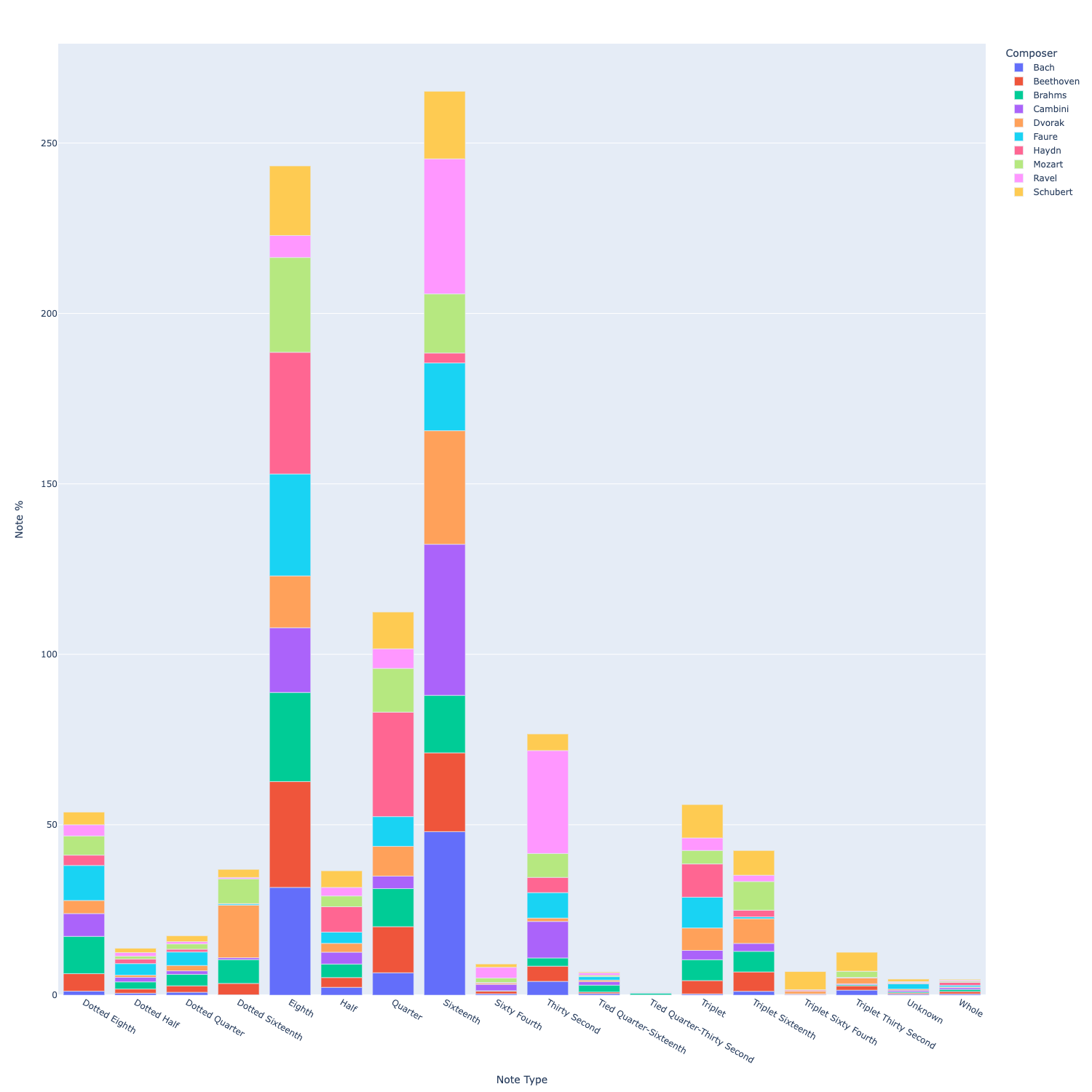
Note types/durations by composers
-
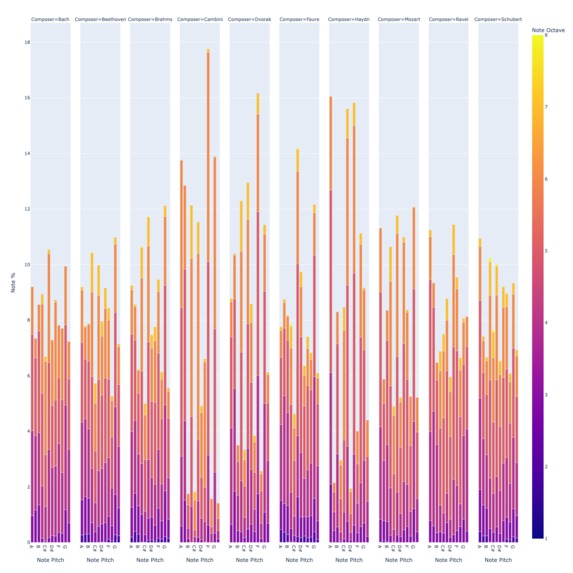
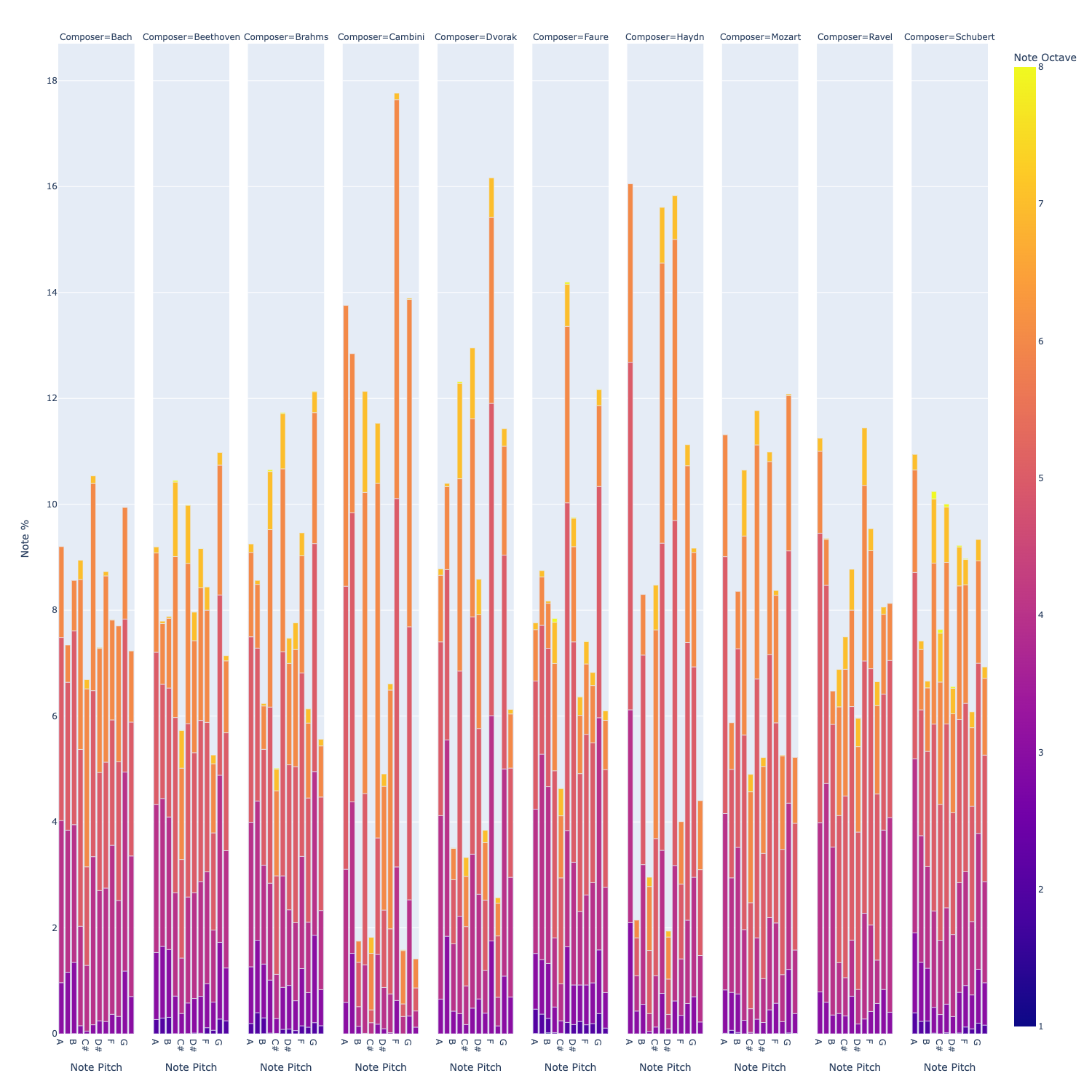
Note pitches & octaves by composers
-
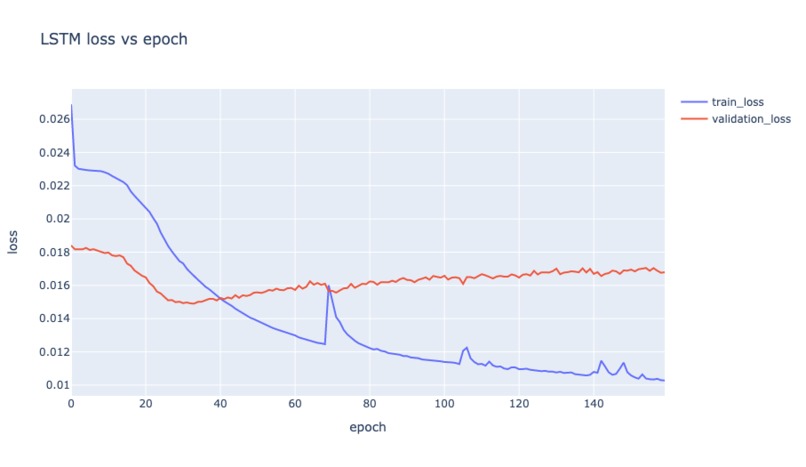
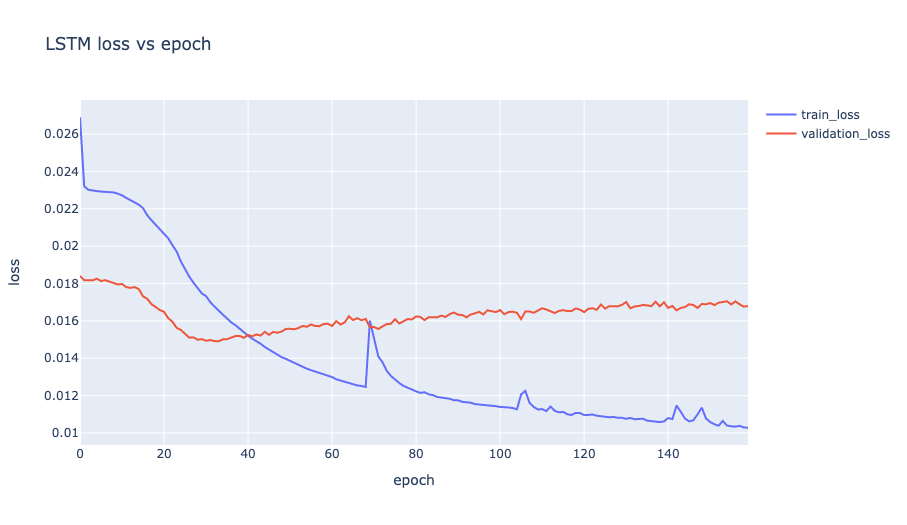
LSTM loss vs epoch
-
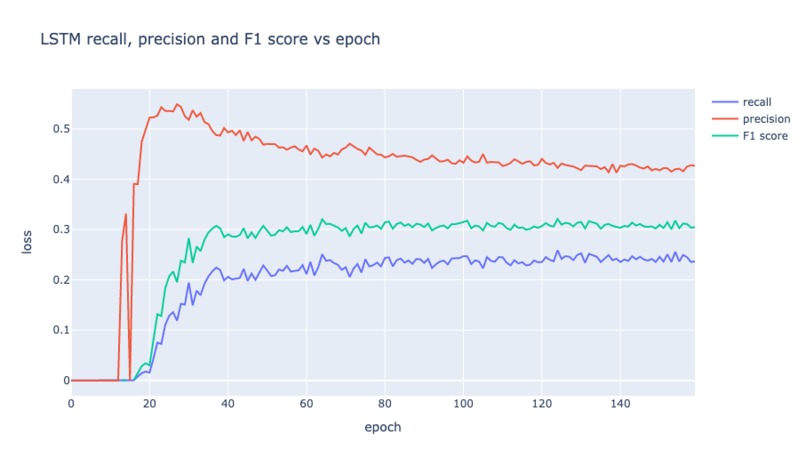
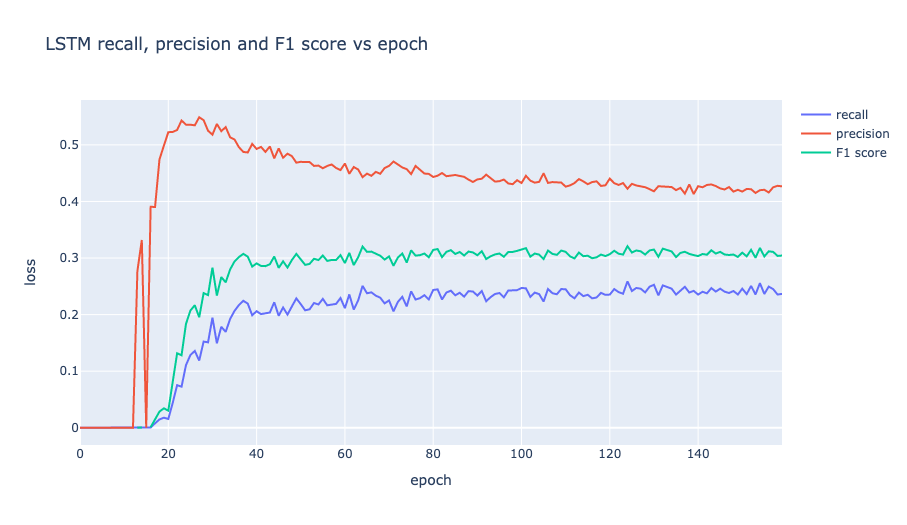
LSTM recall, precision and F1 score vs epoch
-
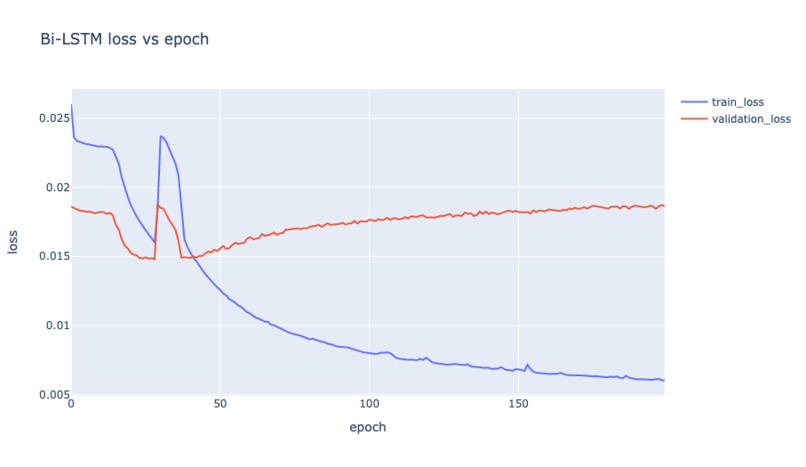
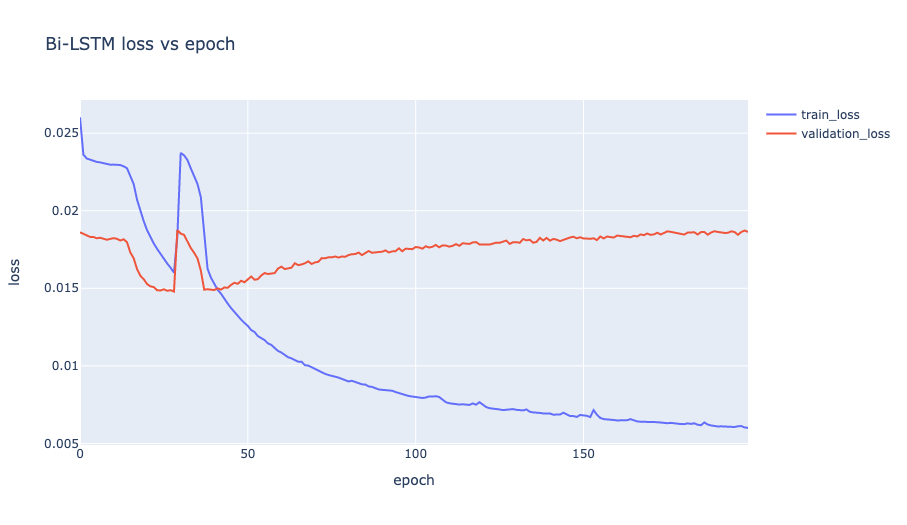
Bi-LSTM loss vs epoch
-
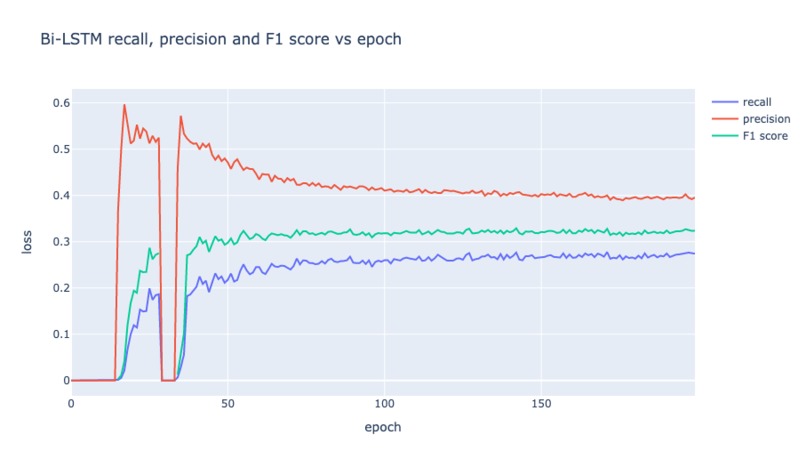
Bi-LSTM recall, precision and F1 score vs epcoh
-
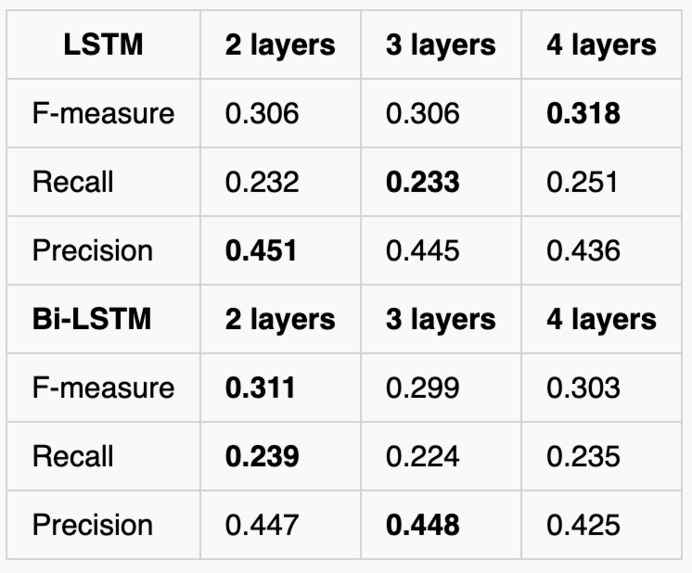
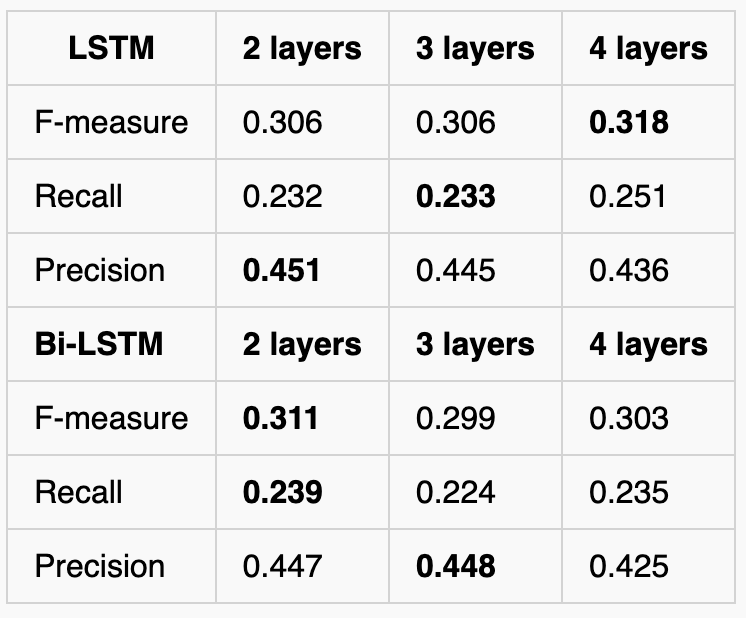
LSTM and Bi-LSTM performance with different number of hidden layers



Introduction
Nowadays, deep learning seems to play an increasingly important role in aspects like image detection, computer vision, medical and business analytics. However, other realistic problems where deep learning can be employed to address some prominent issues. Music transcription is considered to be one of the difficult problems in music information research. Music transcription typically relies on expertise and well-trained ears, while music transcription is formulaic and crucial in music. Automatic music transcription (AMT) would be able to reverse-engineer symbolic representation of musical audio signals. Potential applications include recognizing songs automatically while listening to songs which can be used for Apps like Apple Music and Spotify. Another application could be improved identification of musical genres through the analysis of the notes rather than just the frequency signature. We intend to use DNN and LSTM to build this audio-to-score conversion.
Data
We use the MusicNet dataset, which collects 330 free-licensed classic music recordings with over 1 million annotated labels indicating the precise time of each note in every recording, the instrument that plays each note, and the note's position in the metrical structure of the composition. To generate inputs for our model, we will have to first down sample the audio and convert the audio file into time-frequency representation. In order to deal with audio file directly, we should transform them into spectrograms with extra features. Available preprocessing methods include SIFT (Short-Term Fourier Transform), MFCC (Mel Filterbank Cepstrum) and CQT (Constant Q Transform). Compared to other methods, CQT has advantages that constant center frequency-to-resolution ratio results in constant pattern of sounds with harmonic components in logarithm-scaled frequency domain, which is easier for resolving notes that are played simultaneously.
Related Work:
There exists a multitude of approaches to do AMT. While the end goal of AMT is to convert an acoustic music recording to some form of music notation, most approaches were designed to achieve a certain intermediate goal. Depending on the level of abstraction and the structures that need to be modeled for achieving such goals, AMT approaches can be generally organized into four categories: frame-level, note-level, stream- level and notation-level. The state of art approaches fall into two algorithmic families: Non-Negative Matrix Factorization (NMF) and Neural Networks (NNs), which are both frame level approaches. In existing researches for the network architectures, with supervised learning based on each music note, the combination of CNN and RNN and some comparisons between DNN and LSTM are often mentioned. In paper A holistic approach to polyphonic music transcription with neural networks, it introduces Convolutional Recurrent Neural Network(CRNN) as well as Connectionist Temporal Classification(CTC) loss function.
URLs:
Learning Features of Music from Scratch
Invariances and Data Augmentation for Supervised Music Transcription
Automatic Music Transcription: An Overview
A holistic approach to polyphonic music transcription with neural networks
Methodology:
Our model takes the spectrogram of audio as input, and output the estimation of music notes for each time frame. Since the input data includes time sequence information, we prioritize using LSTM, which is typically good at modeling sequence data. LSTM takes input of shape [batch_size, timestamps, features]. In our case, we choose an appropriate window size in the time domain of the spectrogram. The features are the frequency bins of the spectrogram. In terms of loss, we use one-hot encoding to process the music notes (y value) into 128 dimensional vectors, then use mean squared error as the loss function.
For the purpose of model comparison, we also explored DNN, Bi-LSTM and transformer on the same task.
Metrics:
We evaluate our model based on accuracy, precision, recall and F1 score. These are all evaluated based on our model’s predictions and ground-truth music notes.

After researching related works, we devised our goals: our base goal is 0.5 F1 score on the test set; our target goal is 0.55 F1 score on the test set; our stretch goal is 0.6 F1 score on the test set.
Ethics:
Why is Deep Learning a good approach to this problem?
Educating a qualified music transcriber is time consuming and requires a lot of training and practice. Traditionally, hiring a freelance musician to turn a song into a music sheet will be most people’s choice. However, this service is not transparent at all. It’s easier to transcribe human vocal or monophony musical instruments and much more difficult to transcribe polyphonic instruments like in a symphony. Therefore, a good quality of transcribed music sheet by ear cannot be guaranteed and satisfying music transcription service can be pricey and hardly affordable. The occurrences of techniques in Deep Learning make Automatic Music Transcription (AMT) possible. By embracing deep learning, AMT will be a service accessible to everyone. It saves labor and money; music transcription skill is not a necessity for a music lover anymore. In addition, it provides a metric and a baseline to determine and evaluate how good a transcription can potentially help music education, creation, and production.
Who are the major “stakeholders” in this problem, and what are the consequences of mistakes made by your algorithm?
Music practitioners and music lovers are the major stakeholders. The AMT project aims to provide a reliable and easy-accessible service for them. The AMT can be a metric to evaluate the ability of music transcription. If the consequences of mistakes made by our algorithm can mislead the evaluation. Students who’re learning music transcription can also be taught wrongly. What should be elucidated is that it’s not a reasonable expectation that the AMT can achieve a universally correct music sheet for a song because sometimes even the ‘original’ music sheet is changing from time to time during each performance. Therefore, the AMT requires human intervention and supervision to achieve an optimized result.
Checkin 2 Reflection
https://docs.google.com/document/d/1Ep6AZp7EWOR70zmYo5txI7nS_Gjjnu--Tz6UHa3yLlo/edit
Final Writeup
https://docs.google.com/document/d/1DqbwxTCxc_N3MHtw2C-k4B2jJOspegQ85KsQx5gfOD4/edit#
Built With
- plotly
- tensorflow
 Shen")
Log in or sign up for Devpost to join the conversation.