-
-
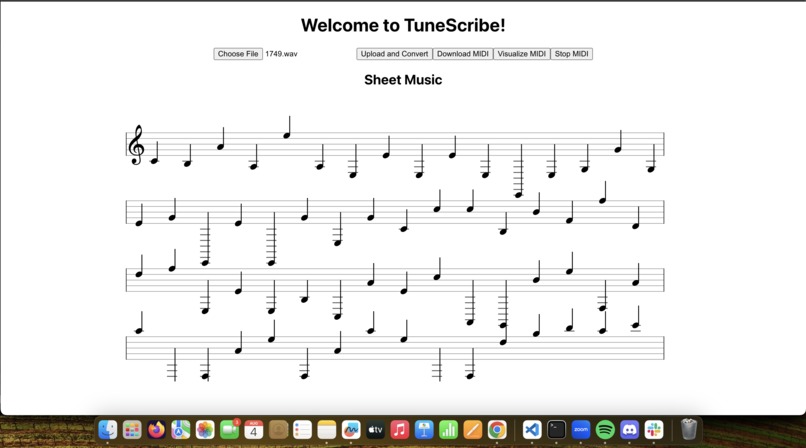
Front end
-
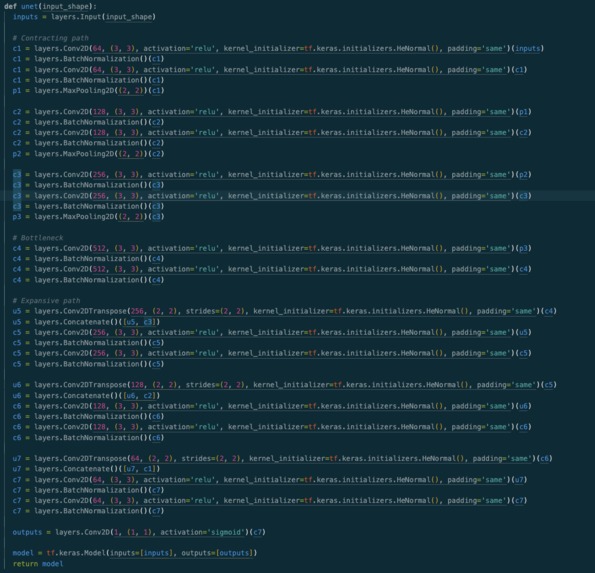
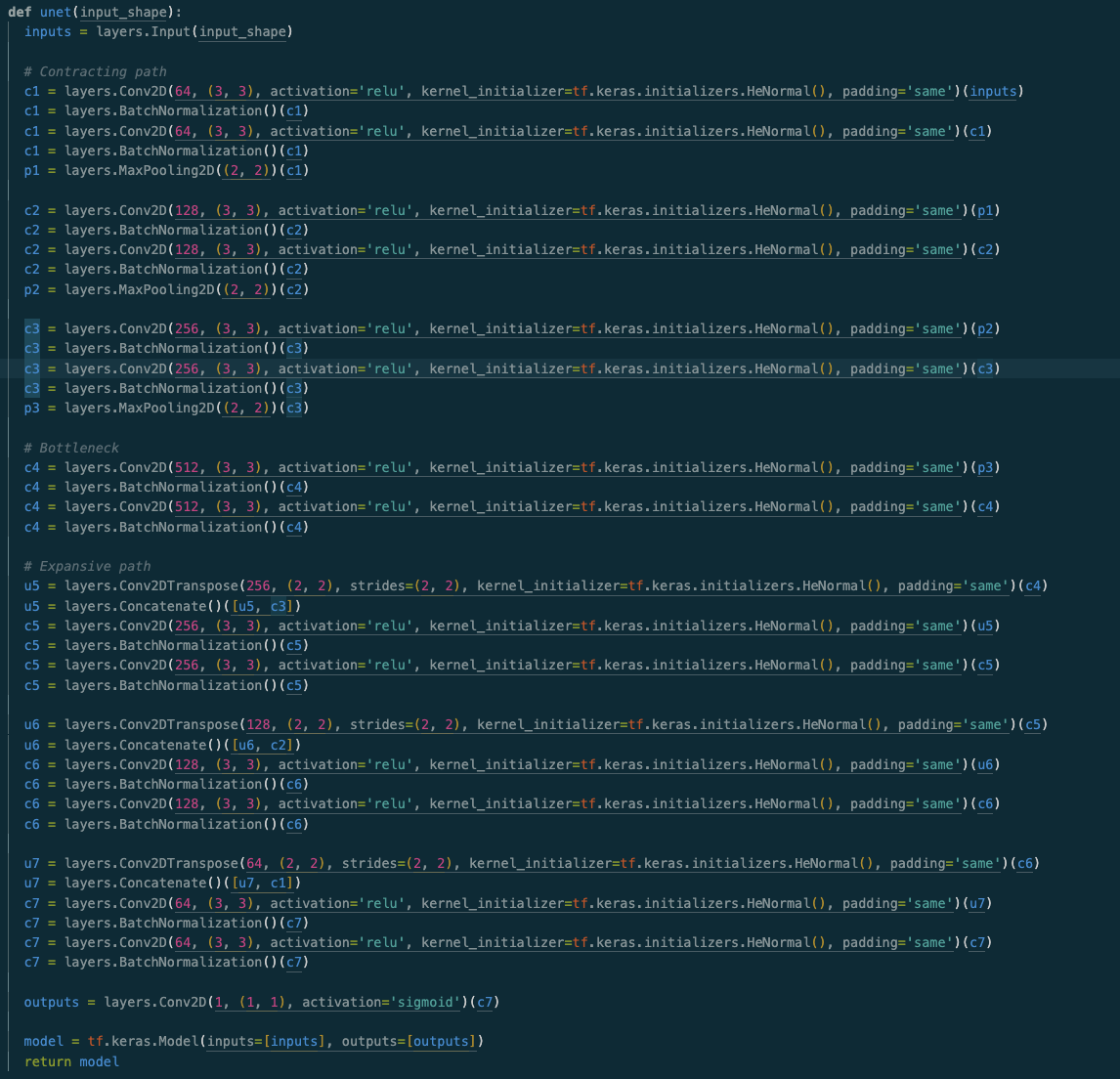
Model Architecture
Inspiration
Tom and I are huge music lovers!!! I play piano daily and enjoy learning anything from classical to anime piano (ask me to play Animenz' Unravel :) ). Tom is easily the best violinist I've ever met and he has perfect pitch (a skill we ended up using a lot to test our model's quality!). Often after listening to soundtracks in the latest videogames, TV Shows, or movies, me, Tom, and our other musician friends feel inspired to learn the songs that we listen too. However, high quality soundtrack transcriptions for the newest music out there takes a long time to develop because a human must have years of experience in music theory to even create good sheet music. Thus, we decided to we'd use our knowledge of deep learning, specifically semantic segmentation with the U-Net architecture, to create TuneScribe: a web service that generates high quality sheet music within minutes.
What it does
A user can go onto our React website TuneScribe and upload a soundtrack from their favourite videogame or movie and upload it to our backend.
Our Flask backend applies a mel spectrogram using the librosa library to extract frequency-time features from the raw data and feeds it as input to our deep learning model.
Our deep learning model, built in Tensorflow, returns a 2D matrix of shape (timesteps, num_notes = 128), the predictions of whether or not a certain note is playing at a certain time.
Our backend uses mido to generate a midi file from our model predictions and sends a midi file back to the front end
In the React front end, we use the VexFlowJS library to create sheet music for our midi file and the ToneJS library to play the midi file for the user.
How we built it
Data Preprocessing Our model is trained on the MusicNet dataset, an open dataset of 330 classical music recordings consisting of audio from the following instruments: Piano, Violin, Viola, Cello, Clarinet, Bassoon, Horn, Oboe, Flute, Harpsichord, and the String Bass. Using the librosa library, we downsample each song to 11025 Hz. This is done because the highest note in the dataset has a frequency of 4096 Hz and by Nyquists Theorem, at least 8192 Hz is needed to accurately sample upto 4096 Hz. Once the audio is downsampled, we apply a mel spectrogram with window size 4096 and hop length 2048 or roughly 4096/11025 ~= 1/3 second time windows. As for our labels, they are downsampled to fit the dimension of the audio. Finally, we prepare the data into (batch_size, 16, 128, 1) mel spectrograms and labels for training in our deep learning model
Machine Learning Our model is based on the U-net architecture. Our motivation is that visually, mel spectrograms kind of look like images where the brightness represents the strength of a frequency playing at a certain time. This reminded us a lot of other semantic segmentation tasks and we thought we could get good results this way. Moreover, traditional architectures use traditional CNN/Transformer architectures. We leverage 4 L4 GPUs for distributed training using modal.com's GPU offerings and free credit and trained our model for 100 epochs with the ADAM optimizer, a learning rate of 0.001, and a learning rate scheduler. After training, we were able to achieve 67% precision and 99% recall on our training dataset.
Backend We save our trained models weights in an h5 file and turn that into a Flask API endpoint in our backend. Our endpoint takes in a .wav file and prepares the audio in the same way as the audio preprocessing stage. Then, our model does inference on it and we use backend logic to turn our model predictions into a midi file that is returned to our React frontend
Frontend Our React frontend has an upload button that allows you to upload .wav files. Once you have uploaded a file, you can convert the audio into midi. In the frontend, we use VexFlow to render sheet music based on the midi, and if you click visualize midi, it plays the contents of the midi file using ToneJS.
Challenges we ran into
Signal processing is the most important part of training a robust deep learning model, a model is nothing without good data. We spent our entire Friday night and Saturday morning playing around with different window lengths, hop lengths, and other data preprocessing issues, training our model on Google Colab for short epochs as a proof of concept of the viability of a certain data preprocessing procedure.
Another big issue for us was finding a Cloud Computing service on the spot. Tom and I made the mistake of assuming we could leverage distributed training on AWS or GCP without any issue but you have to submit a quota increase request for use multiple GPUs! Moreover, it takes AWS or GCP 2-5 business days to respond... We thought we were cooked until we asked a mentor (Ankil) for guidance on how to train on multiple GPUs simultaneously and he recommended Modal.com. You saved us Ankil :)
Accomplishments that we're proud of
What we learned
Tom's only prior experience with front end was in a high school programming class that taught HTML/CSS. Despite that, Tom learned React in a single day well enough to help develop the front end!
This was our first time using audio preprocessing with librosa to train an entire deep learning model from scratch, we had no idea if our project would work out or not but we are happy it did.
Although both Tom and I had used Colab and Jupyter Notebooks before, before this we never had to train a model large enough that it would take 10-11 hours to train on a single GPU, our final model had ~7.7 million parameters! Hence, both of us had to learn about cloud computing on the spot and switch between different cloud computing platforms on the fly to get around quota restrictions on GPUs. Following the advice of a mentor, we decided to use Modal.com to train our model with multiple GPUs simultaneously and we learned about Modal through its documentation on the spot.
What's next for TuneScribe
Our model performs very well on the training dataset, often predicting the exact note value for many bars in a row. However, due to our time constraints, we were unable to consider how we could prevent our model from overfitting to our dataset which is what ultimately ended up happening. Our model's precision on the validation dataset is 15% lower than our training dataset. Thus, our goal is to revamp our model with normalization and dropout to prevent this from occurring if we train again
The state of the art music transcription models in research has an average precision score of 80%, so we might consider a new model architecture entirely. We are looking into implementing complex-valued CNN/Transformers or the Neural Shuffle Exchange Network in the future.
We hope to expand our front end and backend so that it can be more like a full web service with login/registration, a database of soundtrack history, etc.




Log in or sign up for Devpost to join the conversation.