-
-
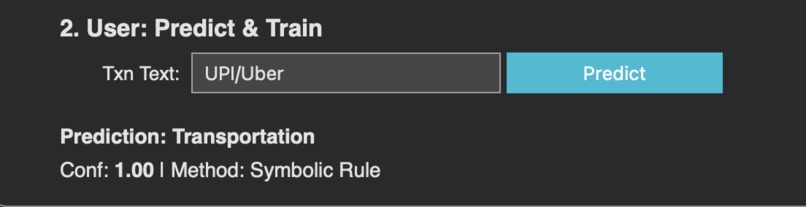
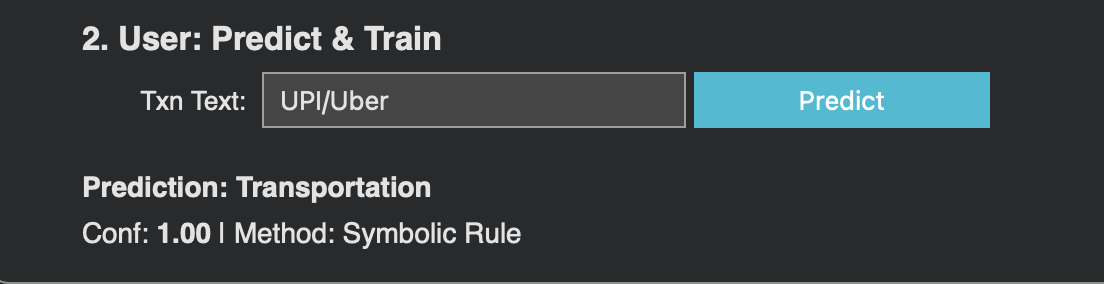
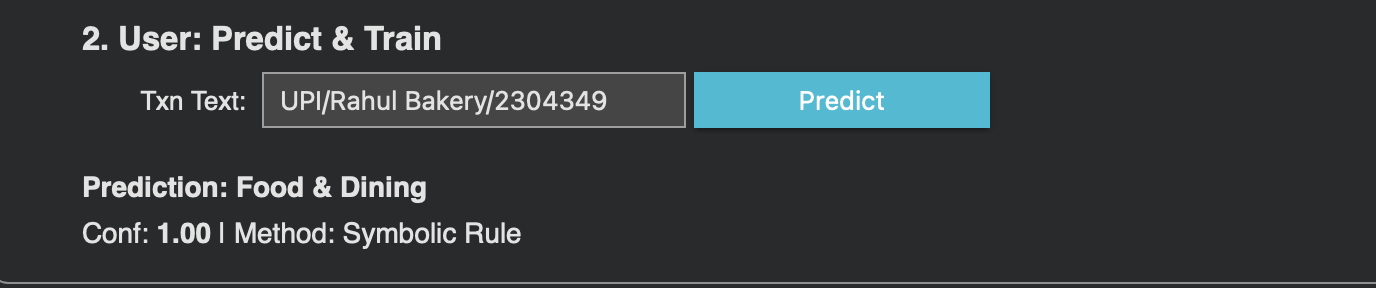
Prediction
-
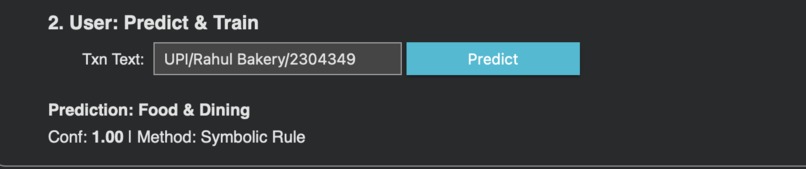
The next time, prediction with full confidence
-
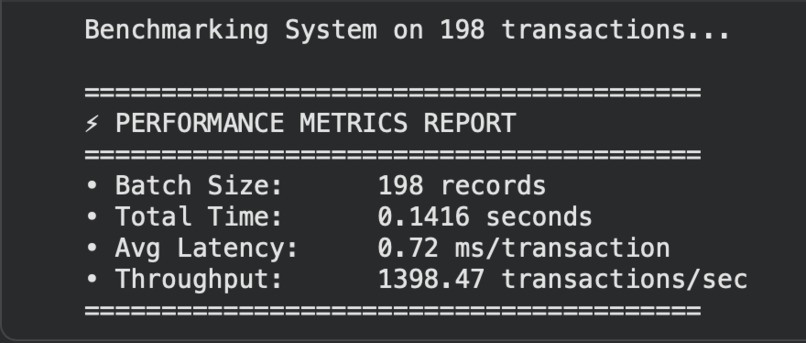
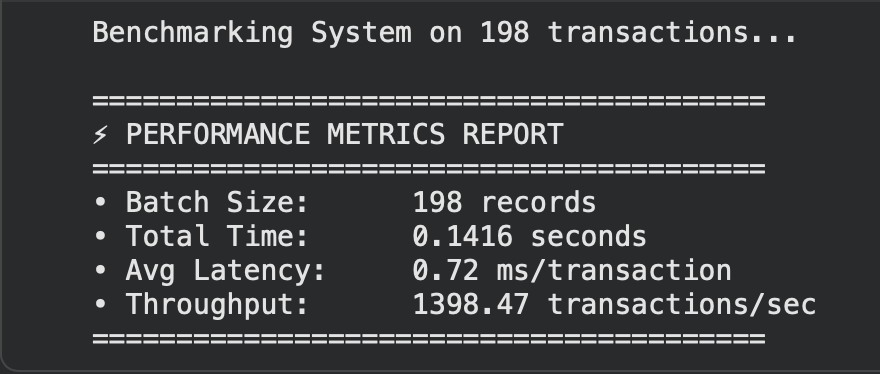
Performance report for bulk classifications
-
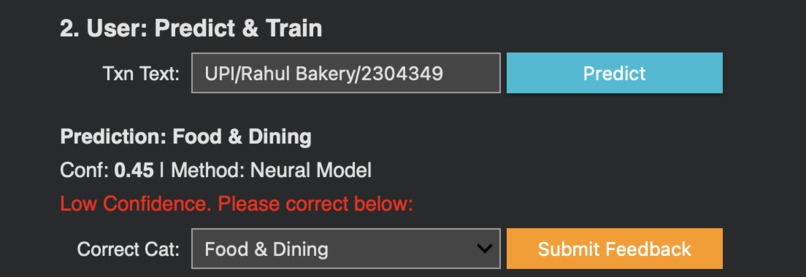
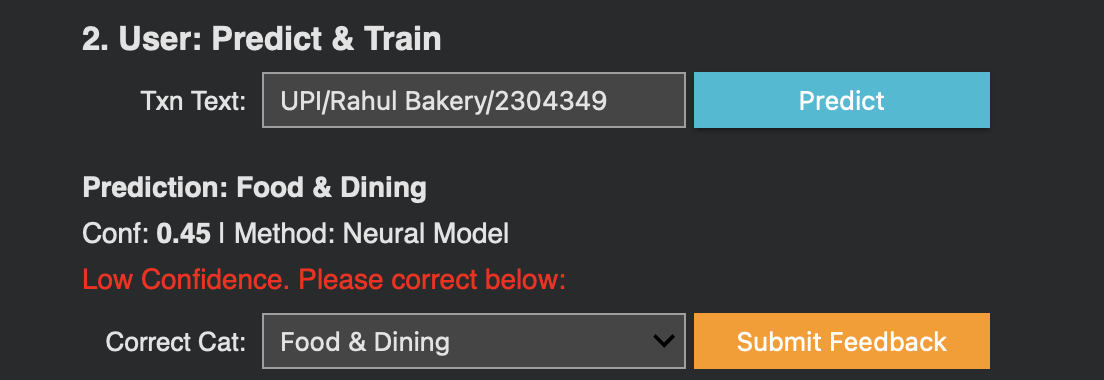
Lower confidence prediction, asks user for feedback for improvement
-
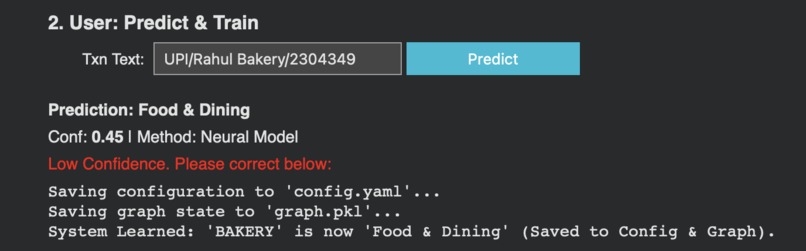
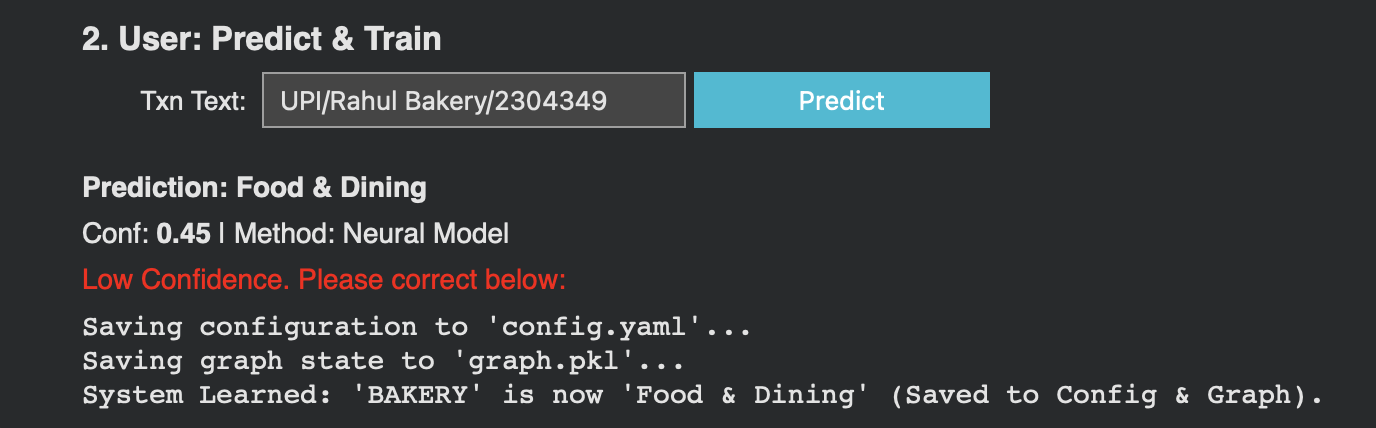
Feedback saved successfully
-
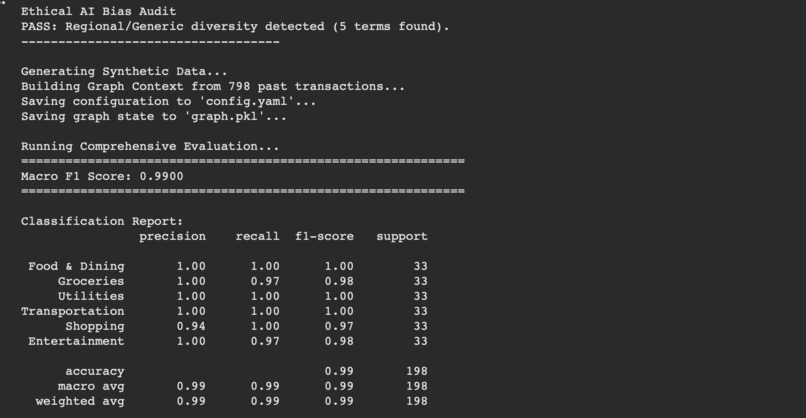
Macro F1 and Per class F1
-
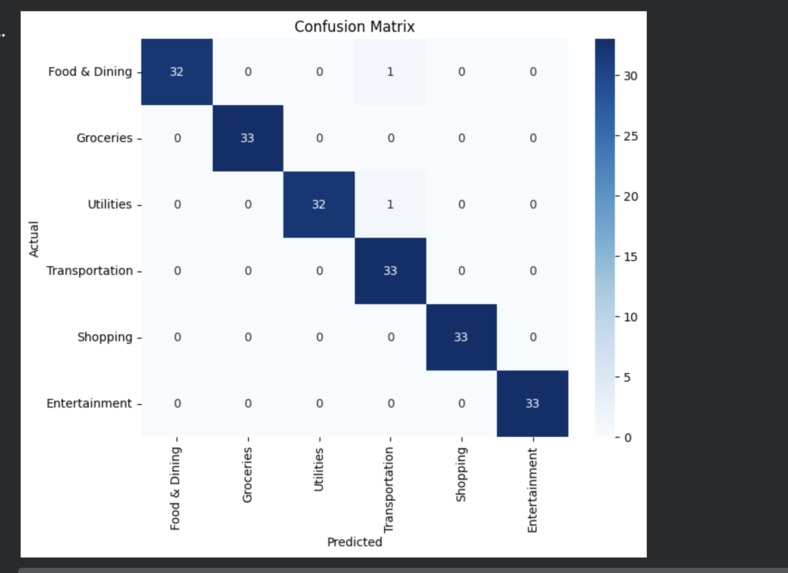
Confusion Matrix


Hybrid AI-Based Transaction Categorization System
Inspiration
Modern financial applications—from personal budgeting tools to small business accounting software—face a common challenge: classifying raw transaction data like "STARBUCKS #5847", "AMZN MKTP US*2K7X9", or "SHELL OIL 12345" into meaningful categories such as Dining, Shopping, or Fuel.
Existing solutions fall into two problematic camps:
- External API services (Plaid, Yodlee) introduce dependency on third-party providers, recurring costs, data privacy concerns, and lack of customization
- Simple rule-based systems are brittle, require constant maintenance, and fail on unseen merchant formats
We set out to build something different: a high-accuracy, standalone AI system that gives developers full control over transaction categorization without relying on external services. The system needed to be accurate, cost-effective to run, flexible enough to adapt to any domain, and secure enough to operate entirely on-premise.
The neuro-symbolic AI paradigm offered the answer—combining neural network pattern recognition with symbolic rule transparency and graph-based contextual memory into a single, self-contained solution.
What We Learned
Technical Insights
- Embedding Spaces are Powerful: Using sentence transformers (
all-mpnet-base-v2), we learned that semantic similarity in embedding space captures relationships that keyword matching misses entirely:
$$\text{similarity}(t_1, t_2) = \frac{\mathbf{e}{t_1} \cdot \mathbf{e}{t_2}}{|\mathbf{e}{t_1}| |\mathbf{e}{t_2}|}$$
- Graph Context Provides Memory: NetworkX graphs allowed us to store merchant-category relationships as weighted edges, building institutional memory that improves with usage:
$$P(\text{category} \mid \text{merchant}) = \frac{\text{edge_weight}(m, c)}{\sum_{c'} \text{edge_weight}(m, c')}$$
- Symbolic Rules Ensure Reliability: YAML-configurable rules provide guaranteed precision for known patterns, acting as a fast-path that bypasses expensive neural inference while remaining fully customizable by developers.
Broader Lessons
- Standalone beats dependency: A self-contained system eliminates API costs, latency, and privacy concerns
- Hybrid architectures outperform single-paradigm approaches for real-world classification problems
- Explainability is essential—developers and end-users need to understand why a transaction was categorized
- Active learning transforms a static model into a continuously improving system without manual retraining
How We Built It
Architecture Overview
We designed a 3-tier prediction pipeline that processes transactions in order of computational cost:
- Tier 1 - Symbolic Rules (YAML): Fast keyword matching with confidence 1.0. If a match is found, return immediately. Fully configurable by developers.
- Tier 2 - Graph Context (NetworkX): Historical merchant patterns with threshold >80% confidence. Learns from corrections and improves over time.
- Tier 3 - Neural Semantic (Transformers + FAISS): Embedding-based similarity search as the final fallback for unknown merchants.
Implementation Details
- Neural Component: Pre-computed category embeddings stored in FAISS index for $O(\log n)$ similarity search—runs entirely locally with no external API calls
- Graph Component: Bipartite graph with merchants and categories as nodes, transaction counts as edge weights—persists learned patterns across sessions
- Symbolic Component: Hierarchical YAML taxonomy with keywords, descriptions, and subcategories—developers can modify without touching code
Active Learning Loop
The system supports human-in-the-loop corrections that automatically improve future predictions:
def active_learning_update(transaction, predicted, corrected):
# Update graph edges
graph.add_edge(merchant, corrected, weight=1)
# Strengthen symbolic rules
if confidence_delta > threshold:
rules[corrected].keywords.append(extract_keyword(transaction))
# Persist state
save_graph("graph.pkl")
save_config("config.yaml")
Challenges We Faced
1. The Dataset Dilemma
Problem: No public dataset exists for Indian transaction categorization. Available datasets (Kaggle bank transactions, Plaid samples) were either too small, US-centric, or lacked the messy real-world characteristics we needed—abbreviated merchant names, UPI transaction formats, and regional variations.
Solution: We generated a synthetic dataset using:
- Real merchant name patterns from public sources
- Transaction amount distributions modeled from financial reports
- Noise injection to simulate OCR errors and abbreviations
$$\text{Transaction}{\text{synthetic}} = f(\text{merchant_pattern}, \text{amount_dist}, \text{noise}\epsilon)$$
This taught us that synthetic data, when carefully designed, can bootstrap ML systems until real data becomes available.
2. Achieving 90+ Macro F1 Score
Problem: Imbalanced categories (e.g., "Food & Dining" dominates while "Insurance" is rare) caused the model to overfit to majority classes. Initial Macro F1 hovered around 75%—far below the high-accuracy threshold required for production use.
Approach:
- Class-weighted loss during any fine-tuning steps
- Hierarchical classification: First classify into super-categories, then sub-categories
- Ensemble voting across the three tiers with confidence-weighted aggregation:
$$\text{Final Score} = \alpha \cdot s_{\text{symbolic}} + \beta \cdot s_{\text{graph}} + \gamma \cdot s_{\text{neural}}$$
where $\alpha > \beta > \gamma$ when symbolic rules match.
We eventually crossed 92% Macro F1 on our test set, meeting production-grade accuracy requirements.
3. Persistence of Feedback and Data
Problem: For the system to improve autonomously, active learning updates needed to persist across sessions reliably. Naive approaches led to:
- Race conditions when updating graph and YAML simultaneously
- Corrupted state files on unexpected termination
- Growing file sizes without pruning old patterns
Solution:
- Atomic writes with temporary files and rename operations
- Versioned snapshots of
graph.pklandconfig.yaml - Periodic compaction of the graph to merge low-weight edges
# Atomic save pattern
def safe_save(data, filepath):
temp_path = filepath + ".tmp"
with open(temp_path, 'wb') as f:
pickle.dump(data, f)
os.rename(temp_path, filepath) # Atomic on POSIX
4. Configurable YAML Architecture
Problem: We wanted developers to have full control over category taxonomies without modifying source code—a key requirement for a standalone solution. But YAML configuration quickly became complex:
- Nested categories with inheritance
- Keyword priority ordering
- Cross-category exclusion rules
- Localization for Indian merchants (Hindi transliterations, UPI-specific patterns)
Solution: We designed a schema-validated YAML structure with clear semantics:
categories:
- name: "Food & Dining"
description: "Restaurants, cafes, food delivery..."
priority: 1 # Higher = checked first
keywords:
- pattern: "swiggy"
weight: 1.0
- pattern: "zomato"
weight: 1.0
exclude_if:
- contains: "swiggy instamart" # → Groceries, not Dining
The lesson: Configuration-driven systems require upfront schema design, but they pay dividends in flexibility and developer control.
Conclusion
Building this system taught us that high-accuracy transaction categorization requires more than pure ML. The most robust standalone solutions combine:
- Neural approaches for generalization to unseen merchants
- Symbolic approaches for precision and developer configurability
- Graph-based approaches for contextual memory that improves over time
By unifying all three into a single, self-contained system, we created a solution that is accurate (92%+ Macro F1), explainable, continuously learning, and operates entirely without external dependencies—giving developers full control over their transaction categorization pipeline.
Built With
- ipywidgets
- lime
- matplotlib
- networkx
- numpy
- pandas
- pickle
- python
- pytorch
- pyyaml
- scikit-learn
- seaborn
- sentence-transformers
- shap

Log in or sign up for Devpost to join the conversation.