-
-

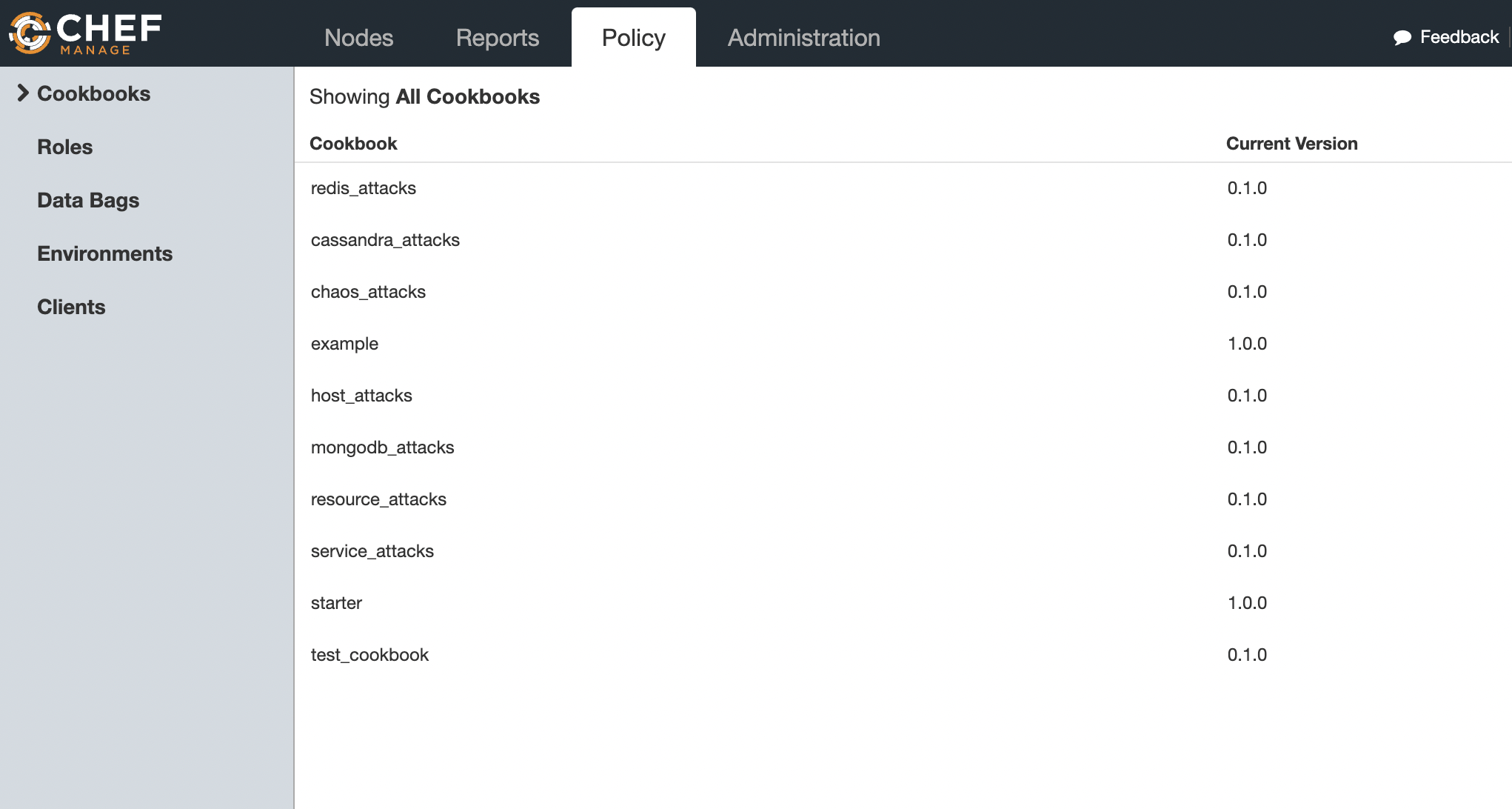
Recipes and Cookbooks
-
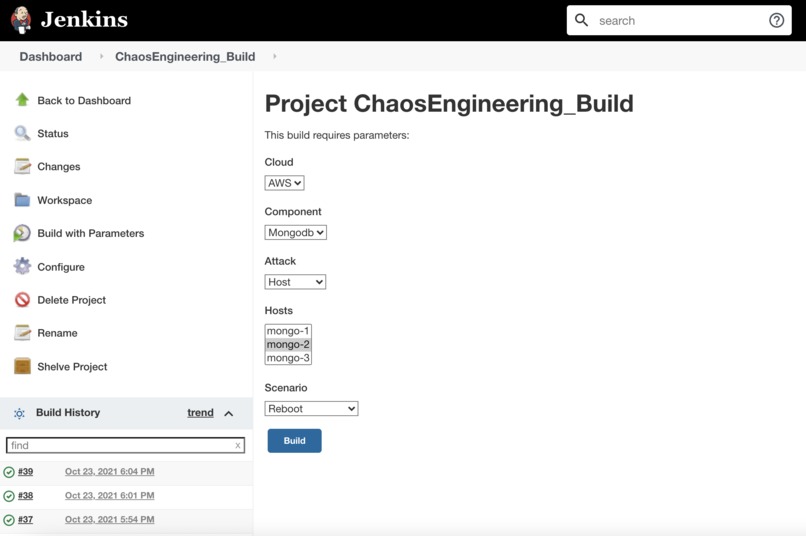
Jenkins Pipeline
-

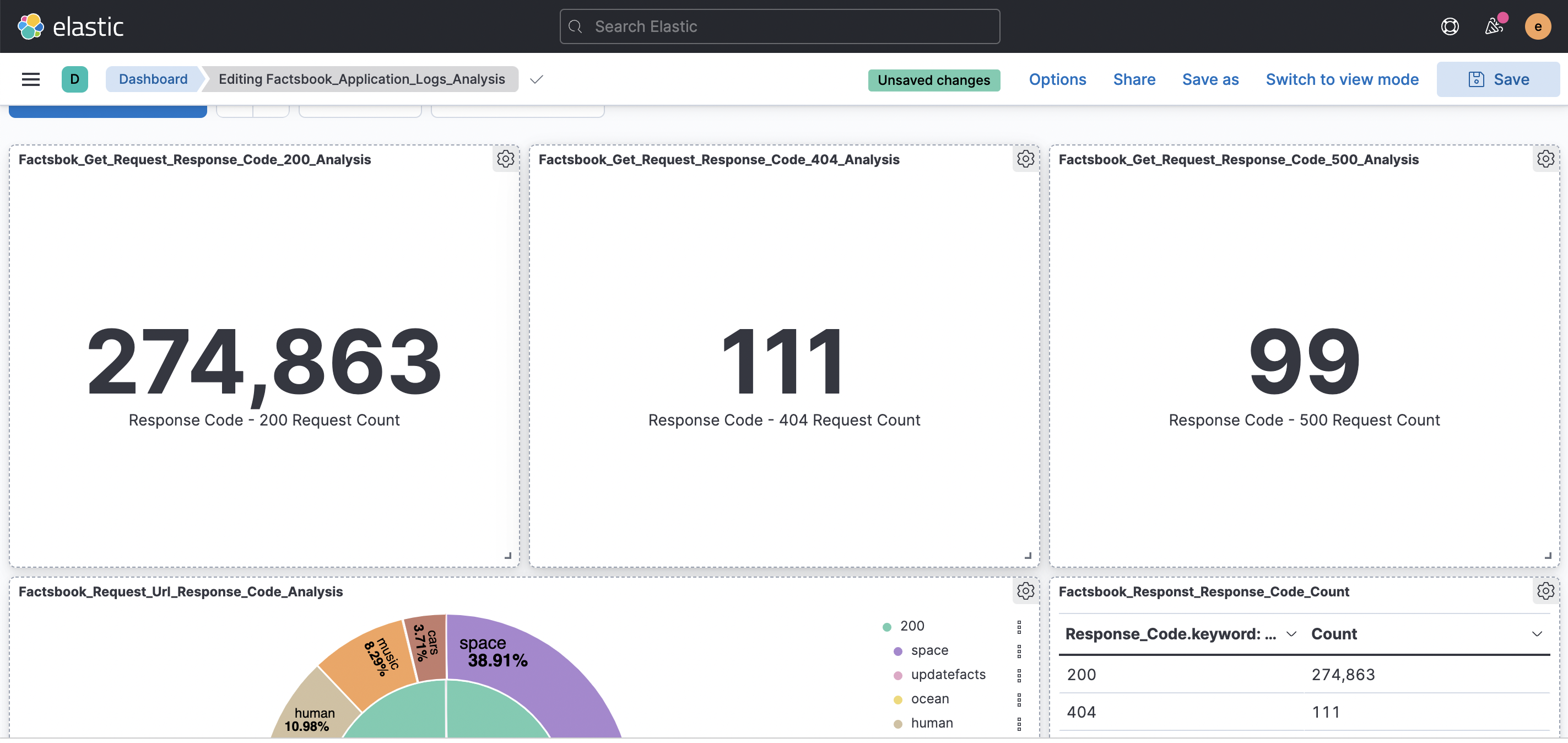
Attacks results on ELK - Web App
-
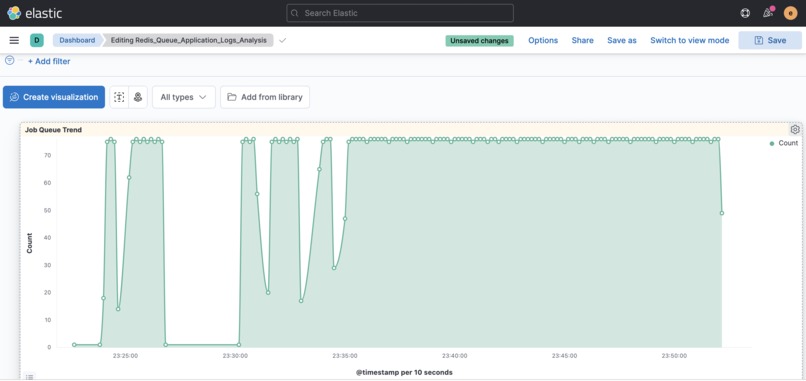
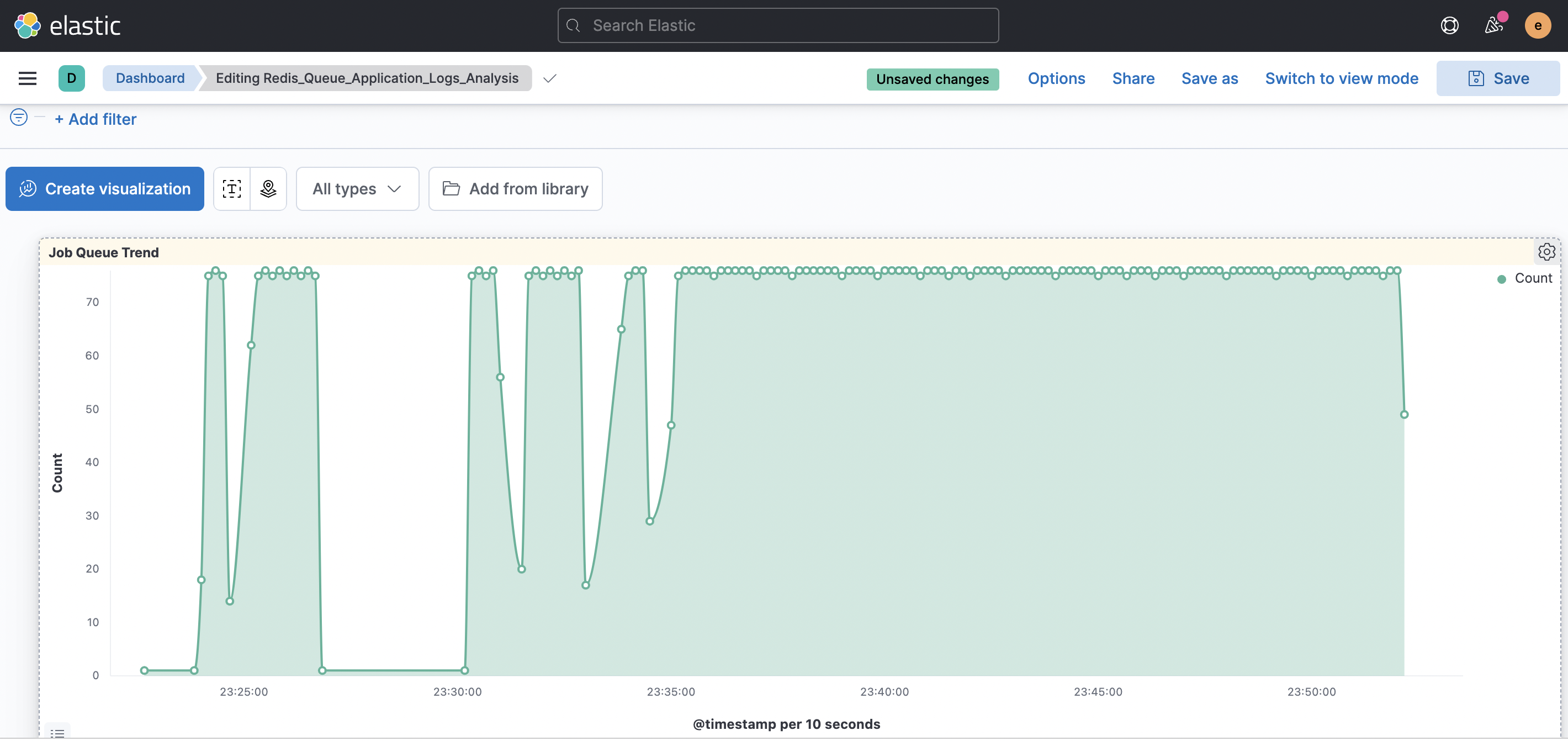
Attacks results on ELK - Redis with Docker
-
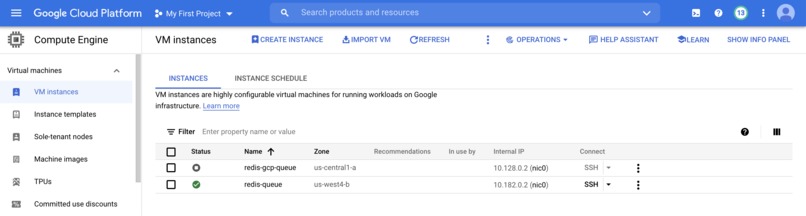
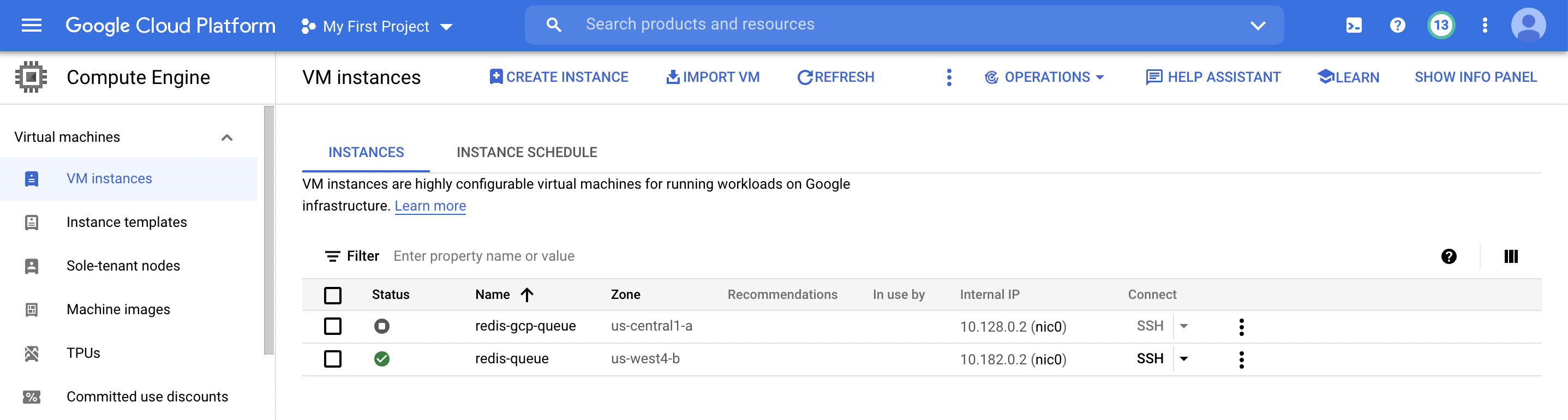
GCP target hosts
-
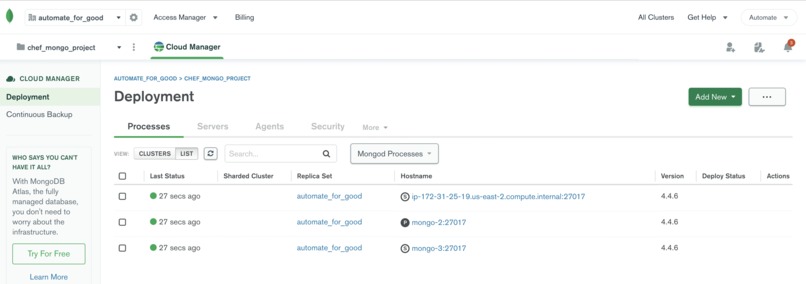
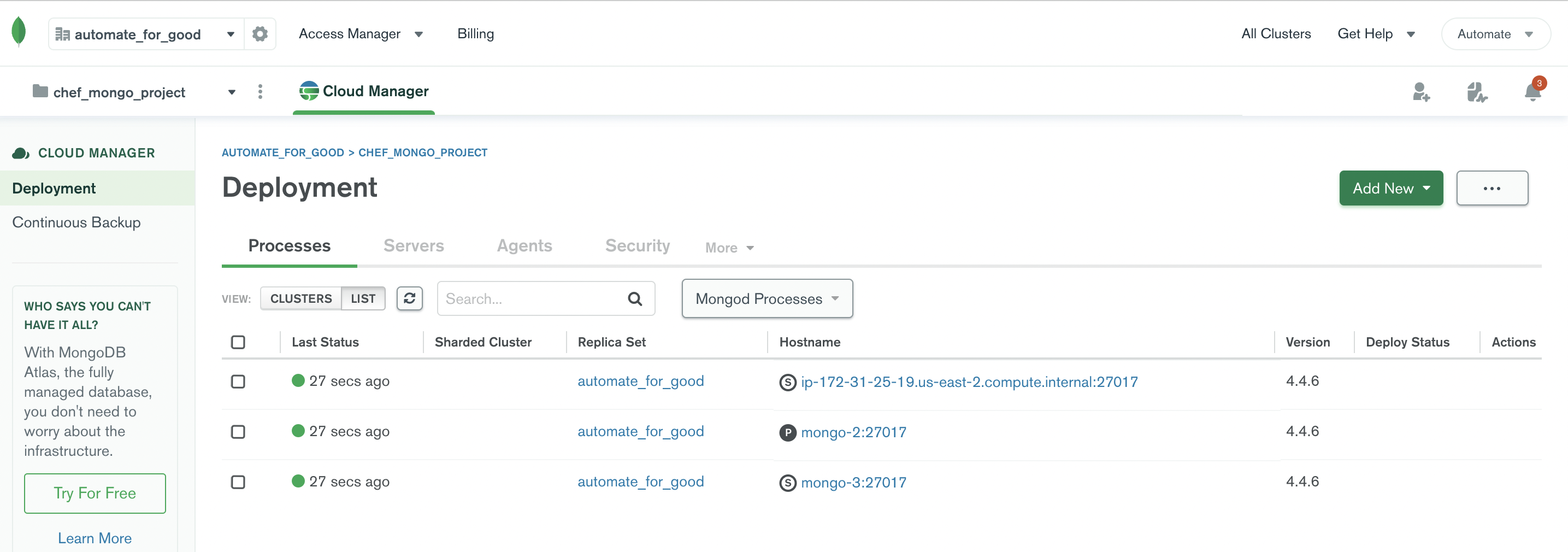
MongoDB Cloud Manager for DB hosted on EC2
-
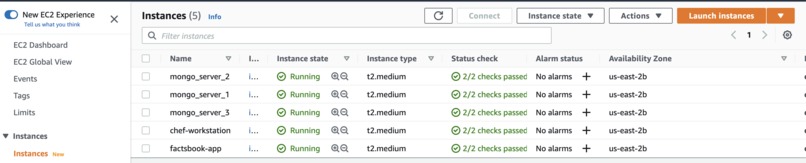
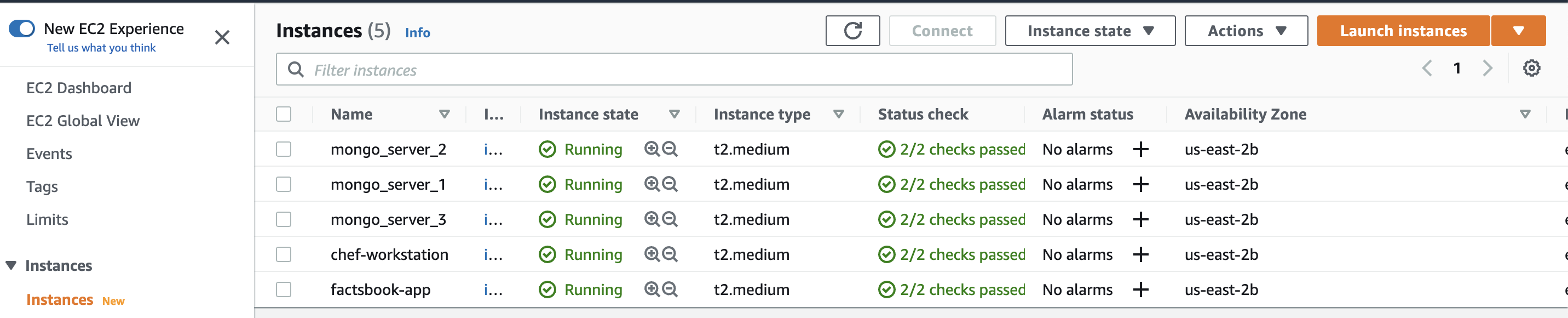
AWS Servers

Inspiration:
Failures happen in large distributed systems. We have seen recent worldwide outage of Facebook, Instagram, and WhatsApp. Fastly's outage happened mid this year and Google's outage at end of 2020. Failures happen!
But, can we identify these failures proactively? Chaos Engineering has been practiced widely to solve this problem. With Chef, we are automating the Chaos Engineering experiments that create turbulent attacks in your system to:
- Build confidence in your systems
- Uncover point of failures
- Detect failures proactively
What it does:
Our project - Automating for Failures, uses Chef Infra to automate the attacks on your system hosted on AWS, Google Cloud, or in your own infrastructure. These attacks generate several turbulent conditions in your system like:
- Rebooting servers
- Stoping services
- Killing running processes
- Blocking networks
- Simulating a failover in the database
- Using all of the server's CPU cores
How we built it:
Chaos Attacks Pipeline:
- Chef Workstation: Develop and test attacks
- Managed Chef server: Manage cookbooks, roles, policies, and nodes
- Chef nodes: Run chef-client to trigger attacks
Our target systems are:
Factsbook App: A web app that stores thousands of facts about space, ocean, music, humans, and cars.
- Tech Stack for Factsbook: React, Python, Flask & MongoDB - hosted on AWS
Job Scheduling App: Job queueing app that is used by microservices to produce and consume jobs.
- Tech Stack : Python, Flask, Redis & Docker - hosted on Github
Our DevOps Pipeline:
- Git/Github: Source code management and version control
- Jenkins: CI/DC pipeline
- ELK Stack: Logging and Metrics
- Slack: Build notifications
- MongoDB Cloud Manager: Manage MongoDB database running on AWS EC2.
Challenges we ran into:
- Onboarding hosts distributed on multi-cloud environments to our Chef pipeline.
- Healing of system when attack executions are completed.
Accomplishments that we're proud of
- Reducing Chaos engineering experiments time all of your system components from months to days.
- Designing Chef cookbooks and recipes to generate various types of attacks.
What we learned
- Chef Infra - Chef workstation, Chef server, and Chef client architecture.
- Designing recipes/cookbooks to interact with multi-cloud environments.
- Chef, Jenkins, and Slack pipeline.
What's next for Automating for Failures - Chaos Engineering with Chef
- Automating attack's test pipeline using Chef kitchen and Chef Inspec
- Create a dashboard for all summary of attacks and provide user-facing analytics
- Add more attacks for other system components like - Webserver, Cloud Services, CI/CD pipelines.
Built With
- amazon-web-services
- chef
- docker
- elasticsearch
- flask
- gcp
- github
- jenkins
- kibana
- logstash
- mongodb
- python
- react
- redis

Log in or sign up for Devpost to join the conversation.